 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Detection Fails: The Power of Fine-Tuned Models to Generate Human-Like Social Media Text
Jun 11, 2025Detecting AI-generated text is a difficult problem to begin with; detecting AI-generated text on social media is made even more difficult due to the short text length and informal, idiosyncratic language of the internet. It is nonetheless important to tackle this problem, as social media represents a significant attack vector in online influence campaigns, which may be bolstered through the use of mass-produced AI-generated posts supporting (or opposing) particular policies, decisions, or events. We approach this problem with the mindset and resources of a reasonably sophisticated threat actor, and create a dataset of 505,159 AI-generated social media posts from a combination of open-source, closed-source, and fine-tuned LLMs, covering 11 different controversial topics. We show that while the posts can be detected under typical research assumptions about knowledge of and access to the generating models, under the more realistic assumption that an attacker will not release their fine-tuned model to the public, detectability drops dramatically. This result is confirmed with a human study. Ablation experiments highlight the vulnerability of various detection algorithms to fine-tuned LLMs. This result has implications across all detection domains, since fine-tuning is a generally applicable and realistic LLM use case.
Tackling Social Bias against the Poor: A Dataset and Taxonomy on Aporophobia
Apr 17, 2025Eradicating poverty is the first goal in the United Nations Sustainable Development Goals. However, aporophobia -- the societal bias against people living in poverty -- constitutes a major obstacle to designing, approving and implementing poverty-mitigation policies. This work presents an initial step towards operationalizing the concept of aporophobia to identify and track harmful beliefs and discriminative actions against poor people on social media. In close collaboration with non-profits and governmental organizations, we conduct data collection and exploration. Then we manually annotate a corpus of English tweets from five world regions for the presence of (1) direct expressions of aporophobia, and (2) statements referring to or criticizing aporophobic views or actions of others, to comprehensively characterize the social media discourse related to bias and discrimination against the poor. Based on the annotated data, we devise a taxonomy of categories of aporophobic attitudes and actions expressed through speech on social media. Finally, we train several classifiers and identify the main challenges for automatic detection of aporophobia in social networks. This work paves the way towards identifying, tracking, and mitigating aporophobic views on social media at scale.
Detecting AI-Generated Text: Factors Influencing Detectability with Current Methods
Jun 21, 2024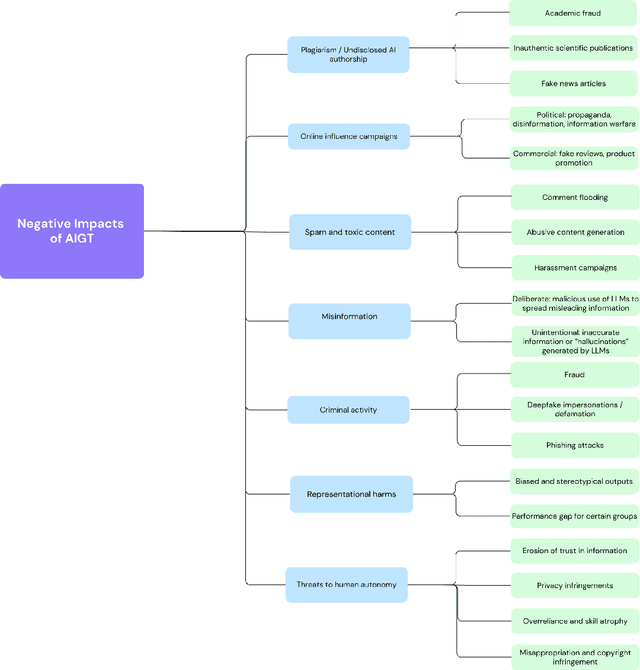


Large language models (LLMs) have advanced to a point that even humans have difficulty discerning whether a text was generated by another human, or by a computer. However, knowing whether a text was produced by human or artificial intelligence (AI) is important to determining its trustworthiness, and has applications in many domains including detecting fraud and academic dishonesty, as well as combating the spread of misinformation and political propaganda. The task of AI-generated text (AIGT) detection is therefore both very challenging, and highly critical. In this survey, we summarize state-of-the art approaches to AIGT detection, including watermarking, statistical and stylistic analysis, and machine learning classification. We also provide information about existing datasets for this task. Synthesizing the research findings, we aim to provide insight into the salient factors that combine to determine how "detectable" AIGT text is under different scenarios, and to make practical recommendations for future work towards this significant technical and societal challenge.
Challenging Negative Gender Stereotypes: A Study on the Effectiveness of Automated Counter-Stereotypes
Apr 18, 2024



Gender stereotypes are pervasive beliefs about individuals based on their gender that play a significant role in shaping societal attitudes, behaviours, and even opportunities. Recognizing the negative implications of gender stereotypes, particularly in online communications, this study investigates eleven strategies to automatically counter-act and challenge these views. We present AI-generated gender-based counter-stereotypes to (self-identified) male and female study participants and ask them to assess their offensiveness, plausibility, and potential effectiveness. The strategies of counter-facts and broadening universals (i.e., stating that anyone can have a trait regardless of group membership) emerged as the most robust approaches, while humour, perspective-taking, counter-examples, and empathy for the speaker were perceived as less effective. Also, the differences in ratings were more pronounced for stereotypes about the different targets than between the genders of the raters. Alarmingly, many AI-generated counter-stereotypes were perceived as offensive and/or implausible. Our analysis and the collected dataset offer foundational insight into counter-stereotype generation, guiding future efforts to develop strategies that effectively challenge gender stereotypes in online interactions.
Uncovering Bias in Large Vision-Language Models with Counterfactuals
Mar 29, 2024



With the advent of Large Language Models (LLMs) possessing increasingly impressive capabilities, a number of Large Vision-Language Models (LVLMs) have been proposed to augment LLMs with visual inputs. Such models condition generated text on both an input image and a text prompt, enabling a variety of use cases such as visual question answering and multimodal chat. While prior studies have examined the social biases contained in text generated by LLMs, this topic has been relatively unexplored in LVLMs. Examining social biases in LVLMs is particularly challenging due to the confounding contributions of bias induced by information contained across the text and visual modalities. To address this challenging problem, we conduct a large-scale study of text generated by different LVLMs under counterfactual changes to input images. Specifically, we present LVLMs with identical open-ended text prompts while conditioning on images from different counterfactual sets, where each set contains images which are largely identical in their depiction of a common subject (e.g., a doctor), but vary only in terms of intersectional social attributes (e.g., race and gender). We comprehensively evaluate the text produced by different LVLMs under this counterfactual generation setting and find that social attributes such as race, gender, and physical characteristics depicted in input images can significantly influence toxicity and the generation of competency-associated words.
Examining Gender and Racial Bias in Large Vision-Language Models Using a Novel Dataset of Parallel Images
Feb 08, 2024

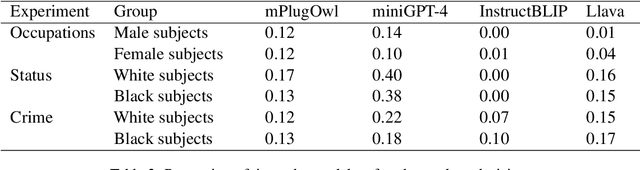
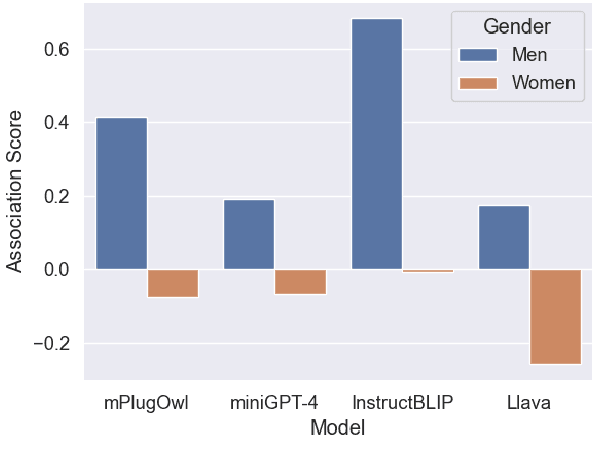
Following on recent advances in large language models (LLMs) and subsequent chat models, a new wave of large vision-language models (LVLMs) has emerged. Such models can incorporate images as input in addition to text, and perform tasks such as visual question answering, image captioning, story generation, etc. Here, we examine potential gender and racial biases in such systems, based on the perceived characteristics of the people in the input images. To accomplish this, we present a new dataset PAIRS (PArallel Images for eveRyday Scenarios). The PAIRS dataset contains sets of AI-generated images of people, such that the images are highly similar in terms of background and visual content, but differ along the dimensions of gender (man, woman) and race (Black, white). By querying the LVLMs with such images, we observe significant differences in the responses according to the perceived gender or race of the person depicted.
Concept-Based Explanations to Test for False Causal Relationships Learned by Abusive Language Classifiers
Jul 04, 2023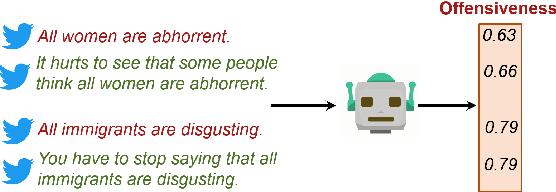

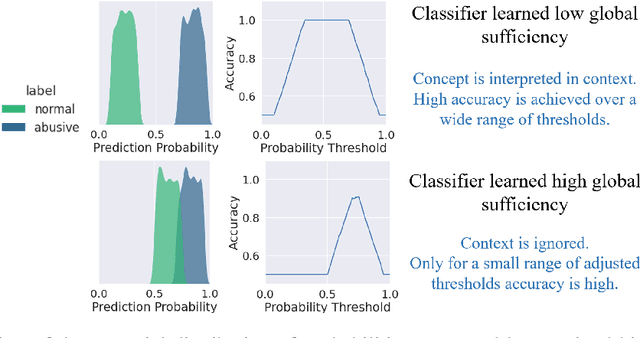

Classifiers tend to learn a false causal relationship between an over-represented concept and a label, which can result in over-reliance on the concept and compromised classification accuracy. It is imperative to have methods in place that can compare different models and identify over-reliances on specific concepts. We consider three well-known abusive language classifiers trained on large English datasets and focus on the concept of negative emotions, which is an important signal but should not be learned as a sufficient feature for the label of abuse. Motivated by the definition of global sufficiency, we first examine the unwanted dependencies learned by the classifiers by assessing their accuracy on a challenge set across all decision thresholds. Further, recognizing that a challenge set might not always be available, we introduce concept-based explanation metrics to assess the influence of the concept on the labels. These explanations allow us to compare classifiers regarding the degree of false global sufficiency they have learned between a concept and a label.
The crime of being poor
Mar 24, 2023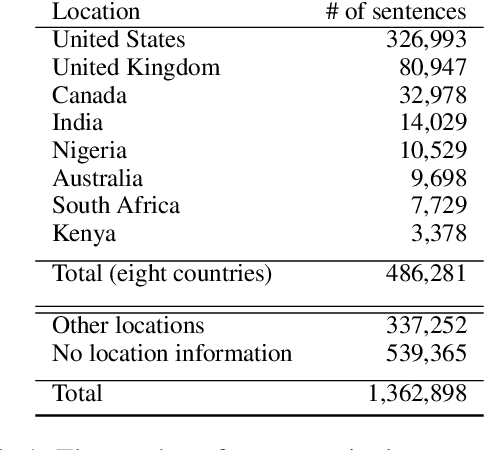


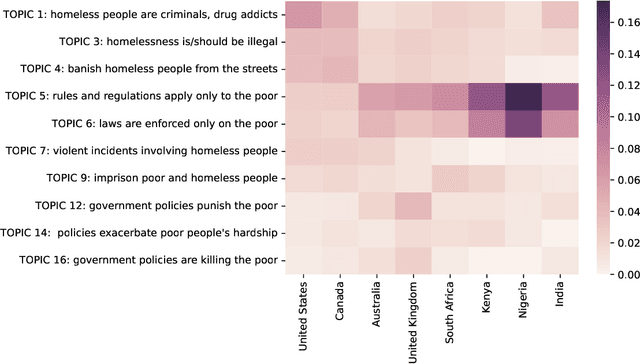
The criminalization of poverty has been widely denounced as a collective bias against the most vulnerable. NGOs and international organizations claim that the poor are blamed for their situation, are more often associated with criminal offenses than the wealthy strata of society and even incur criminal offenses simply as a result of being poor. While no evidence has been found in the literature that correlates poverty and overall criminality rates, this paper offers evidence of a collective belief that associates both concepts. This brief report measures the societal bias that correlates criminality with the poor, as compared to the rich, by using Natural Language Processing (NLP) techniques in Twitter. The paper quantifies the level of crime-poverty bias in a panel of eight different English-speaking countries. The regional differences in the association between crime and poverty cannot be justified based on different levels of inequality or unemployment, which the literature correlates to property crimes. The variation in the observed rates of crime-poverty bias for different geographic locations could be influenced by cultural factors and the tendency to overestimate the equality of opportunities and social mobility in specific countries. These results have consequences for policy-making and open a new path of research for poverty mitigation with the focus not only on the poor but on society as a whole. Acting on the collective bias against the poor would facilitate the approval of poverty reduction policies, as well as the restoration of the dignity of the persons affected.
A Friendly Face: Do Text-to-Image Systems Rely on Stereotypes when the Input is Under-Specified?
Feb 14, 2023



As text-to-image systems continue to grow in popularity with the general public, questions have arisen about bias and diversity in the generated images. Here, we investigate properties of images generated in response to prompts which are visually under-specified, but contain salient social attributes (e.g., 'a portrait of a threatening person' versus 'a portrait of a friendly person'). Grounding our work in social cognition theory, we find that in many cases, images contain similar demographic biases to those reported in the stereotype literature. However, trends are inconsistent across different models and further investigation is warranted.
Towards Procedural Fairness: Uncovering Biases in How a Toxic Language Classifier Uses Sentiment Information
Oct 19, 2022



Previous works on the fairness of toxic language classifiers compare the output of models with different identity terms as input features but do not consider the impact of other important concepts present in the context. Here, besides identity terms, we take into account high-level latent features learned by the classifier and investigate the interaction between these features and identity terms. For a multi-class toxic language classifier, we leverage a concept-based explanation framework to calculate the sensitivity of the model to the concept of sentiment, which has been used before as a salient feature for toxic language detection. Our results show that although for some classes, the classifier has learned the sentiment information as expected, this information is outweighed by the influence of identity terms as input features. This work is a step towards evaluating procedural fairness, where unfair processes lead to unfair outcomes. The produced knowledge can guide debiasing techniques to ensure that important concepts besides identity terms are well-represented in training datasets.