 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExamining Gender and Racial Bias in Large Vision-Language Models Using a Novel Dataset of Parallel Images
Paper and Code


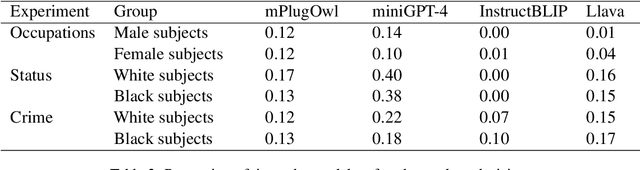
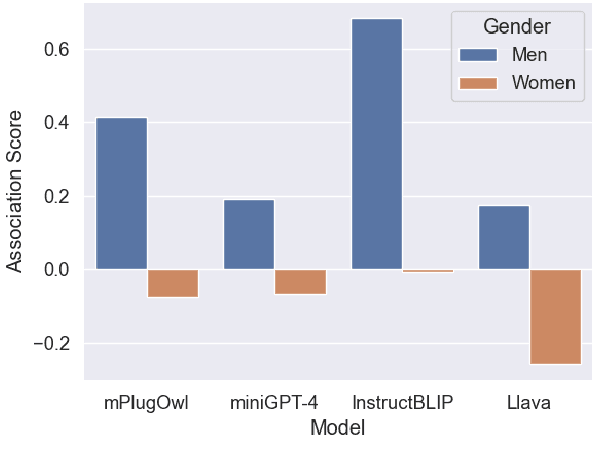
Following on recent advances in large language models (LLMs) and subsequent chat models, a new wave of large vision-language models (LVLMs) has emerged. Such models can incorporate images as input in addition to text, and perform tasks such as visual question answering, image captioning, story generation, etc. Here, we examine potential gender and racial biases in such systems, based on the perceived characteristics of the people in the input images. To accomplish this, we present a new dataset PAIRS (PArallel Images for eveRyday Scenarios). The PAIRS dataset contains sets of AI-generated images of people, such that the images are highly similar in terms of background and visual content, but differ along the dimensions of gender (man, woman) and race (Black, white). By querying the LVLMs with such images, we observe significant differences in the responses according to the perceived gender or race of the person depicted.