 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePaying More Attention to Visual Tokens in Self-Evolving Large Multimodal Models
Jun 25, 2026Recently, self-evolving large multimodal models (LMMs) have received attention for improving visual reasoning in a purely unsupervised setting. However, multi-role self-play and self-consistency reward schemes in existing self-evolving LMMs optimize answer agreement without ensuring the decoder attends to visual content, relying instead on statistical language priors to produce self consistent outputs. This leads to a persistent failure mode we term visual under-conditioning, where the decoder relies on language priors rather than the image during generation, manifesting as insufficient attention to visual tokens. As a result, current self-evolving LMMs struggle on vision--language understanding tasks such as image captioning and visual question answering. To address this, we propose VISE (Visual Invariance Self-Evolution), a purely unsupervised self-evolving framework that directly regularizes the model's visual conditioning policy through two complementary invariance-based rewards: a geometric invariance reward that enforces spatial consistency under known transformations, and a semantic invariance reward that penalizes evidence-agnostic generation by requiring the model to recognize the absence of evidence when predicted regions are perturbed. VISE operates within a single model without specialist roles, external reward models, or annotations, and is trained on raw unlabeled images. Experiments on 18 benchmarks demonstrate the efficacy of our approach. Using Qwen3-VL-2B as the base model, VISE achieves gains of $+16.85$ CIDEr on COCO and $+19.66$ CIDEr on TextCaps, reduces object hallucination by $5.0$ Chair-I points, and generalizes across four model families and scales. Our code and models are available at https://mbzuai-oryx.github.io/VISE
Ask, Solve, Generate: Self-Evolving Unified Multimodal Understanding and Generation via Self-Consistency Rewards
Jun 25, 2026Most unified large multimodal models (LMMs) that support both visual understanding and image generation still rely on curated post-training supervision, such as human annotations, preference labels, or external reward models. We ask whether a unified LMM can improve both abilities autonomously using only unlabeled images. We propose a self-evolving training framework with three internal roles: a Proposer that generates visual questions, a Solver that answers and evaluates them, and a Generator that synthesizes images. Training uses only self-derived consistency signals, without human annotations, preference labels, or task-trained external reward/judge models. To stabilize learning, we introduce Solver Token Entropy (STE), a continuous difficulty signal based on token-level prediction uncertainty that remains useful even when sample-level consistency becomes unreliable. For image generation, we design a multi-scale internal evaluation scheme that combines question-answer fidelity scoring with cycle-consistent captioning. This creates a solver-mediated coupling, where better visual understanding enables more reliable generation assessment and stronger internal training signals. The framework preserves the same role decomposition, reward logic, and training schedule across diffusion-based BLIP3o, rectified-flow BAGEL, and autoregressive VARGPT-v1.1 architectures, requiring only each backbone's native prompting and generation interface. Across eight understanding metrics, our method consistently improves over the corresponding base models. On BAGEL, it achieves a $+3.5\%$ absolute gain on MMMU and improves GenEval image generation performance from $82\%$ to $85\%$. Code and models are publicly released.
CoVR-R:Reason-Aware Composed Video Retrieval
Mar 20, 2026Composed Video Retrieval (CoVR) aims to find a target video given a reference video and a textual modification. Prior work assumes the modification text fully specifies the visual changes, overlooking after-effects and implicit consequences (e.g., motion, state transitions, viewpoint or duration cues) that emerge from the edit. We argue that successful CoVR requires reasoning about these after-effects. We introduce a reasoning-first, zero-shot approach that leverages large multimodal models to (i) infer causal and temporal consequences implied by the edit, and (ii) align the resulting reasoned queries to candidate videos without task-specific finetuning. To evaluate reasoning in CoVR, we also propose CoVR-Reason, a benchmark that pairs each (reference, edit, target) triplet with structured internal reasoning traces and challenging distractors that require predicting after-effects rather than keyword matching. Experiments show that our zero-shot method outperforms strong retrieval baselines on recall at K and particularly excels on implicit-effect subsets. Our automatic and human analysis confirm higher step consistency and effect factuality in our retrieved results. Our findings show that incorporating reasoning into general-purpose multimodal models enables effective CoVR by explicitly accounting for causal and temporal after-effects. This reduces dependence on task-specific supervision, improves generalization to challenging implicit-effect cases, and enhances interpretability of retrieval outcomes. These results point toward a scalable and principled framework for explainable video search. The model, code, and benchmark are available at https://github.com/mbzuai-oryx/CoVR-R.
Mobile-O: Unified Multimodal Understanding and Generation on Mobile Device
Feb 24, 2026Unified multimodal models can both understand and generate visual content within a single architecture. Existing models, however, remain data-hungry and too heavy for deployment on edge devices. We present Mobile-O, a compact vision-language-diffusion model that brings unified multimodal intelligence to a mobile device. Its core module, the Mobile Conditioning Projector (MCP), fuses vision-language features with a diffusion generator using depthwise-separable convolutions and layerwise alignment. This design enables efficient cross-modal conditioning with minimal computational cost. Trained on only a few million samples and post-trained in a novel quadruplet format (generation prompt, image, question, answer), Mobile-O jointly enhances both visual understanding and generation capabilities. Despite its efficiency, Mobile-O attains competitive or superior performance compared to other unified models, achieving 74% on GenEval and outperforming Show-O and JanusFlow by 5% and 11%, while running 6x and 11x faster, respectively. For visual understanding, Mobile-O surpasses them by 15.3% and 5.1% averaged across seven benchmarks. Running in only ~3s per 512x512 image on an iPhone, Mobile-O establishes the first practical framework for real-time unified multimodal understanding and generation on edge devices. We hope Mobile-O will ease future research in real-time unified multimodal intelligence running entirely on-device with no cloud dependency. Our code, models, datasets, and mobile application are publicly available at https://amshaker.github.io/Mobile-O/
DuwatBench: Bridging Language and Visual Heritage through an Arabic Calligraphy Benchmark for Multimodal Understanding
Jan 27, 2026Arabic calligraphy represents one of the richest visual traditions of the Arabic language, blending linguistic meaning with artistic form. Although multimodal models have advanced across languages, their ability to process Arabic script, especially in artistic and stylized calligraphic forms, remains largely unexplored. To address this gap, we present DuwatBench, a benchmark of 1,272 curated samples containing about 1,475 unique words across six classical and modern calligraphic styles, each paired with sentence-level detection annotations. The dataset reflects real-world challenges in Arabic writing, such as complex stroke patterns, dense ligatures, and stylistic variations that often challenge standard text recognition systems. Using DuwatBench, we evaluated 13 leading Arabic and multilingual multimodal models and showed that while they perform well on clean text, they struggle with calligraphic variation, artistic distortions, and precise visual-text alignment. By publicly releasing DuwatBench and its annotations, we aim to advance culturally grounded multimodal research, foster fair inclusion of the Arabic language and visual heritage in AI systems, and support continued progress in this area. Our dataset (https://huggingface.co/datasets/MBZUAI/DuwatBench) and evaluation suit (https://github.com/mbzuai-oryx/DuwatBench) are publicly available.
Thinking Beyond Labels: Vocabulary-Free Fine-Grained Recognition using Reasoning-Augmented LMMs
Dec 21, 2025Vocabulary-free fine-grained image recognition aims to distinguish visually similar categories within a meta-class without a fixed, human-defined label set. Existing solutions for this problem are limited by either the usage of a large and rigid list of vocabularies or by the dependency on complex pipelines with fragile heuristics where errors propagate across stages. Meanwhile, the ability of recent large multi-modal models (LMMs) equipped with explicit or implicit reasoning to comprehend visual-language data, decompose problems, retrieve latent knowledge, and self-correct suggests a more principled and effective alternative. Building on these capabilities, we propose FiNDR (Fine-grained Name Discovery via Reasoning), the first reasoning-augmented LMM-based framework for vocabulary-free fine-grained recognition. The system operates in three automated steps: (i) a reasoning-enabled LMM generates descriptive candidate labels for each image; (ii) a vision-language model filters and ranks these candidates to form a coherent class set; and (iii) the verified names instantiate a lightweight multi-modal classifier used at inference time. Extensive experiments on popular fine-grained classification benchmarks demonstrate state-of-the-art performance under the vocabulary-free setting, with a significant relative margin of up to 18.8% over previous approaches. Remarkably, the proposed method surpasses zero-shot baselines that exploit pre-defined ground-truth names, challenging the assumption that human-curated vocabularies define an upper bound. Additionally, we show that carefully curated prompts enable open-source LMMs to match proprietary counterparts. These findings establish reasoning-augmented LMMs as an effective foundation for scalable, fully automated, open-world fine-grained visual recognition. The source code is available on github.com/demidovd98/FiNDR.
How Good are Foundation Models in Step-by-Step Embodied Reasoning?
Sep 18, 2025
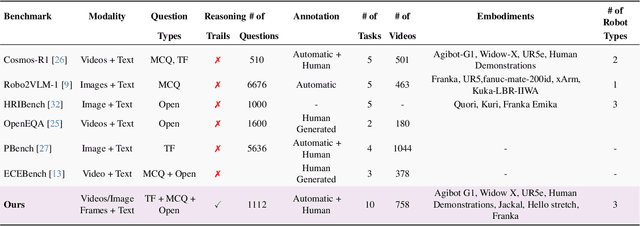
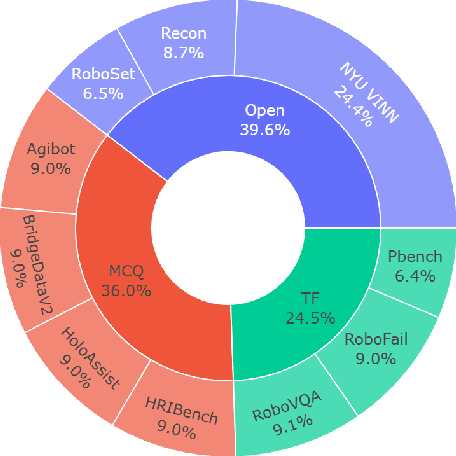

Embodied agents operating in the physical world must make decisions that are not only effective but also safe, spatially coherent, and grounded in context. While recent advances in large multimodal models (LMMs) have shown promising capabilities in visual understanding and language generation, their ability to perform structured reasoning for real-world embodied tasks remains underexplored. In this work, we aim to understand how well foundation models can perform step-by-step reasoning in embodied environments. To this end, we propose the Foundation Model Embodied Reasoning (FoMER) benchmark, designed to evaluate the reasoning capabilities of LMMs in complex embodied decision-making scenarios. Our benchmark spans a diverse set of tasks that require agents to interpret multimodal observations, reason about physical constraints and safety, and generate valid next actions in natural language. We present (i) a large-scale, curated suite of embodied reasoning tasks, (ii) a novel evaluation framework that disentangles perceptual grounding from action reasoning, and (iii) empirical analysis of several leading LMMs under this setting. Our benchmark includes over 1.1k samples with detailed step-by-step reasoning across 10 tasks and 8 embodiments, covering three different robot types. Our results highlight both the potential and current limitations of LMMs in embodied reasoning, pointing towards key challenges and opportunities for future research in robot intelligence. Our data and code will be made publicly available.
Beyond Simple Edits: Composed Video Retrieval with Dense Modifications
Aug 19, 2025Composed video retrieval is a challenging task that strives to retrieve a target video based on a query video and a textual description detailing specific modifications. Standard retrieval frameworks typically struggle to handle the complexity of fine-grained compositional queries and variations in temporal understanding limiting their retrieval ability in the fine-grained setting. To address this issue, we introduce a novel dataset that captures both fine-grained and composed actions across diverse video segments, enabling more detailed compositional changes in retrieved video content. The proposed dataset, named Dense-WebVid-CoVR, consists of 1.6 million samples with dense modification text that is around seven times more than its existing counterpart. We further develop a new model that integrates visual and textual information through Cross-Attention (CA) fusion using grounded text encoder, enabling precise alignment between dense query modifications and target videos. The proposed model achieves state-of-the-art results surpassing existing methods on all metrics. Notably, it achieves 71.3\% Recall@1 in visual+text setting and outperforms the state-of-the-art by 3.4\%, highlighting its efficacy in terms of leveraging detailed video descriptions and dense modification texts. Our proposed dataset, code, and model are available at :https://github.com/OmkarThawakar/BSE-CoVR
Fann or Flop: A Multigenre, Multiera Benchmark for Arabic Poetry Understanding in LLMs
May 26, 2025
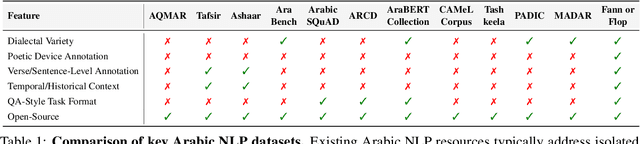
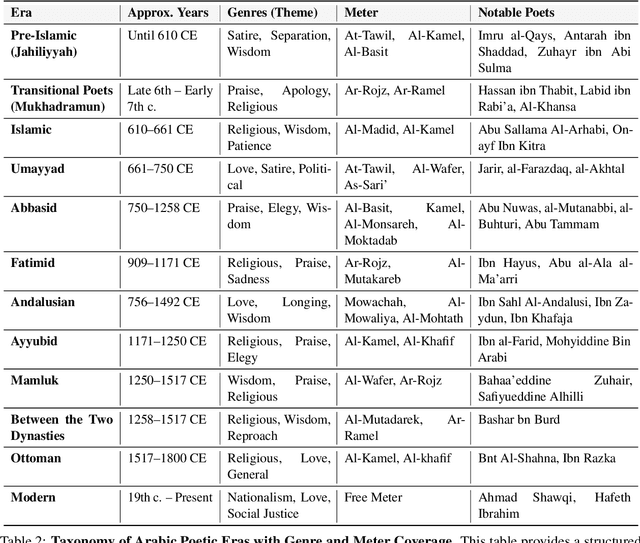
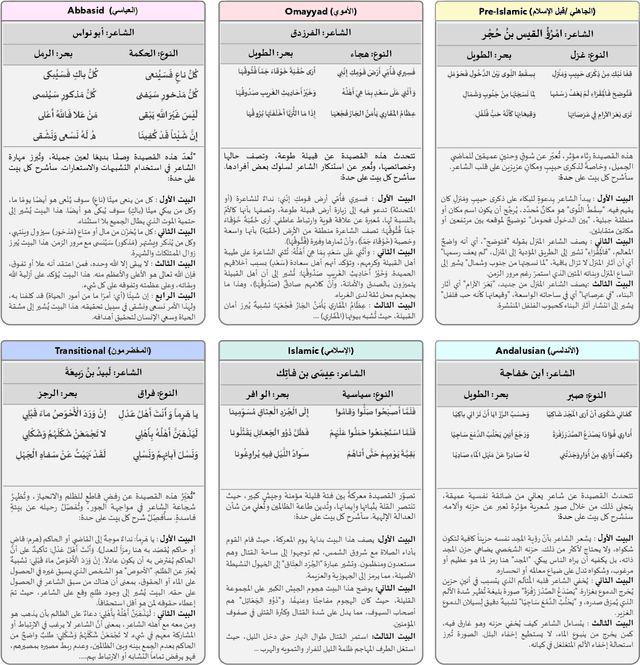
Arabic poetry is one of the richest and most culturally rooted forms of expression in the Arabic language, known for its layered meanings, stylistic diversity, and deep historical continuity. Although large language models (LLMs) have demonstrated strong performance across languages and tasks, their ability to understand Arabic poetry remains largely unexplored. In this work, we introduce \emph{Fann or Flop}, the first benchmark designed to assess the comprehension of Arabic poetry by LLMs in 12 historical eras, covering 14 core poetic genres and a variety of metrical forms, from classical structures to contemporary free verse. The benchmark comprises a curated corpus of poems with explanations that assess semantic understanding, metaphor interpretation, prosodic awareness, and cultural context. We argue that poetic comprehension offers a strong indicator for testing how good the LLM understands classical Arabic through Arabic poetry. Unlike surface-level tasks, this domain demands deeper interpretive reasoning and cultural sensitivity. Our evaluation of state-of-the-art LLMs shows that most models struggle with poetic understanding despite strong results on standard Arabic benchmarks. We release "Fann or Flop" along with the evaluation suite as an open-source resource to enable rigorous evaluation and advancement for Arabic language models. Code is available at: https://github.com/mbzuai-oryx/FannOrFlop.
ARB: A Comprehensive Arabic Multimodal Reasoning Benchmark
May 22, 2025
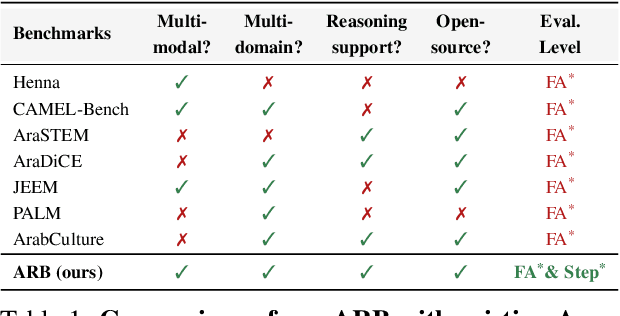
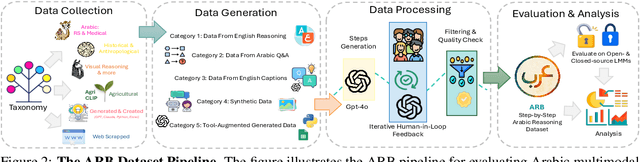
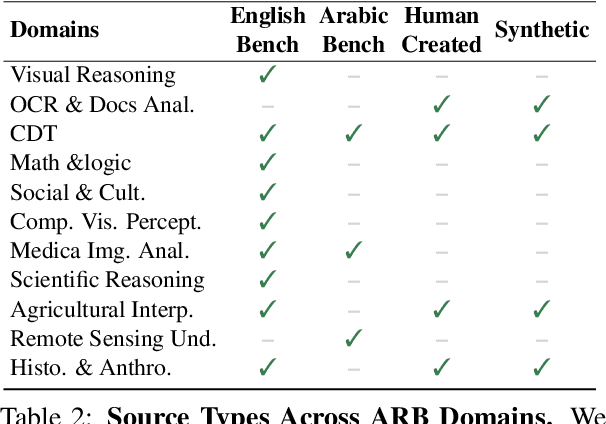
As Large Multimodal Models (LMMs) become more capable, there is growing interest in evaluating their reasoning processes alongside their final outputs. However, most benchmarks remain focused on English, overlooking languages with rich linguistic and cultural contexts, such as Arabic. To address this gap, we introduce the Comprehensive Arabic Multimodal Reasoning Benchmark (ARB), the first benchmark designed to evaluate step-by-step reasoning in Arabic across both textual and visual modalities. ARB spans 11 diverse domains, including visual reasoning, document understanding, OCR, scientific analysis, and cultural interpretation. It comprises 1,356 multimodal samples paired with 5,119 human-curated reasoning steps and corresponding actions. We evaluated 12 state-of-the-art open- and closed-source LMMs and found persistent challenges in coherence, faithfulness, and cultural grounding. ARB offers a structured framework for diagnosing multimodal reasoning in underrepresented languages and marks a critical step toward inclusive, transparent, and culturally aware AI systems. We release the benchmark, rubric, and evaluation suit to support future research and reproducibility. Code available at: https://github.com/mbzuai-oryx/ARB