 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVax-Culture: A Dataset for Studying Vaccine Discourse on Twitter
Apr 17, 2023



Vaccine hesitancy continues to be a main challenge for public health officials during the COVID-19 pandemic. As this hesitancy undermines vaccine campaigns, many researchers have sought to identify its root causes, finding that the increasing volume of anti-vaccine misinformation on social media platforms is a key element of this problem. We explored Twitter as a source of misleading content with the goal of extracting overlapping cultural and political beliefs that motivate the spread of vaccine misinformation. To do this, we have collected a data set of vaccine-related Tweets and annotated them with the help of a team of annotators with a background in communications and journalism. Ultimately we hope this can lead to effective and targeted public health communication strategies for reaching individuals with anti-vaccine beliefs. Moreover, this information helps with developing Machine Learning models to automatically detect vaccine misinformation posts and combat their negative impacts. In this paper, we present Vax-Culture, a novel Twitter COVID-19 dataset consisting of 6373 vaccine-related tweets accompanied by an extensive set of human-provided annotations including vaccine-hesitancy stance, indication of any misinformation in tweets, the entities criticized and supported in each tweet and the communicated message of each tweet. Moreover, we define five baseline tasks including four classification and one sequence generation tasks, and report the results of a set of recent transformer-based models for them. The dataset and code are publicly available at https://github.com/mrzarei5/Vax-Culture.
Interpretable Few-shot Learning with Online Attribute Selection
Nov 16, 2022



Few-shot learning (FSL) is a challenging learning problem in which only a few samples are available for each class. Decision interpretation is more important in few-shot classification since there is a greater chance of error than in traditional classification. However, most of the previous FSL methods are black-box models. In this paper, we propose an inherently interpretable model for FSL based on human-friendly attributes. Moreover, we propose an online attribute selection mechanism that can effectively filter out irrelevant attributes in each episode. The attribute selection mechanism improves the accuracy and helps with interpretability by reducing the number of participated attributes in each episode. We demonstrate that the proposed method achieves results on par with black-box few-shot-learning models on four widely used datasets. To further close the performance gap with the black-box models, we propose a mechanism that trades interpretability for accuracy. It automatically detects the episodes where the provided human-friendly attributes are not adequate, and compensates by engaging learned unknown attributes.
Interpretable Concept-based Prototypical Networks for Few-Shot Learning
Feb 27, 2022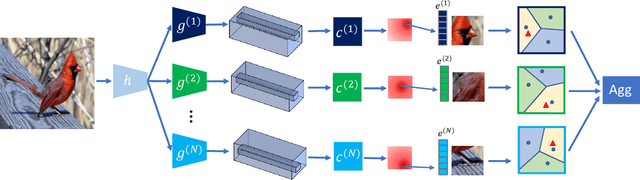
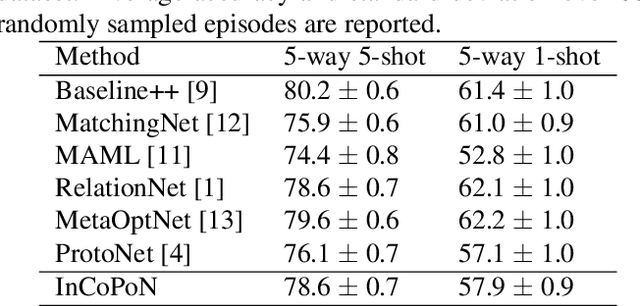

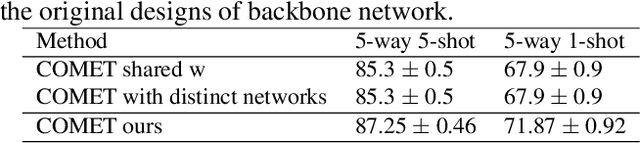
Few-shot learning aims at recognizing new instances from classes with limited samples. This challenging task is usually alleviated by performing meta-learning on similar tasks. However, the resulting models are black-boxes. There has been growing concerns about deploying black-box machine learning models and FSL is not an exception in this regard. In this paper, we propose a method for FSL based on a set of human-interpretable concepts. It constructs a set of metric spaces associated with the concepts and classifies samples of novel classes by aggregating concept-specific decisions. The proposed method does not require concept annotations for query samples. This interpretable method achieved results on a par with six previously state-of-the-art black-box FSL methods on the CUB fine-grained bird classification dataset.
An Adaptive Similarity Measure to Tune Trust Influence in Memory-Based Collaborative Filtering
Dec 18, 2019



The aim of the recommender systems is to provide relevant and potentially interesting information to each user. This is fulfilled by utilizing the already recorded tendencies of similar users or detecting items similar to interested items of the user. Challenges such as data sparsity and cold start problem are addressed in recent studies. Utilizing social information not only enhances the prediction accuracy but also tackles the data sparseness challenges. In this paper, we investigate the impact of using direct and indirect trust information in a memory-based collaborative filtering recommender system. An adaptive similarity measure is proposed and the contribution of social information is tuned using two learning schemes, greedy and gradient-based optimization. The results of the proposed method are compared with state-of-the-art memory-based and model-based CF approaches on two real-world datasets, Epinions and FilmTrust. The experiments show that our method is quite effective in designing an accurate and comprehensive recommender system.