 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Interpretability of Part-Prototype Based Classifiers: A Human Centric Analysis
Oct 10, 2023Part-prototype networks have recently become methods of interest as an interpretable alternative to many of the current black-box image classifiers. However, the interpretability of these methods from the perspective of human users has not been sufficiently explored. In this work, we have devised a framework for evaluating the interpretability of part-prototype-based models from a human perspective. The proposed framework consists of three actionable metrics and experiments. To demonstrate the usefulness of our framework, we performed an extensive set of experiments using Amazon Mechanical Turk. They not only show the capability of our framework in assessing the interpretability of various part-prototype-based models, but they also are, to the best of our knowledge, the most comprehensive work on evaluating such methods in a unified framework.
Feature-Based Interpretable Reinforcement Learning based on State-Transition Models
May 14, 2021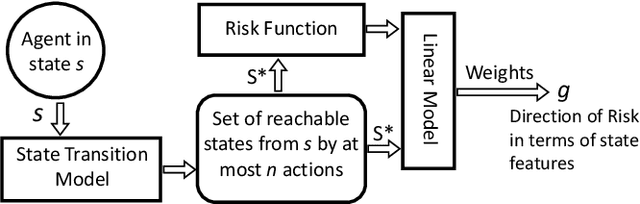
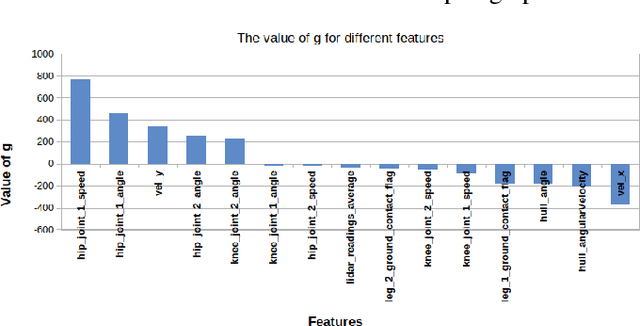
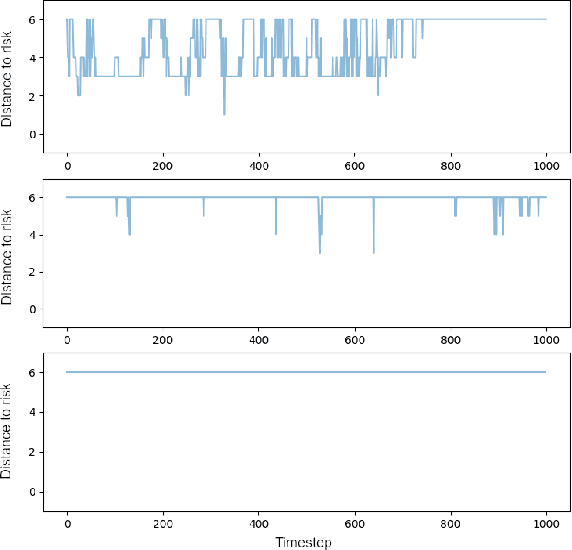
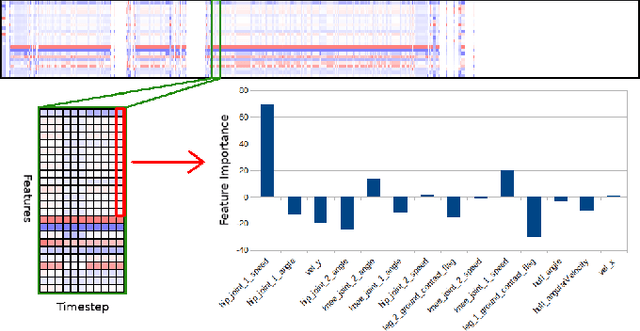
Growing concerns regarding the operational usage of AI models in the real-world has caused a surge of interest in explaining AI models' decisions to humans. Reinforcement Learning is not an exception in this regard. In this work, we propose a method for offering local explanations on risk in reinforcement learning. Our method only requires a log of previous interactions between the agent and the environment to create a state-transition model. It is designed to work on RL environments with either continuous or discrete state and action spaces. After creating the model, actions of any agent can be explained in terms of the features most influential in increasing or decreasing risk or any other desirable objective function in the locality of the agent. Through experiments, we demonstrate the effectiveness of the proposed method in providing such explanations.