 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGender-Neutral Machine Translation Strategies in Practice
Jun 18, 2025Gender-inclusive machine translation (MT) should preserve gender ambiguity in the source to avoid misgendering and representational harms. While gender ambiguity often occurs naturally in notional gender languages such as English, maintaining that gender neutrality in grammatical gender languages is a challenge. Here we assess the sensitivity of 21 MT systems to the need for gender neutrality in response to gender ambiguity in three translation directions of varying difficulty. The specific gender-neutral strategies that are observed in practice are categorized and discussed. Additionally, we examine the effect of binary gender stereotypes on the use of gender-neutral translation. In general, we report a disappointing absence of gender-neutral translations in response to gender ambiguity. However, we observe a small handful of MT systems that switch to gender neutral translation using specific strategies, depending on the target language.
When Detection Fails: The Power of Fine-Tuned Models to Generate Human-Like Social Media Text
Jun 11, 2025Detecting AI-generated text is a difficult problem to begin with; detecting AI-generated text on social media is made even more difficult due to the short text length and informal, idiosyncratic language of the internet. It is nonetheless important to tackle this problem, as social media represents a significant attack vector in online influence campaigns, which may be bolstered through the use of mass-produced AI-generated posts supporting (or opposing) particular policies, decisions, or events. We approach this problem with the mindset and resources of a reasonably sophisticated threat actor, and create a dataset of 505,159 AI-generated social media posts from a combination of open-source, closed-source, and fine-tuned LLMs, covering 11 different controversial topics. We show that while the posts can be detected under typical research assumptions about knowledge of and access to the generating models, under the more realistic assumption that an attacker will not release their fine-tuned model to the public, detectability drops dramatically. This result is confirmed with a human study. Ablation experiments highlight the vulnerability of various detection algorithms to fine-tuned LLMs. This result has implications across all detection domains, since fine-tuning is a generally applicable and realistic LLM use case.
WMT24 Test Suite: Gender Resolution in Speaker-Listener Dialogue Roles
Nov 09, 2024We assess the difficulty of gender resolution in literary-style dialogue settings and the influence of gender stereotypes. Instances of the test suite contain spoken dialogue interleaved with external meta-context about the characters and the manner of speaking. We find that character and manner stereotypes outside of the dialogue significantly impact the gender agreement of referents within the dialogue.
Detecting AI-Generated Text: Factors Influencing Detectability with Current Methods
Jun 21, 2024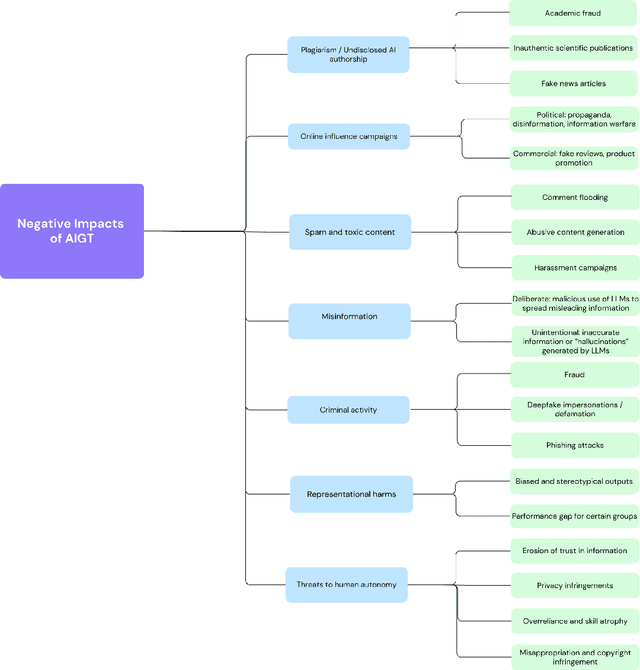
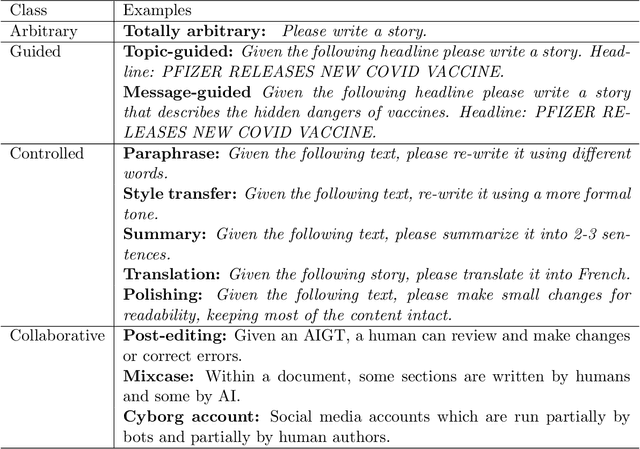


Large language models (LLMs) have advanced to a point that even humans have difficulty discerning whether a text was generated by another human, or by a computer. However, knowing whether a text was produced by human or artificial intelligence (AI) is important to determining its trustworthiness, and has applications in many domains including detecting fraud and academic dishonesty, as well as combating the spread of misinformation and political propaganda. The task of AI-generated text (AIGT) detection is therefore both very challenging, and highly critical. In this survey, we summarize state-of-the art approaches to AIGT detection, including watermarking, statistical and stylistic analysis, and machine learning classification. We also provide information about existing datasets for this task. Synthesizing the research findings, we aim to provide insight into the salient factors that combine to determine how "detectable" AIGT text is under different scenarios, and to make practical recommendations for future work towards this significant technical and societal challenge.
Projective Methods for Mitigating Gender Bias in Pre-trained Language Models
Mar 27, 2024Mitigation of gender bias in NLP has a long history tied to debiasing static word embeddings. More recently, attention has shifted to debiasing pre-trained language models. We study to what extent the simplest projective debiasing methods, developed for word embeddings, can help when applied to BERT's internal representations. Projective methods are fast to implement, use a small number of saved parameters, and make no updates to the existing model parameters. We evaluate the efficacy of the methods in reducing both intrinsic bias, as measured by BERT's next sentence prediction task, and in mitigating observed bias in a downstream setting when fine-tuned. To this end, we also provide a critical analysis of a popular gender-bias assessment test for quantifying intrinsic bias, resulting in an enhanced test set and new bias measures. We find that projective methods can be effective at both intrinsic bias and downstream bias mitigation, but that the two outcomes are not necessarily correlated. This finding serves as a warning that intrinsic bias test sets, based either on language modeling tasks or next sentence prediction, should not be the only benchmark in developing a debiased language model.
Second Order WinoBias Test Set for Latent Gender Bias Detection in Coreference Resolution
Sep 28, 2021

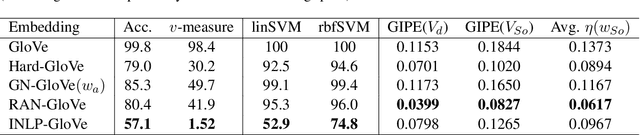

We observe an instance of gender-induced bias in a downstream application, despite the absence of explicit gender words in the test cases. We provide a test set, SoWinoBias, for the purpose of measuring such latent gender bias in coreference resolution systems. We evaluate the performance of current debiasing methods on the SoWinoBias test set, especially in reference to the method's design and altered embedding space properties. See https://github.com/hillarydawkins/SoWinoBias.
* 7+2 pages. Published in the proceedings of the 3rd Workshop on Gender Bias in Natural Language Processing (co-located with ACL-IJCNLP 2021)
Marked Attribute Bias in Natural Language Inference
Sep 28, 2021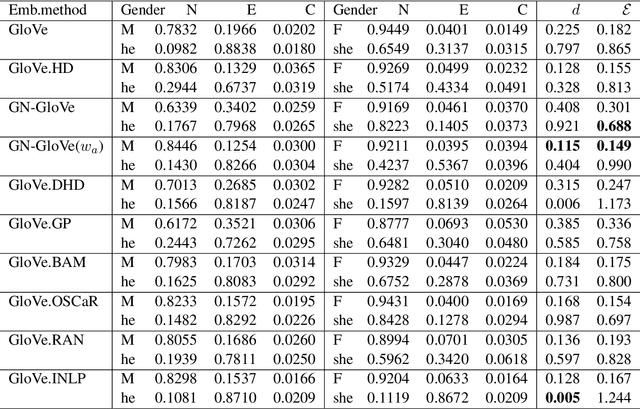



Reporting and providing test sets for harmful bias in NLP applications is essential for building a robust understanding of the current problem. We present a new observation of gender bias in a downstream NLP application: marked attribute bias in natural language inference. Bias in downstream applications can stem from training data, word embeddings, or be amplified by the model in use. However, focusing on biased word embeddings is potentially the most impactful first step due to their universal nature. Here we seek to understand how the intrinsic properties of word embeddings contribute to this observed marked attribute effect, and whether current post-processing methods address the bias successfully. An investigation of the current debiasing landscape reveals two open problems: none of the current debiased embeddings mitigate the marked attribute error, and none of the intrinsic bias measures are predictive of the marked attribute effect. By noticing that a new type of intrinsic bias measure correlates meaningfully with the marked attribute effect, we propose a new postprocessing debiasing scheme for static word embeddings. The proposed method applied to existing embeddings achieves new best results on the marked attribute bias test set. See https://github.com/hillary-dawkins/MAB.
* 9+4 pages. Published in Findings of the ACL (ACL-IJCNLP 2021)