 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiTVR: Zero-Shot Diffusion Transformer for Video Restoration
Aug 11, 2025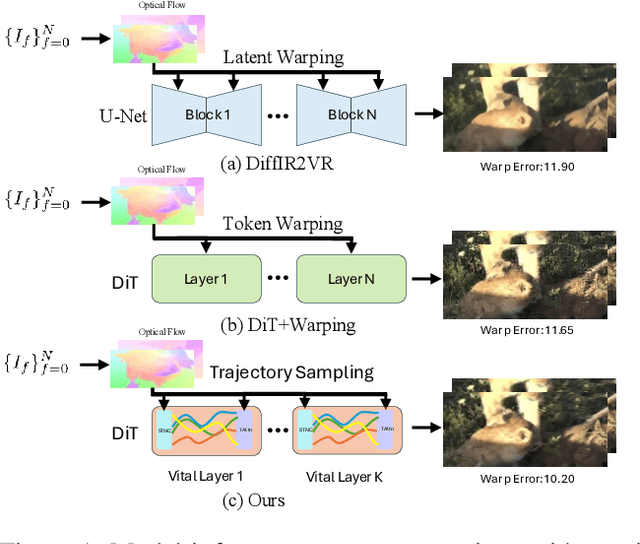


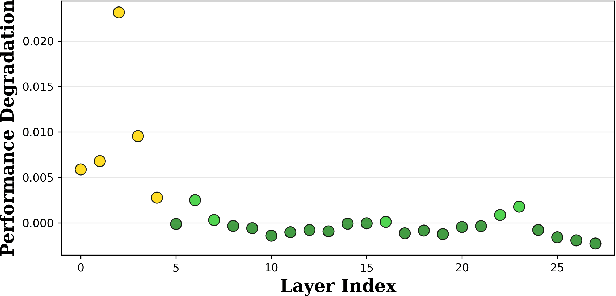
Video restoration aims to reconstruct high quality video sequences from low quality inputs, addressing tasks such as super resolution, denoising, and deblurring. Traditional regression based methods often produce unrealistic details and require extensive paired datasets, while recent generative diffusion models face challenges in ensuring temporal consistency. We introduce DiTVR, a zero shot video restoration framework that couples a diffusion transformer with trajectory aware attention and a wavelet guided, flow consistent sampler. Unlike prior 3D convolutional or frame wise diffusion approaches, our attention mechanism aligns tokens along optical flow trajectories, with particular emphasis on vital layers that exhibit the highest sensitivity to temporal dynamics. A spatiotemporal neighbour cache dynamically selects relevant tokens based on motion correspondences across frames. The flow guided sampler injects data consistency only into low-frequency bands, preserving high frequency priors while accelerating convergence. DiTVR establishes a new zero shot state of the art on video restoration benchmarks, demonstrating superior temporal consistency and detail preservation while remaining robust to flow noise and occlusions.
Modulate and Reconstruct: Learning Hyperspectral Imaging from Misaligned Smartphone Views
Jul 02, 2025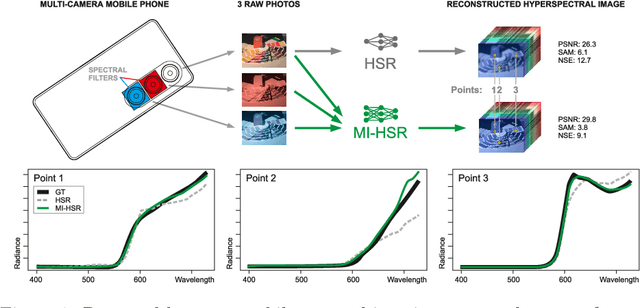

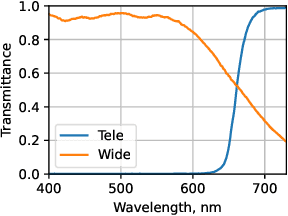

Hyperspectral reconstruction (HSR) from RGB images is a fundamentally ill-posed problem due to severe spectral information loss. Existing approaches typically rely on a single RGB image, limiting reconstruction accuracy. In this work, we propose a novel multi-image-to-hyperspectral reconstruction (MI-HSR) framework that leverages a triple-camera smartphone system, where two lenses are equipped with carefully selected spectral filters. Our configuration, grounded in theoretical and empirical analysis, enables richer and more diverse spectral observations than conventional single-camera setups. To support this new paradigm, we introduce Doomer, the first dataset for MI-HSR, comprising aligned images from three smartphone cameras and a hyperspectral reference camera across diverse scenes. We show that the proposed HSR model achieves consistent improvements over existing methods on the newly proposed benchmark. In a nutshell, our setup allows 30% towards more accurately estimated spectra compared to an ordinary RGB camera. Our findings suggest that multi-view spectral filtering with commodity hardware can unlock more accurate and practical hyperspectral imaging solutions.
LeMoRe: Learn More Details for Lightweight Semantic Segmentation
May 29, 2025



Lightweight semantic segmentation is essential for many downstream vision tasks. Unfortunately, existing methods often struggle to balance efficiency and performance due to the complexity of feature modeling. Many of these existing approaches are constrained by rigid architectures and implicit representation learning, often characterized by parameter-heavy designs and a reliance on computationally intensive Vision Transformer-based frameworks. In this work, we introduce an efficient paradigm by synergizing explicit and implicit modeling to balance computational efficiency with representational fidelity. Our method combines well-defined Cartesian directions with explicitly modeled views and implicitly inferred intermediate representations, efficiently capturing global dependencies through a nested attention mechanism. Extensive experiments on challenging datasets, including ADE20K, CityScapes, Pascal Context, and COCO-Stuff, demonstrate that LeMoRe strikes an effective balance between performance and efficiency.
Color Matching Using Hypernetwork-Based Kolmogorov-Arnold Networks
Mar 14, 2025We present cmKAN, a versatile framework for color matching. Given an input image with colors from a source color distribution, our method effectively and accurately maps these colors to match a target color distribution in both supervised and unsupervised settings. Our framework leverages the spline capabilities of Kolmogorov-Arnold Networks (KANs) to model the color matching between source and target distributions. Specifically, we developed a hypernetwork that generates spatially varying weight maps to control the nonlinear splines of a KAN, enabling accurate color matching. As part of this work, we introduce a first large-scale dataset of paired images captured by two distinct cameras and evaluate the efficacy of our and existing methods in matching colors. We evaluated our approach across various color-matching tasks, including: (1) raw-to-raw mapping, where the source color distribution is in one camera's raw color space and the target in another camera's raw space; (2) raw-to-sRGB mapping, where the source color distribution is in a camera's raw space and the target is in the display sRGB space, emulating the color rendering of a camera ISP; and (3) sRGB-to-sRGB mapping, where the goal is to transfer colors from a source sRGB space (e.g., produced by a source camera ISP) to a target sRGB space (e.g., from a different camera ISP). The results show that our method outperforms existing approaches by 37.3% on average for supervised and unsupervised cases while remaining lightweight compared to other methods. The codes, dataset, and pre-trained models are available at: https://github.com/gosha20777/cmKAN
AdaptSR: Low-Rank Adaptation for Efficient and Scalable Real-World Super-Resolution
Mar 10, 2025Recovering high-frequency details and textures from low-resolution images remains a fundamental challenge in super-resolution (SR), especially when real-world degradations are complex and unknown. While GAN-based methods enhance realism, they suffer from training instability and introduce unnatural artifacts. Diffusion models, though promising, demand excessive computational resources, often requiring multiple GPU days, even for single-step variants. Rather than naively fine-tuning entire models or adopting unstable generative approaches, we introduce AdaptSR, a low-rank adaptation (LoRA) framework that efficiently repurposes bicubic-trained SR models for real-world tasks. AdaptSR leverages architecture-specific insights and selective layer updates to optimize real SR adaptation. By updating only lightweight LoRA layers while keeping the pretrained backbone intact, it captures domain-specific adjustments without adding inference cost, as the adapted layers merge seamlessly post-training. This efficient adaptation not only reduces memory and compute requirements but also makes real-world SR feasible on lightweight hardware. Our experiments demonstrate that AdaptSR outperforms GAN and diffusion-based SR methods by up to 4 dB in PSNR and 2% in perceptual scores on real SR benchmarks. More impressively, it matches or exceeds full model fine-tuning while training 92% fewer parameters, enabling rapid adaptation to real SR tasks within minutes.
ContextFormer: Redefining Efficiency in Semantic Segmentation
Jan 31, 2025



Semantic segmentation assigns labels to pixels in images, a critical yet challenging task in computer vision. Convolutional methods, although capturing local dependencies well, struggle with long-range relationships. Vision Transformers (ViTs) excel in global context capture but are hindered by high computational demands, especially for high-resolution inputs. Most research optimizes the encoder architecture, leaving the bottleneck underexplored - a key area for enhancing performance and efficiency. We propose ContextFormer, a hybrid framework leveraging the strengths of CNNs and ViTs in the bottleneck to balance efficiency, accuracy, and robustness for real-time semantic segmentation. The framework's efficiency is driven by three synergistic modules: the Token Pyramid Extraction Module (TPEM) for hierarchical multi-scale representation, the Transformer and Modulating DepthwiseConv (Trans-MDC) block for dynamic scale-aware feature modeling, and the Feature Merging Module (FMM) for robust integration with enhanced spatial and contextual consistency. Extensive experiments on ADE20K, Pascal Context, CityScapes, and COCO-Stuff datasets show ContextFormer significantly outperforms existing models, achieving state-of-the-art mIoU scores, setting a new benchmark for efficiency and performance. The codes will be made publicly available.
Complexity Experts are Task-Discriminative Learners for Any Image Restoration
Nov 27, 2024



Recent advancements in all-in-one image restoration models have revolutionized the ability to address diverse degradations through a unified framework. However, parameters tied to specific tasks often remain inactive for other tasks, making mixture-of-experts (MoE) architectures a natural extension. Despite this, MoEs often show inconsistent behavior, with some experts unexpectedly generalizing across tasks while others struggle within their intended scope. This hinders leveraging MoEs' computational benefits by bypassing irrelevant experts during inference. We attribute this undesired behavior to the uniform and rigid architecture of traditional MoEs. To address this, we introduce ``complexity experts" -- flexible expert blocks with varying computational complexity and receptive fields. A key challenge is assigning tasks to each expert, as degradation complexity is unknown in advance. Thus, we execute tasks with a simple bias toward lower complexity. To our surprise, this preference effectively drives task-specific allocation, assigning tasks to experts with the appropriate complexity. Extensive experiments validate our approach, demonstrating the ability to bypass irrelevant experts during inference while maintaining superior performance. The proposed MoCE-IR model outperforms state-of-the-art methods, affirming its efficiency and practical applicability. The source will be publicly made available at \href{https://eduardzamfir.github.io/moceir/}{\texttt{eduardzamfir.github.io/MoCE-IR/}}
Efficient Degradation-aware Any Image Restoration
May 24, 2024Reconstructing missing details from degraded low-quality inputs poses a significant challenge. Recent progress in image restoration has demonstrated the efficacy of learning large models capable of addressing various degradations simultaneously. Nonetheless, these approaches introduce considerable computational overhead and complex learning paradigms, limiting their practical utility. In response, we propose \textit{DaAIR}, an efficient All-in-One image restorer employing a Degradation-aware Learner (DaLe) in the low-rank regime to collaboratively mine shared aspects and subtle nuances across diverse degradations, generating a degradation-aware embedding. By dynamically allocating model capacity to input degradations, we realize an efficient restorer integrating holistic and specific learning within a unified model. Furthermore, DaAIR introduces a cost-efficient parameter update mechanism that enhances degradation awareness while maintaining computational efficiency. Extensive comparisons across five image degradations demonstrate that our DaAIR outperforms both state-of-the-art All-in-One models and degradation-specific counterparts, affirming our efficacy and practicality. The source will be publicly made available at \url{https://eduardzamfir.github.io/daair/}
The Ninth NTIRE 2024 Efficient Super-Resolution Challenge Report
Apr 16, 2024



This paper provides a comprehensive review of the NTIRE 2024 challenge, focusing on efficient single-image super-resolution (ESR) solutions and their outcomes. The task of this challenge is to super-resolve an input image with a magnification factor of x4 based on pairs of low and corresponding high-resolution images. The primary objective is to develop networks that optimize various aspects such as runtime, parameters, and FLOPs, while still maintaining a peak signal-to-noise ratio (PSNR) of approximately 26.90 dB on the DIV2K_LSDIR_valid dataset and 26.99 dB on the DIV2K_LSDIR_test dataset. In addition, this challenge has 4 tracks including the main track (overall performance), sub-track 1 (runtime), sub-track 2 (FLOPs), and sub-track 3 (parameters). In the main track, all three metrics (ie runtime, FLOPs, and parameter count) were considered. The ranking of the main track is calculated based on a weighted sum-up of the scores of all other sub-tracks. In sub-track 1, the practical runtime performance of the submissions was evaluated, and the corresponding score was used to determine the ranking. In sub-track 2, the number of FLOPs was considered. The score calculated based on the corresponding FLOPs was used to determine the ranking. In sub-track 3, the number of parameters was considered. The score calculated based on the corresponding parameters was used to determine the ranking. RLFN is set as the baseline for efficiency measurement. The challenge had 262 registered participants, and 34 teams made valid submissions. They gauge the state-of-the-art in efficient single-image super-resolution. To facilitate the reproducibility of the challenge and enable other researchers to build upon these findings, the code and the pre-trained model of validated solutions are made publicly available at https://github.com/Amazingren/NTIRE2024_ESR/.
Rawformer: Unpaired Raw-to-Raw Translation for Learnable Camera ISPs
Apr 16, 2024
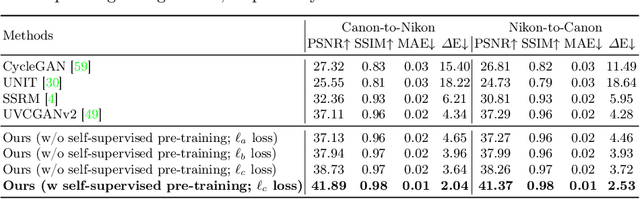
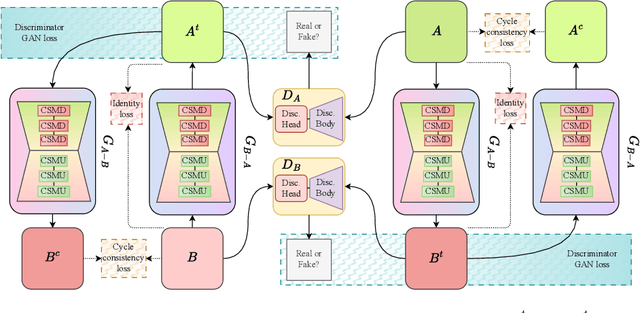
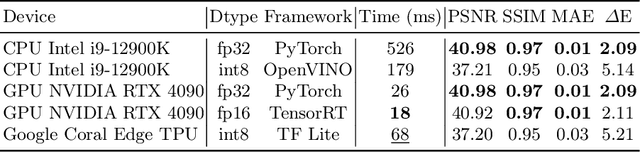
Modern smartphone camera quality heavily relies on the image signal processor (ISP) to enhance captured raw images, utilizing carefully designed modules to produce final output images encoded in a standard color space (e.g., sRGB). Neural-based end-to-end learnable ISPs offer promising advancements, potentially replacing traditional ISPs with their ability to adapt without requiring extensive tuning for each new camera model, as is often the case for nearly every module in traditional ISPs. However, the key challenge with the recent learning-based ISPs is the urge to collect large paired datasets for each distinct camera model due to the influence of intrinsic camera characteristics on the formation of input raw images. This paper tackles this challenge by introducing a novel method for unpaired learning of raw-to-raw translation across diverse cameras. Specifically, we propose Rawformer, an unsupervised Transformer-based encoder-decoder method for raw-to-raw translation. It accurately maps raw images captured by a certain camera to the target camera, facilitating the generalization of learnable ISPs to new unseen cameras. Our method demonstrates superior performance on real camera datasets, achieving higher accuracy compared to previous state-of-the-art techniques, and preserving a more robust correlation between the original and translated raw images.