 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTactileEval: A Step Towards Automated Fine-Grained Evaluation and Editing of Tactile Graphics
Apr 20, 2026Tactile graphics require careful expert validation before reaching blind and visually impaired (BVI) learners, yet existing datasets provide only coarse holistic quality ratings that offer no actionable repair signal. We present TactileEval, a three-stage pipeline that takes a first step toward automating this process. Drawing on expert free-text comments from the TactileNet dataset, we establish a five-category quality taxonomy; encompassing view angle, part completeness, background clutter, texture separation, and line quality aligned with BANA standards. We subsequently gathered 14,095 structured annotations via Amazon Mechanical Turk, spanning 66 object classes organized into six distinct families. A reproducible ViT-L/14 feature probe trained on this data achieves 85.70% overall test accuracy across 30 different tasks, with consistent difficulty ordering suggesting the taxonomy suggesting the taxonomy captures meaningful perceptual structure. Building on these evaluations, we present a ViT-guided automated editing pipeline that routes classifier scores through family-specific prompt templates to produce targeted corrections via gpt-image-1 image editing. Code, data, and models are available at https://TactileEval.github.io/
TactileNet: Bridging the Accessibility Gap with AI-Generated Tactile Graphics for Individuals with Vision Impairment
Apr 07, 2025Tactile graphics are essential for providing access to visual information for the 43 million people globally living with vision loss, as estimated by global prevalence data. However, traditional methods for creating these tactile graphics are labor-intensive and struggle to meet demand. We introduce TactileNet, the first comprehensive dataset and AI-driven framework for generating tactile graphics using text-to-image Stable Diffusion (SD) models. By integrating Low-Rank Adaptation (LoRA) and DreamBooth, our method fine-tunes SD models to produce high-fidelity, guideline-compliant tactile graphics while reducing computational costs. Evaluations involving tactile experts show that generated graphics achieve 92.86% adherence to tactile standards and 100% alignment with natural images in posture and features. Our framework also demonstrates scalability, generating 32,000 images (7,050 filtered for quality) across 66 classes, with prompt editing enabling customizable outputs (e.g., adding/removing details). Our work empowers designers to focus on refinement, significantly accelerating accessibility efforts. It underscores the transformative potential of AI for social good, offering a scalable solution to bridge the accessibility gap in education and beyond.
A Fault Prognostic System for the Turbine Guide Bearings of a Hydropower Plant Using Long-Short Term Memory (LSTM)
Jul 26, 2024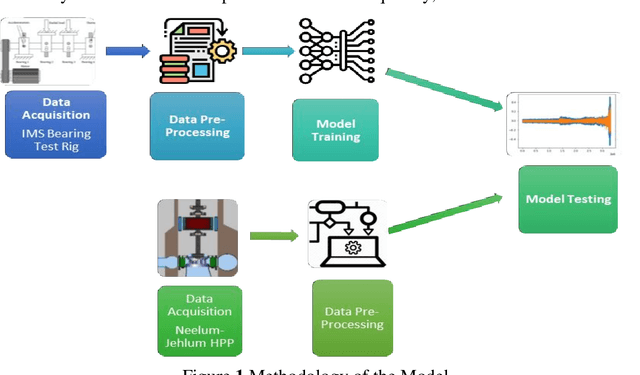
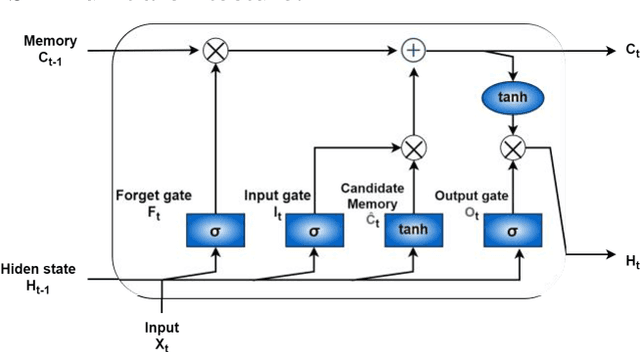
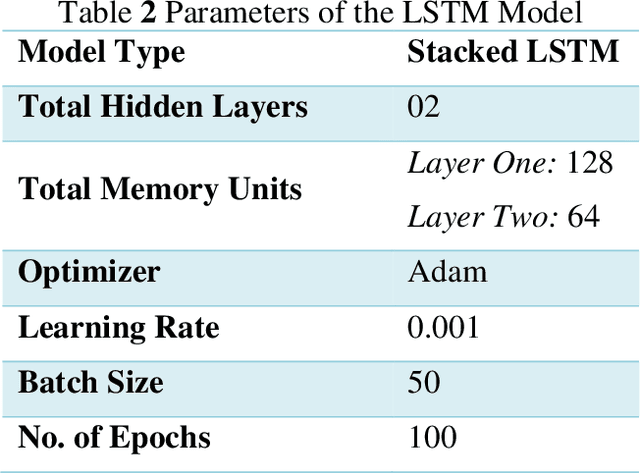
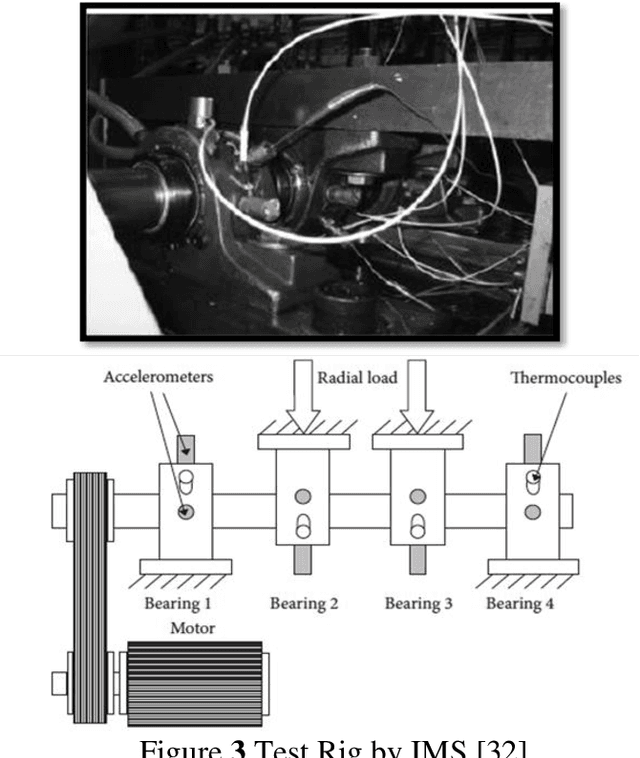
Hydroelectricity, being a renewable source of energy, globally fulfills the electricity demand. Hence, Hydropower Plants (HPPs) have always been in the limelight of research. The fast-paced technological advancement is enabling us to develop state-of-the-art power generation machines. This has not only resulted in improved turbine efficiency but has also increased the complexity of these systems. In lieu thereof, efficient Operation & Maintenance (O&M) of such intricate power generation systems has become a more challenging task. Therefore, there has been a shift from conventional reactive approaches to more intelligent predictive approaches in maintaining the HPPs. The research is therefore targeted to develop an artificially intelligent fault prognostics system for the turbine bearings of an HPP. The proposed method utilizes the Long Short-Term Memory (LSTM) algorithm in developing the model. Initially, the model is trained and tested with bearing vibration data from a test rig. Subsequently, it is further trained and tested with realistic bearing vibration data obtained from an HPP operating in Pakistan via the Supervisory Control and Data Acquisition (SCADA) system. The model demonstrates highly effective predictions of bearing vibration values, achieving a remarkably low RMSE.
MedPromptX: Grounded Multimodal Prompting for Chest X-ray Diagnosis
Mar 29, 2024Chest X-ray images are commonly used for predicting acute and chronic cardiopulmonary conditions, but efforts to integrate them with structured clinical data face challenges due to incomplete electronic health records (EHR). This paper introduces MedPromptX, the first model to integrate multimodal large language models (MLLMs), few-shot prompting (FP) and visual grounding (VG) to combine imagery with EHR data for chest X-ray diagnosis. A pre-trained MLLM is utilized to complement the missing EHR information, providing a comprehensive understanding of patients' medical history. Additionally, FP reduces the necessity for extensive training of MLLMs while effectively tackling the issue of hallucination. Nevertheless, the process of determining the optimal number of few-shot examples and selecting high-quality candidates can be burdensome, yet it profoundly influences model performance. Hence, we propose a new technique that dynamically refines few-shot data for real-time adjustment to new patient scenarios. Moreover, VG aids in focusing the model's attention on relevant regions of interest in X-ray images, enhancing the identification of abnormalities. We release MedPromptX-VQA, a new in-context visual question answering dataset encompassing interleaved image and EHR data derived from MIMIC-IV and MIMIC-CXR databases. Results demonstrate the SOTA performance of MedPromptX, achieving an 11% improvement in F1-score compared to the baselines. Code and data are available at https://github.com/BioMedIA-MBZUAI/MedPromptX
Fine-Tuned Large Language Models for Symptom Recognition from Spanish Clinical Text
Jan 28, 2024The accurate recognition of symptoms in clinical reports is significantly important in the fields of healthcare and biomedical natural language processing. These entities serve as essential building blocks for clinical information extraction, enabling retrieval of critical medical insights from vast amounts of textual data. Furthermore, the ability to identify and categorize these entities is fundamental for developing advanced clinical decision support systems, aiding healthcare professionals in diagnosis and treatment planning. In this study, we participated in SympTEMIST, a shared task on the detection of symptoms, signs and findings in Spanish medical documents. We combine a set of large language models fine-tuned with the data released by the organizers.
Improving Pseudo-labelling and Enhancing Robustness for Semi-Supervised Domain Generalization
Jan 25, 2024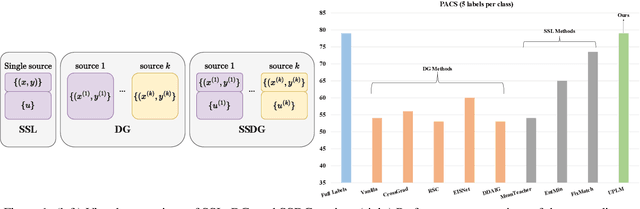
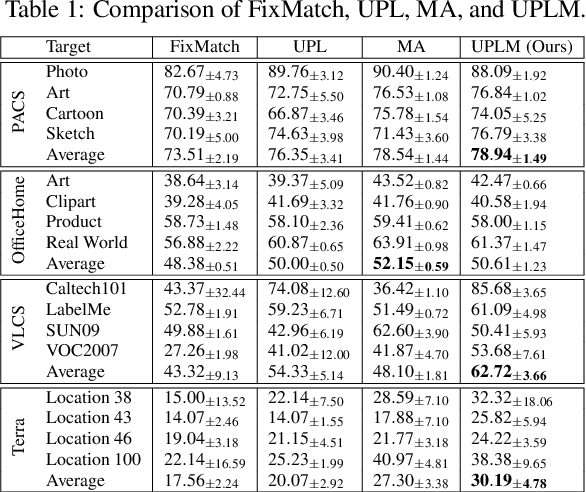
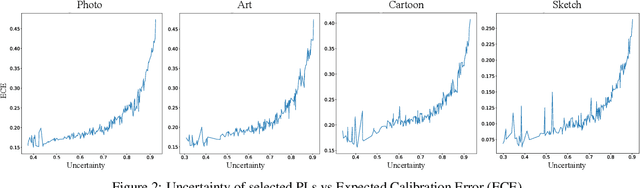
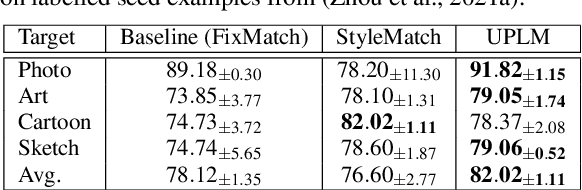
Beyond attaining domain generalization (DG), visual recognition models should also be data-efficient during learning by leveraging limited labels. We study the problem of Semi-Supervised Domain Generalization (SSDG) which is crucial for real-world applications like automated healthcare. SSDG requires learning a cross-domain generalizable model when the given training data is only partially labelled. Empirical investigations reveal that the DG methods tend to underperform in SSDG settings, likely because they are unable to exploit the unlabelled data. Semi-supervised learning (SSL) shows improved but still inferior results compared to fully-supervised learning. A key challenge, faced by the best-performing SSL-based SSDG methods, is selecting accurate pseudo-labels under multiple domain shifts and reducing overfitting to source domains under limited labels. In this work, we propose new SSDG approach, which utilizes a novel uncertainty-guided pseudo-labelling with model averaging (UPLM). Our uncertainty-guided pseudo-labelling (UPL) uses model uncertainty to improve pseudo-labelling selection, addressing poor model calibration under multi-source unlabelled data. The UPL technique, enhanced by our novel model averaging (MA) strategy, mitigates overfitting to source domains with limited labels. Extensive experiments on key representative DG datasets suggest that our method demonstrates effectiveness against existing methods. Our code and chosen labelled data seeds are available on GitHub: https://github.com/Adnan-Khan7/UPLM