 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfident Rankings with Fewer Items: Adaptive LLM Evaluation with Continuous Scores
Jan 20, 2026Computerized Adaptive Testing (CAT) has proven effective for efficient LLM evaluation on multiple-choice benchmarks, but modern LLM evaluation increasingly relies on generation tasks where outputs are scored continuously rather than marked correct/incorrect. We present a principled extension of IRT-based adaptive testing to continuous bounded scores (ROUGE, BLEU, LLM-as-a-Judge) by replacing the Bernoulli response distribution with a heteroskedastic normal distribution. Building on this, we introduce an uncertainty aware ranker with adaptive stopping criteria that achieves reliable model ranking while testing as few items and as cheaply as possible. We validate our method on five benchmarks spanning n-gram-based, embedding-based, and LLM-as-judge metrics. Our method uses 2% of the items while improving ranking correlation by 0.12 τ over random sampling, with 95% accuracy on confident predictions.
Concept-Based Explanations to Test for False Causal Relationships Learned by Abusive Language Classifiers
Jul 04, 2023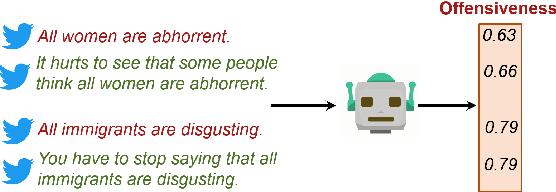

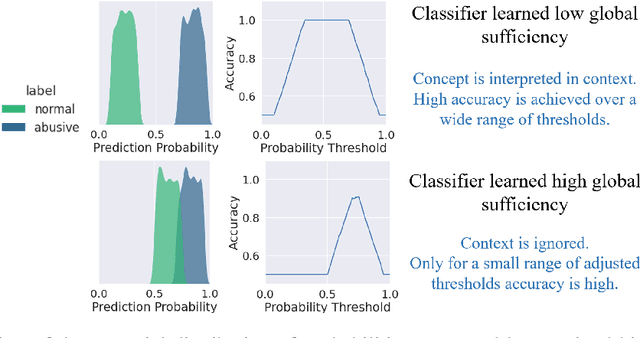

Classifiers tend to learn a false causal relationship between an over-represented concept and a label, which can result in over-reliance on the concept and compromised classification accuracy. It is imperative to have methods in place that can compare different models and identify over-reliances on specific concepts. We consider three well-known abusive language classifiers trained on large English datasets and focus on the concept of negative emotions, which is an important signal but should not be learned as a sufficient feature for the label of abuse. Motivated by the definition of global sufficiency, we first examine the unwanted dependencies learned by the classifiers by assessing their accuracy on a challenge set across all decision thresholds. Further, recognizing that a challenge set might not always be available, we introduce concept-based explanation metrics to assess the influence of the concept on the labels. These explanations allow us to compare classifiers regarding the degree of false global sufficiency they have learned between a concept and a label.
Towards Procedural Fairness: Uncovering Biases in How a Toxic Language Classifier Uses Sentiment Information
Oct 19, 2022



Previous works on the fairness of toxic language classifiers compare the output of models with different identity terms as input features but do not consider the impact of other important concepts present in the context. Here, besides identity terms, we take into account high-level latent features learned by the classifier and investigate the interaction between these features and identity terms. For a multi-class toxic language classifier, we leverage a concept-based explanation framework to calculate the sensitivity of the model to the concept of sentiment, which has been used before as a salient feature for toxic language detection. Our results show that although for some classes, the classifier has learned the sentiment information as expected, this information is outweighed by the influence of identity terms as input features. This work is a step towards evaluating procedural fairness, where unfair processes lead to unfair outcomes. The produced knowledge can guide debiasing techniques to ensure that important concepts besides identity terms are well-represented in training datasets.