 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBYOL: Bring Your Own Language Into LLMs
Jan 15, 2026Large Language Models (LLMs) exhibit strong multilingual capabilities, yet remain fundamentally constrained by the severe imbalance in global language resources. While over 7,000 languages are spoken worldwide, only a small subset (fewer than 100) has sufficient digital presence to meaningfully influence modern LLM training. This disparity leads to systematic underperformance, cultural misalignment, and limited accessibility for speakers of low-resource and extreme-low-resource languages. To address this gap, we introduce Bring Your Own Language (BYOL), a unified framework for scalable, language-aware LLM development tailored to each language's digital footprint. BYOL begins with a language resource classification that maps languages into four tiers (Extreme-Low, Low, Mid, High) using curated web-scale corpora, and uses this classification to select the appropriate integration pathway. For low-resource languages, we propose a full-stack data refinement and expansion pipeline that combines corpus cleaning, synthetic text generation, continual pretraining, and supervised finetuning. Applied to Chichewa and Maori, this pipeline yields language-specific LLMs that achieve approximately 12 percent average improvement over strong multilingual baselines across 12 benchmarks, while preserving English and multilingual capabilities via weight-space model merging. For extreme-low-resource languages, we introduce a translation-mediated inclusion pathway, and show on Inuktitut that a tailored machine translation system improves over a commercial baseline by 4 BLEU, enabling high-accuracy LLM access when direct language modeling is infeasible. Finally, we release human-translated versions of the Global MMLU-Lite benchmark in Chichewa, Maori, and Inuktitut, and make our codebase and models publicly available at https://github.com/microsoft/byol .
AfriqueLLM: How Data Mixing and Model Architecture Impact Continued Pre-training for African Languages
Jan 10, 2026Large language models (LLMs) are increasingly multilingual, yet open models continue to underperform relative to proprietary systems, with the gap most pronounced for African languages. Continued pre-training (CPT) offers a practical route to language adaptation, but improvements on demanding capabilities such as mathematical reasoning often remain limited. This limitation is driven in part by the uneven domain coverage and missing task-relevant knowledge that characterize many low-resource language corpora. We present \texttt{AfriqueLLM}, a suite of open LLMs adapted to 20 African languages through CPT on 26B tokens. We perform a comprehensive empirical study across five base models spanning sizes and architectures, including Llama 3.1, Gemma 3, and Qwen 3, and systematically analyze how CPT data composition shapes downstream performance. In particular, we vary mixtures that include math, code, and synthetic translated data, and evaluate the resulting models on a range of multilingual benchmarks. Our results identify data composition as the primary driver of CPT gains. Adding math, code, and synthetic translated data yields consistent improvements, including on reasoning-oriented evaluations. Within a fixed architecture, larger models typically improve performance, but architectural choices dominate scale when comparing across model families. Moreover, strong multilingual performance in the base model does not reliably predict post-CPT outcomes; robust architectures coupled with task-aligned data provide a more dependable recipe. Finally, our best models improve long-context performance, including document-level translation. Models have been released on [Huggingface](https://huggingface.co/collections/McGill-NLP/afriquellm).
Dynamic Pre-training: Towards Efficient and Scalable All-in-One Image Restoration
Apr 02, 2024



All-in-one image restoration tackles different types of degradations with a unified model instead of having task-specific, non-generic models for each degradation. The requirement to tackle multiple degradations using the same model can lead to high-complexity designs with fixed configuration that lack the adaptability to more efficient alternatives. We propose DyNet, a dynamic family of networks designed in an encoder-decoder style for all-in-one image restoration tasks. Our DyNet can seamlessly switch between its bulkier and lightweight variants, thereby offering flexibility for efficient model deployment with a single round of training. This seamless switching is enabled by our weights-sharing mechanism, forming the core of our architecture and facilitating the reuse of initialized module weights. Further, to establish robust weights initialization, we introduce a dynamic pre-training strategy that trains variants of the proposed DyNet concurrently, thereby achieving a 50% reduction in GPU hours. To tackle the unavailability of large-scale dataset required in pre-training, we curate a high-quality, high-resolution image dataset named Million-IRD having 2M image samples. We validate our DyNet for image denoising, deraining, and dehazing in all-in-one setting, achieving state-of-the-art results with 31.34% reduction in GFlops and a 56.75% reduction in parameters compared to baseline models. The source codes and trained models are available at https://github.com/akshaydudhane16/DyNet.
AdaIR: Adaptive All-in-One Image Restoration via Frequency Mining and Modulation
Mar 21, 2024
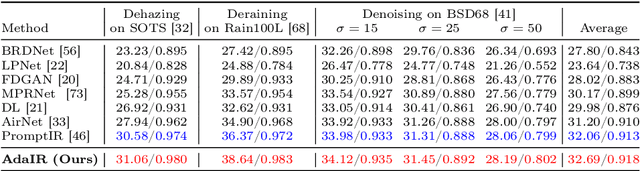
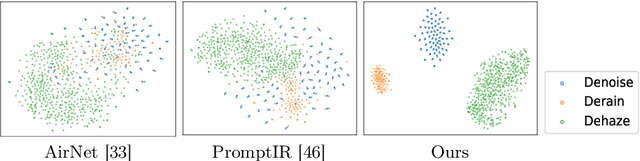

In the image acquisition process, various forms of degradation, including noise, haze, and rain, are frequently introduced. These degradations typically arise from the inherent limitations of cameras or unfavorable ambient conditions. To recover clean images from degraded versions, numerous specialized restoration methods have been developed, each targeting a specific type of degradation. Recently, all-in-one algorithms have garnered significant attention by addressing different types of degradations within a single model without requiring prior information of the input degradation type. However, these methods purely operate in the spatial domain and do not delve into the distinct frequency variations inherent to different degradation types. To address this gap, we propose an adaptive all-in-one image restoration network based on frequency mining and modulation. Our approach is motivated by the observation that different degradation types impact the image content on different frequency subbands, thereby requiring different treatments for each restoration task. Specifically, we first mine low- and high-frequency information from the input features, guided by the adaptively decoupled spectra of the degraded image. The extracted features are then modulated by a bidirectional operator to facilitate interactions between different frequency components. Finally, the modulated features are merged into the original input for a progressively guided restoration. With this approach, the model achieves adaptive reconstruction by accentuating the informative frequency subbands according to different input degradations. Extensive experiments demonstrate that the proposed method achieves state-of-the-art performance on different image restoration tasks, including denoising, dehazing, deraining, motion deblurring, and low-light image enhancement. Our code is available at https://github.com/c-yn/AdaIR.
PromptIR: Prompting for All-in-One Blind Image Restoration
Jun 22, 2023Image restoration involves recovering a high-quality clean image from its degraded version. Deep learning-based methods have significantly improved image restoration performance, however, they have limited generalization ability to different degradation types and levels. This restricts their real-world application since it requires training individual models for each specific degradation and knowing the input degradation type to apply the relevant model. We present a prompt-based learning approach, PromptIR, for All-In-One image restoration that can effectively restore images from various types and levels of degradation. In particular, our method uses prompts to encode degradation-specific information, which is then used to dynamically guide the restoration network. This allows our method to generalize to different degradation types and levels, while still achieving state-of-the-art results on image denoising, deraining, and dehazing. Overall, PromptIR offers a generic and efficient plugin module with few lightweight prompts that can be used to restore images of various types and levels of degradation with no prior information on the corruptions present in the image. Our code and pretrained models are available here: https://github.com/va1shn9v/PromptIR
Gated Multi-Resolution Transfer Network for Burst Restoration and Enhancement
Apr 13, 2023Burst image processing is becoming increasingly popular in recent years. However, it is a challenging task since individual burst images undergo multiple degradations and often have mutual misalignments resulting in ghosting and zipper artifacts. Existing burst restoration methods usually do not consider the mutual correlation and non-local contextual information among burst frames, which tends to limit these approaches in challenging cases. Another key challenge lies in the robust up-sampling of burst frames. The existing up-sampling methods cannot effectively utilize the advantages of single-stage and progressive up-sampling strategies with conventional and/or recent up-samplers at the same time. To address these challenges, we propose a novel Gated Multi-Resolution Transfer Network (GMTNet) to reconstruct a spatially precise high-quality image from a burst of low-quality raw images. GMTNet consists of three modules optimized for burst processing tasks: Multi-scale Burst Feature Alignment (MBFA) for feature denoising and alignment, Transposed-Attention Feature Merging (TAFM) for multi-frame feature aggregation, and Resolution Transfer Feature Up-sampler (RTFU) to up-scale merged features and construct a high-quality output image. Detailed experimental analysis on five datasets validates our approach and sets a state-of-the-art for burst super-resolution, burst denoising, and low-light burst enhancement.
Burstormer: Burst Image Restoration and Enhancement Transformer
Apr 03, 2023



On a shutter press, modern handheld cameras capture multiple images in rapid succession and merge them to generate a single image. However, individual frames in a burst are misaligned due to inevitable motions and contain multiple degradations. The challenge is to properly align the successive image shots and merge their complimentary information to achieve high-quality outputs. Towards this direction, we propose Burstormer: a novel transformer-based architecture for burst image restoration and enhancement. In comparison to existing works, our approach exploits multi-scale local and non-local features to achieve improved alignment and feature fusion. Our key idea is to enable inter-frame communication in the burst neighborhoods for information aggregation and progressive fusion while modeling the burst-wide context. However, the input burst frames need to be properly aligned before fusing their information. Therefore, we propose an enhanced deformable alignment module for aligning burst features with regards to the reference frame. Unlike existing methods, the proposed alignment module not only aligns burst features but also exchanges feature information and maintains focused communication with the reference frame through the proposed reference-based feature enrichment mechanism, which facilitates handling complex motions. After multi-level alignment and enrichment, we re-emphasize on inter-frame communication within burst using a cyclic burst sampling module. Finally, the inter-frame information is aggregated using the proposed burst feature fusion module followed by progressive upsampling. Our Burstormer outperforms state-of-the-art methods on burst super-resolution, burst denoising and burst low-light enhancement. Our codes and pretrained models are available at https:// github.com/akshaydudhane16/Burstormer
EdgeNeXt: Efficiently Amalgamated CNN-Transformer Architecture for Mobile Vision Applications
Jun 21, 2022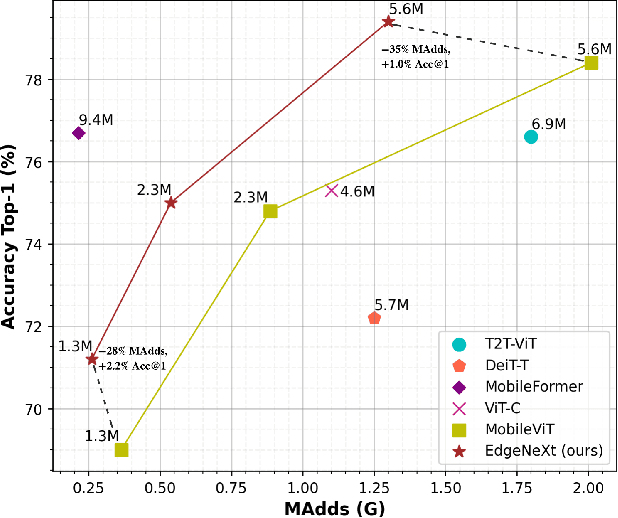
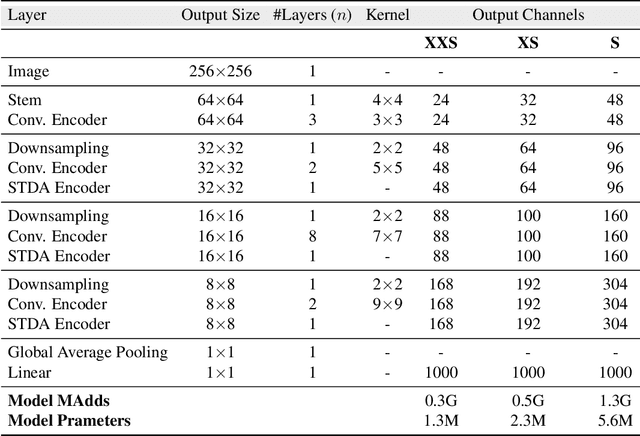

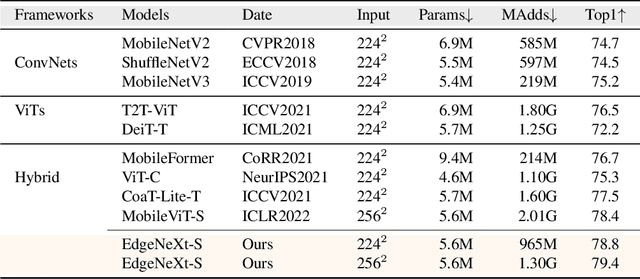
In the pursuit of achieving ever-increasing accuracy, large and complex neural networks are usually developed. Such models demand high computational resources and therefore cannot be deployed on edge devices. It is of great interest to build resource-efficient general purpose networks due to their usefulness in several application areas. In this work, we strive to effectively combine the strengths of both CNN and Transformer models and propose a new efficient hybrid architecture EdgeNeXt. Specifically in EdgeNeXt, we introduce split depth-wise transpose attention (SDTA) encoder that splits input tensors into multiple channel groups and utilizes depth-wise convolution along with self-attention across channel dimensions to implicitly increase the receptive field and encode multi-scale features. Our extensive experiments on classification, detection and segmentation tasks, reveal the merits of the proposed approach, outperforming state-of-the-art methods with comparatively lower compute requirements. Our EdgeNeXt model with 1.3M parameters achieves 71.2\% top-1 accuracy on ImageNet-1K, outperforming MobileViT with an absolute gain of 2.2\% with 28\% reduction in FLOPs. Further, our EdgeNeXt model with 5.6M parameters achieves 79.4\% top-1 accuracy on ImageNet-1K. The code and models are publicly available at https://t.ly/_Vu9.
NTIRE 2022 Challenge on Efficient Super-Resolution: Methods and Results
May 11, 2022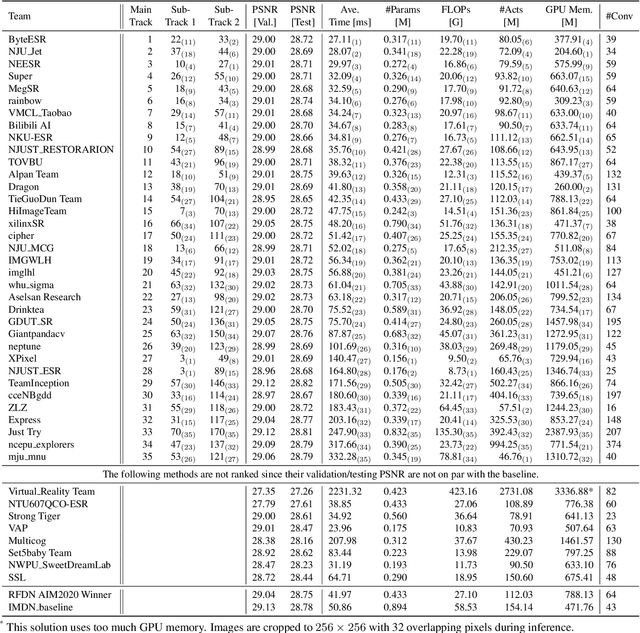
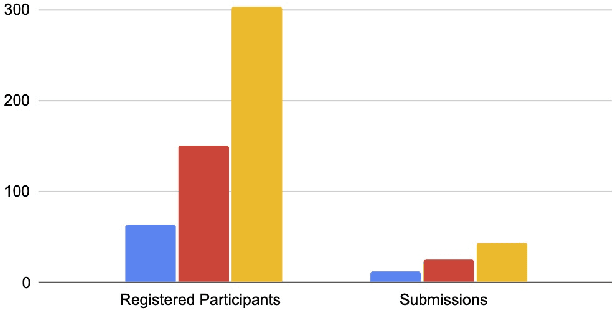
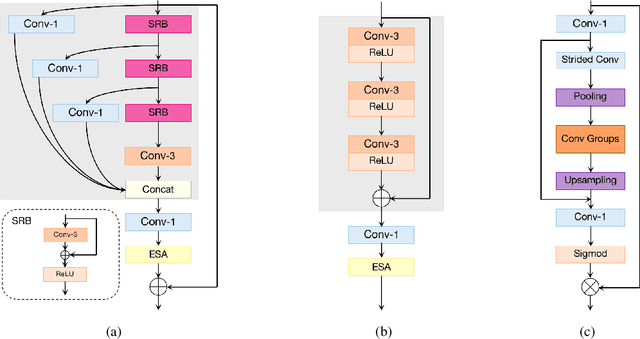
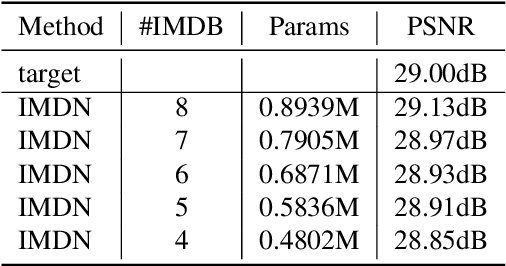
This paper reviews the NTIRE 2022 challenge on efficient single image super-resolution with focus on the proposed solutions and results. The task of the challenge was to super-resolve an input image with a magnification factor of $\times$4 based on pairs of low and corresponding high resolution images. The aim was to design a network for single image super-resolution that achieved improvement of efficiency measured according to several metrics including runtime, parameters, FLOPs, activations, and memory consumption while at least maintaining the PSNR of 29.00dB on DIV2K validation set. IMDN is set as the baseline for efficiency measurement. The challenge had 3 tracks including the main track (runtime), sub-track one (model complexity), and sub-track two (overall performance). In the main track, the practical runtime performance of the submissions was evaluated. The rank of the teams were determined directly by the absolute value of the average runtime on the validation set and test set. In sub-track one, the number of parameters and FLOPs were considered. And the individual rankings of the two metrics were summed up to determine a final ranking in this track. In sub-track two, all of the five metrics mentioned in the description of the challenge including runtime, parameter count, FLOPs, activations, and memory consumption were considered. Similar to sub-track one, the rankings of five metrics were summed up to determine a final ranking. The challenge had 303 registered participants, and 43 teams made valid submissions. They gauge the state-of-the-art in efficient single image super-resolution.
Transformers in Medical Imaging: A Survey
Jan 24, 2022
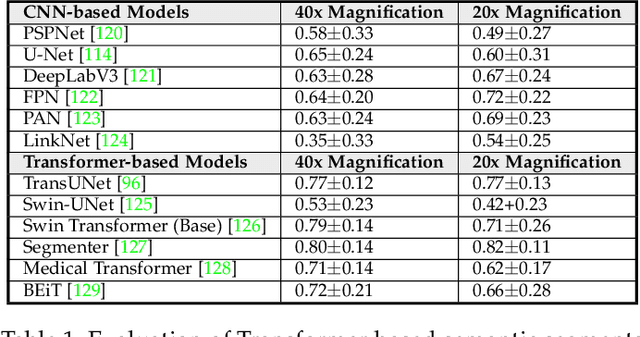
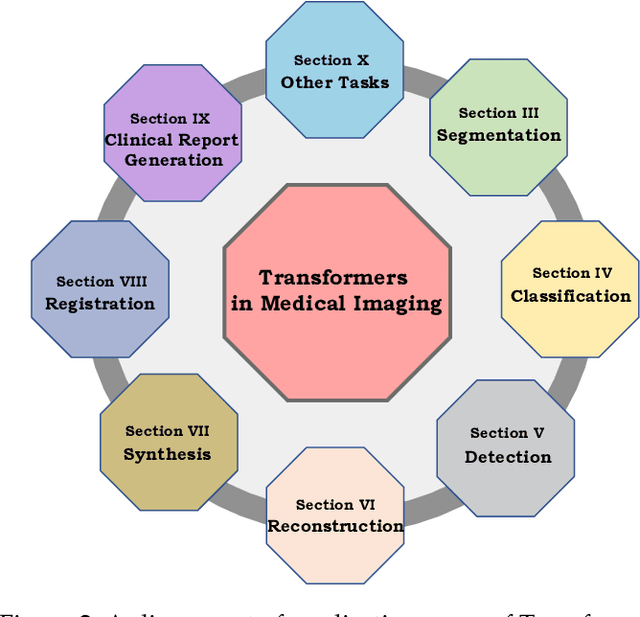
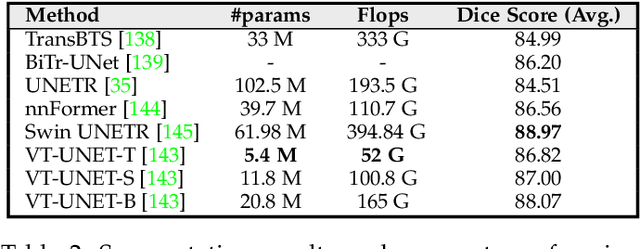
Following unprecedented success on the natural language tasks, Transformers have been successfully applied to several computer vision problems, achieving state-of-the-art results and prompting researchers to reconsider the supremacy of convolutional neural networks (CNNs) as {de facto} operators. Capitalizing on these advances in computer vision, the medical imaging field has also witnessed growing interest for Transformers that can capture global context compared to CNNs with local receptive fields. Inspired from this transition, in this survey, we attempt to provide a comprehensive review of the applications of Transformers in medical imaging covering various aspects, ranging from recently proposed architectural designs to unsolved issues. Specifically, we survey the use of Transformers in medical image segmentation, detection, classification, reconstruction, synthesis, registration, clinical report generation, and other tasks. In particular, for each of these applications, we develop taxonomy, identify application-specific challenges as well as provide insights to solve them, and highlight recent trends. Further, we provide a critical discussion of the field's current state as a whole, including the identification of key challenges, open problems, and outlining promising future directions. We hope this survey will ignite further interest in the community and provide researchers with an up-to-date reference regarding applications of Transformer models in medical imaging. Finally, to cope with the rapid development in this field, we intend to regularly update the relevant latest papers and their open-source implementations at \url{https://github.com/fahadshamshad/awesome-transformers-in-medical-imaging}.