Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Deep Learning Model Parameters with the Bees Algorithm for Improved Medical Text Classification
Paper and Code
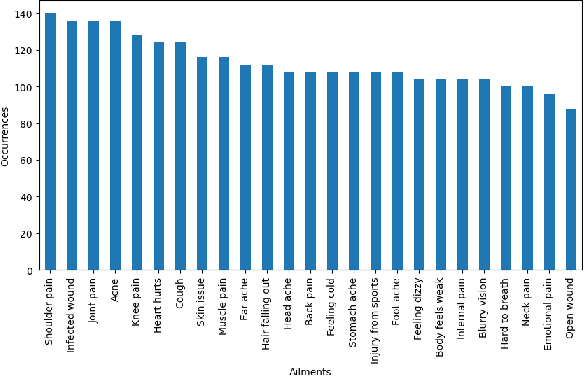
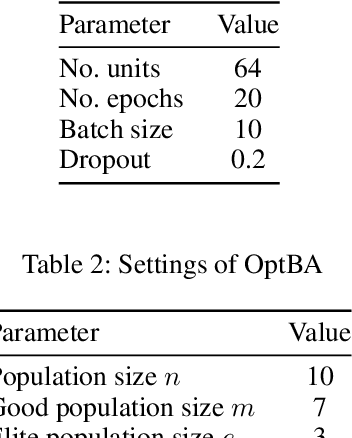
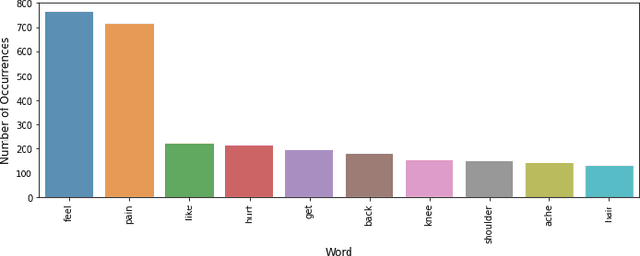

This paper introduces a novel mechanism to obtain the optimal parameters of a deep learning model using the Bees Algorithm, which is a recent promising swarm intelligence algorithm. The optimization problem is to maximize the accuracy of classifying ailments based on medical text given the initial hyper-parameters to be adjusted throughout a definite number of iterations. Experiments included two different datasets: English and Arabic. The highest accuracy achieved is 99.63% on the English dataset using Long Short-Term Memory (LSTM) along with the Bees Algorithm, and 88% on the Arabic dataset using AraBERT.
View paper on