 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTactileNet: Bridging the Accessibility Gap with AI-Generated Tactile Graphics for Individuals with Vision Impairment
Apr 07, 2025Tactile graphics are essential for providing access to visual information for the 43 million people globally living with vision loss, as estimated by global prevalence data. However, traditional methods for creating these tactile graphics are labor-intensive and struggle to meet demand. We introduce TactileNet, the first comprehensive dataset and AI-driven framework for generating tactile graphics using text-to-image Stable Diffusion (SD) models. By integrating Low-Rank Adaptation (LoRA) and DreamBooth, our method fine-tunes SD models to produce high-fidelity, guideline-compliant tactile graphics while reducing computational costs. Evaluations involving tactile experts show that generated graphics achieve 92.86% adherence to tactile standards and 100% alignment with natural images in posture and features. Our framework also demonstrates scalability, generating 32,000 images (7,050 filtered for quality) across 66 classes, with prompt editing enabling customizable outputs (e.g., adding/removing details). Our work empowers designers to focus on refinement, significantly accelerating accessibility efforts. It underscores the transformative potential of AI for social good, offering a scalable solution to bridge the accessibility gap in education and beyond.
A Step towards Automated and Generalizable Tactile Map Generation using Generative Adversarial Networks
Dec 10, 2024



Blindness and visual impairments affect many people worldwide. For help with navigation, people with visual impairments often rely on tactile maps that utilize raised surfaces and edges to convey information through touch. Although these maps are helpful, they are often not widely available and current tools to automate their production have similar limitations including only working at certain scales, for particular world regions, or adhering to specific tactile map standards. To address these shortcomings, we train a proof-of-concept model as a first step towards applying computer vision techniques to help automate the generation of tactile maps. We create a first-of-its-kind tactile maps dataset of street-views from Google Maps spanning 6500 locations and including different tactile line- and area-like features. Generative adversarial network (GAN) models trained on a single zoom successfully identify key map elements, remove extraneous ones, and perform inpainting with median F1 and intersection-over-union (IoU) scores of better than 0.97 across all features. Models trained on two zooms experience only minor drops in performance, and generalize well both to unseen map scales and world regions. Finally, we discuss future directions towards a full implementation of a tactile map solution that builds on our results.
Fine-Tuned Large Language Models for Symptom Recognition from Spanish Clinical Text
Jan 28, 2024The accurate recognition of symptoms in clinical reports is significantly important in the fields of healthcare and biomedical natural language processing. These entities serve as essential building blocks for clinical information extraction, enabling retrieval of critical medical insights from vast amounts of textual data. Furthermore, the ability to identify and categorize these entities is fundamental for developing advanced clinical decision support systems, aiding healthcare professionals in diagnosis and treatment planning. In this study, we participated in SympTEMIST, a shared task on the detection of symptoms, signs and findings in Spanish medical documents. We combine a set of large language models fine-tuned with the data released by the organizers.
On the Interpretability of Part-Prototype Based Classifiers: A Human Centric Analysis
Oct 10, 2023Part-prototype networks have recently become methods of interest as an interpretable alternative to many of the current black-box image classifiers. However, the interpretability of these methods from the perspective of human users has not been sufficiently explored. In this work, we have devised a framework for evaluating the interpretability of part-prototype-based models from a human perspective. The proposed framework consists of three actionable metrics and experiments. To demonstrate the usefulness of our framework, we performed an extensive set of experiments using Amazon Mechanical Turk. They not only show the capability of our framework in assessing the interpretability of various part-prototype-based models, but they also are, to the best of our knowledge, the most comprehensive work on evaluating such methods in a unified framework.
Vax-Culture: A Dataset for Studying Vaccine Discourse on Twitter
Apr 17, 2023



Vaccine hesitancy continues to be a main challenge for public health officials during the COVID-19 pandemic. As this hesitancy undermines vaccine campaigns, many researchers have sought to identify its root causes, finding that the increasing volume of anti-vaccine misinformation on social media platforms is a key element of this problem. We explored Twitter as a source of misleading content with the goal of extracting overlapping cultural and political beliefs that motivate the spread of vaccine misinformation. To do this, we have collected a data set of vaccine-related Tweets and annotated them with the help of a team of annotators with a background in communications and journalism. Ultimately we hope this can lead to effective and targeted public health communication strategies for reaching individuals with anti-vaccine beliefs. Moreover, this information helps with developing Machine Learning models to automatically detect vaccine misinformation posts and combat their negative impacts. In this paper, we present Vax-Culture, a novel Twitter COVID-19 dataset consisting of 6373 vaccine-related tweets accompanied by an extensive set of human-provided annotations including vaccine-hesitancy stance, indication of any misinformation in tweets, the entities criticized and supported in each tweet and the communicated message of each tweet. Moreover, we define five baseline tasks including four classification and one sequence generation tasks, and report the results of a set of recent transformer-based models for them. The dataset and code are publicly available at https://github.com/mrzarei5/Vax-Culture.
Toward Super-Resolution for Appearance-Based Gaze Estimation
Mar 17, 2023



Gaze tracking is a valuable tool with a broad range of applications in various fields, including medicine, psychology, virtual reality, marketing, and safety. Therefore, it is essential to have gaze tracking software that is cost-efficient and high-performing. Accurately predicting gaze remains a difficult task, particularly in real-world situations where images are affected by motion blur, video compression, and noise. Super-resolution has been shown to improve image quality from a visual perspective. This work examines the usefulness of super-resolution for improving appearance-based gaze tracking. We show that not all SR models preserve the gaze direction. We propose a two-step framework based on SwinIR super-resolution model. The proposed method consistently outperforms the state-of-the-art, particularly in scenarios involving low-resolution or degraded images. Furthermore, we examine the use of super-resolution through the lens of self-supervised learning for gaze prediction. Self-supervised learning aims to learn from unlabelled data to reduce the amount of required labeled data for downstream tasks. We propose a novel architecture called SuperVision by fusing an SR backbone network to a ResNet18 (with some skip connections). The proposed SuperVision method uses 5x less labeled data and yet outperforms, by 15%, the state-of-the-art method of GazeTR which uses 100% of training data.
Interpretable Few-shot Learning with Online Attribute Selection
Nov 16, 2022



Few-shot learning (FSL) is a challenging learning problem in which only a few samples are available for each class. Decision interpretation is more important in few-shot classification since there is a greater chance of error than in traditional classification. However, most of the previous FSL methods are black-box models. In this paper, we propose an inherently interpretable model for FSL based on human-friendly attributes. Moreover, we propose an online attribute selection mechanism that can effectively filter out irrelevant attributes in each episode. The attribute selection mechanism improves the accuracy and helps with interpretability by reducing the number of participated attributes in each episode. We demonstrate that the proposed method achieves results on par with black-box few-shot-learning models on four widely used datasets. To further close the performance gap with the black-box models, we propose a mechanism that trades interpretability for accuracy. It automatically detects the episodes where the provided human-friendly attributes are not adequate, and compensates by engaging learned unknown attributes.
Interpretable Concept-based Prototypical Networks for Few-Shot Learning
Feb 27, 2022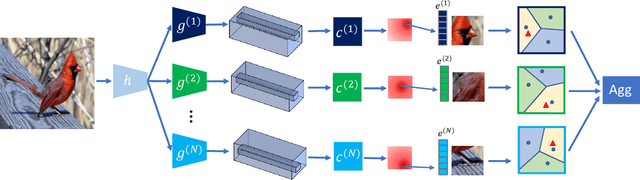
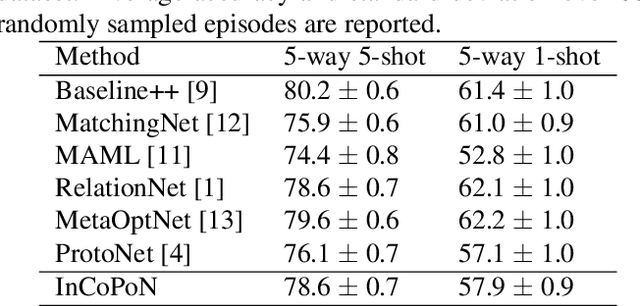

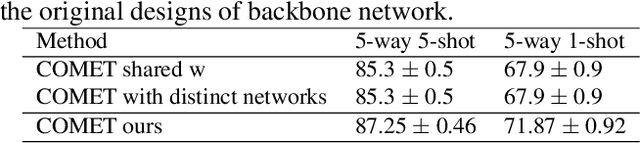
Few-shot learning aims at recognizing new instances from classes with limited samples. This challenging task is usually alleviated by performing meta-learning on similar tasks. However, the resulting models are black-boxes. There has been growing concerns about deploying black-box machine learning models and FSL is not an exception in this regard. In this paper, we propose a method for FSL based on a set of human-interpretable concepts. It constructs a set of metric spaces associated with the concepts and classifies samples of novel classes by aggregating concept-specific decisions. The proposed method does not require concept annotations for query samples. This interpretable method achieved results on a par with six previously state-of-the-art black-box FSL methods on the CUB fine-grained bird classification dataset.
Measuring Cognitive Status from Speech in a Smart Home Environment
Oct 18, 2021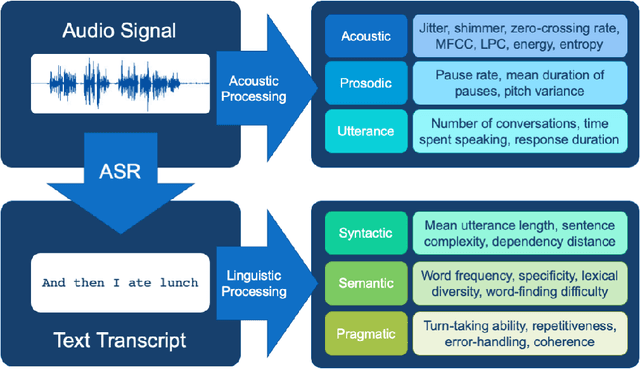
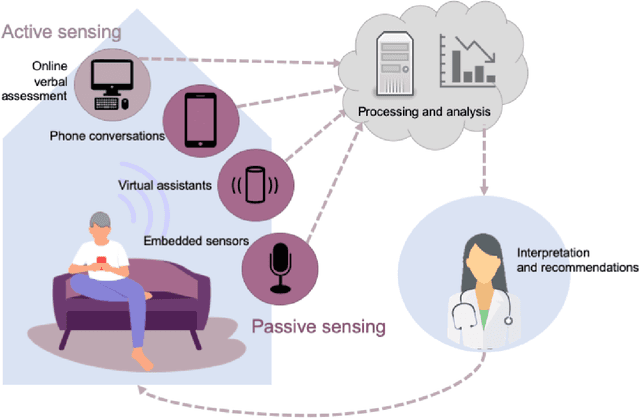
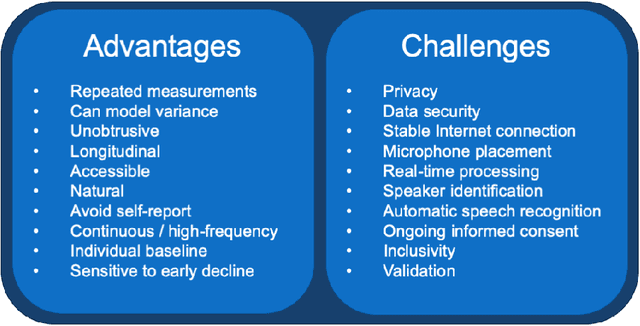
The population is aging, and becoming more tech-savvy. The United Nations predicts that by 2050, one in six people in the world will be over age 65 (up from one in 11 in 2019), and this increases to one in four in Europe and Northern America. Meanwhile, the proportion of American adults over 65 who own a smartphone has risen 24 percentage points from 2013-2017, and the majority have Internet in their homes. Smart devices and smart home technology have profound potential to transform how people age, their ability to live independently in later years, and their interactions with their circle of care. Cognitive health is a key component to independence and well-being in old age, and smart homes present many opportunities to measure cognitive status in a continuous, unobtrusive manner. In this article, we focus on speech as a measurement instrument for cognitive health. Existing methods of cognitive assessment suffer from a number of limitations that could be addressed through smart home speech sensing technologies. We begin with a brief tutorial on measuring cognitive status from speech, including some pointers to useful open-source software toolboxes for the interested reader. We then present an overview of the preliminary results from pilot studies on active and passive smart home speech sensing for the measurement of cognitive health, and conclude with some recommendations and challenge statements for the next wave of work in this area, to help overcome both technical and ethical barriers to success.
Feature-Based Interpretable Reinforcement Learning based on State-Transition Models
May 14, 2021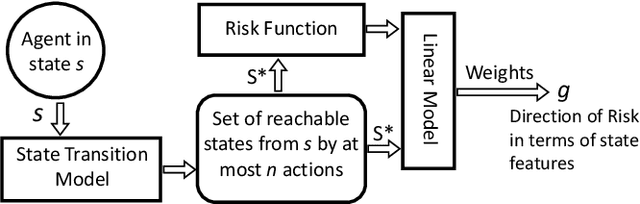
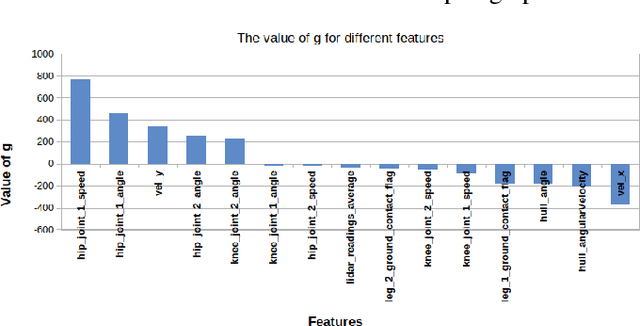
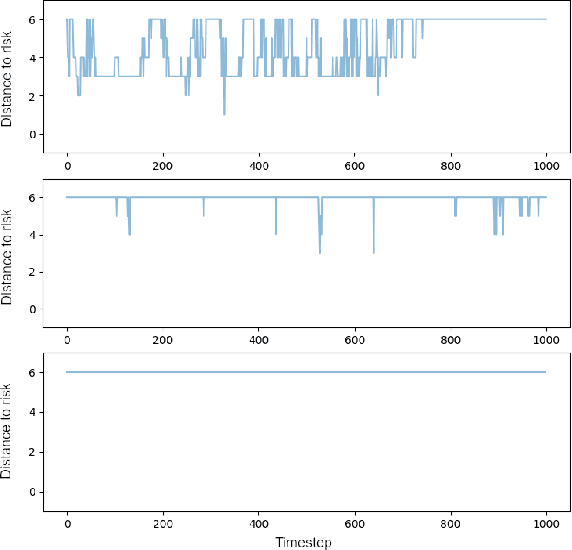
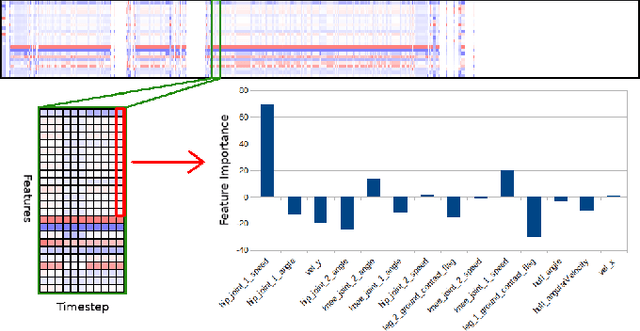
Growing concerns regarding the operational usage of AI models in the real-world has caused a surge of interest in explaining AI models' decisions to humans. Reinforcement Learning is not an exception in this regard. In this work, we propose a method for offering local explanations on risk in reinforcement learning. Our method only requires a log of previous interactions between the agent and the environment to create a state-transition model. It is designed to work on RL environments with either continuous or discrete state and action spaces. After creating the model, actions of any agent can be explained in terms of the features most influential in increasing or decreasing risk or any other desirable objective function in the locality of the agent. Through experiments, we demonstrate the effectiveness of the proposed method in providing such explanations.