 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Vision-Language Models to Select Trustworthy Super-Resolution Samples Generated by Diffusion Models
Jun 25, 2025Super-resolution (SR) is an ill-posed inverse problem with many feasible solutions consistent with a given low-resolution image. On one hand, regressive SR models aim to balance fidelity and perceptual quality to yield a single solution, but this trade-off often introduces artifacts that create ambiguity in information-critical applications such as recognizing digits or letters. On the other hand, diffusion models generate a diverse set of SR images, but selecting the most trustworthy solution from this set remains a challenge. This paper introduces a robust, automated framework for identifying the most trustworthy SR sample from a diffusion-generated set by leveraging the semantic reasoning capabilities of vision-language models (VLMs). Specifically, VLMs such as BLIP-2, GPT-4o, and their variants are prompted with structured queries to assess semantic correctness, visual quality, and artifact presence. The top-ranked SR candidates are then ensembled to yield a single trustworthy output in a cost-effective manner. To rigorously assess the validity of VLM-selected samples, we propose a novel Trustworthiness Score (TWS) a hybrid metric that quantifies SR reliability based on three complementary components: semantic similarity via CLIP embeddings, structural integrity using SSIM on edge maps, and artifact sensitivity through multi-level wavelet decomposition. We empirically show that TWS correlates strongly with human preference in both ambiguous and natural images, and that VLM-guided selections consistently yield high TWS values. Compared to conventional metrics like PSNR, LPIPS, which fail to reflect information fidelity, our approach offers a principled, scalable, and generalizable solution for navigating the uncertainty of the diffusion SR space. By aligning outputs with human expectations and semantic correctness, this work sets a new benchmark for trustworthiness in generative SR.
AdaptSR: Low-Rank Adaptation for Efficient and Scalable Real-World Super-Resolution
Mar 10, 2025Recovering high-frequency details and textures from low-resolution images remains a fundamental challenge in super-resolution (SR), especially when real-world degradations are complex and unknown. While GAN-based methods enhance realism, they suffer from training instability and introduce unnatural artifacts. Diffusion models, though promising, demand excessive computational resources, often requiring multiple GPU days, even for single-step variants. Rather than naively fine-tuning entire models or adopting unstable generative approaches, we introduce AdaptSR, a low-rank adaptation (LoRA) framework that efficiently repurposes bicubic-trained SR models for real-world tasks. AdaptSR leverages architecture-specific insights and selective layer updates to optimize real SR adaptation. By updating only lightweight LoRA layers while keeping the pretrained backbone intact, it captures domain-specific adjustments without adding inference cost, as the adapted layers merge seamlessly post-training. This efficient adaptation not only reduces memory and compute requirements but also makes real-world SR feasible on lightweight hardware. Our experiments demonstrate that AdaptSR outperforms GAN and diffusion-based SR methods by up to 4 dB in PSNR and 2% in perceptual scores on real SR benchmarks. More impressively, it matches or exceeds full model fine-tuning while training 92% fewer parameters, enabling rapid adaptation to real SR tasks within minutes.
Training Transformer Models by Wavelet Losses Improves Quantitative and Visual Performance in Single Image Super-Resolution
Apr 17, 2024



Transformer-based models have achieved remarkable results in low-level vision tasks including image super-resolution (SR). However, early Transformer-based approaches that rely on self-attention within non-overlapping windows encounter challenges in acquiring global information. To activate more input pixels globally, hybrid attention models have been proposed. Moreover, training by solely minimizing pixel-wise RGB losses, such as L1, have been found inadequate for capturing essential high-frequency details. This paper presents two contributions: i) We introduce convolutional non-local sparse attention (NLSA) blocks to extend the hybrid transformer architecture in order to further enhance its receptive field. ii) We employ wavelet losses to train Transformer models to improve quantitative and subjective performance. While wavelet losses have been explored previously, showing their power in training Transformer-based SR models is novel. Our experimental results demonstrate that the proposed model provides state-of-the-art PSNR results as well as superior visual performance across various benchmark datasets.
NTIRE 2024 Challenge on Image Super-Resolution ($\times$4): Methods and Results
Apr 15, 2024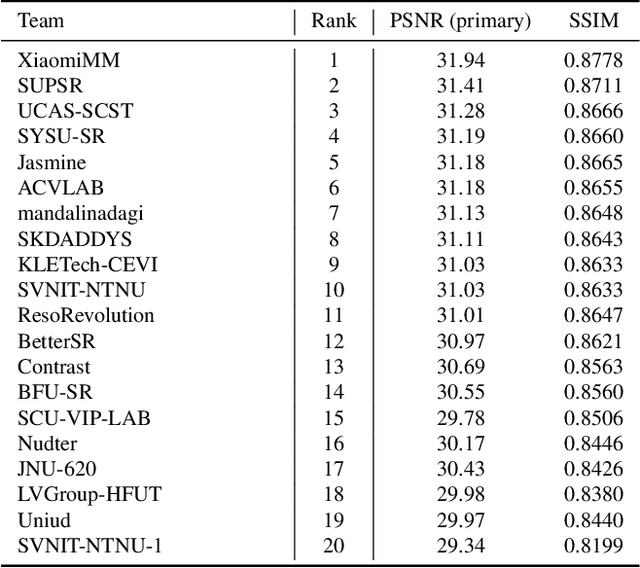
This paper reviews the NTIRE 2024 challenge on image super-resolution ($\times$4), highlighting the solutions proposed and the outcomes obtained. The challenge involves generating corresponding high-resolution (HR) images, magnified by a factor of four, from low-resolution (LR) inputs using prior information. The LR images originate from bicubic downsampling degradation. The aim of the challenge is to obtain designs/solutions with the most advanced SR performance, with no constraints on computational resources (e.g., model size and FLOPs) or training data. The track of this challenge assesses performance with the PSNR metric on the DIV2K testing dataset. The competition attracted 199 registrants, with 20 teams submitting valid entries. This collective endeavour not only pushes the boundaries of performance in single-image SR but also offers a comprehensive overview of current trends in this field.
Training Generative Image Super-Resolution Models by Wavelet-Domain Losses Enables Better Control of Artifacts
Feb 29, 2024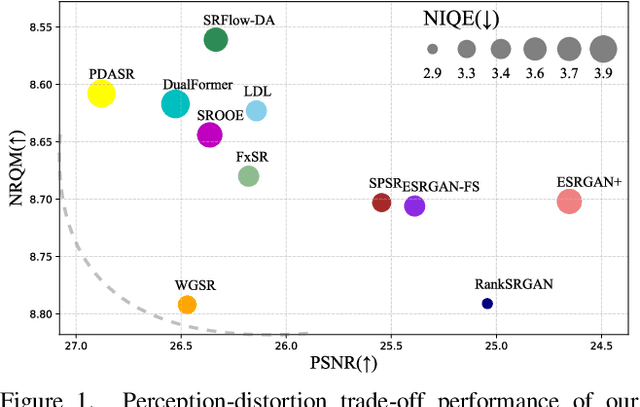
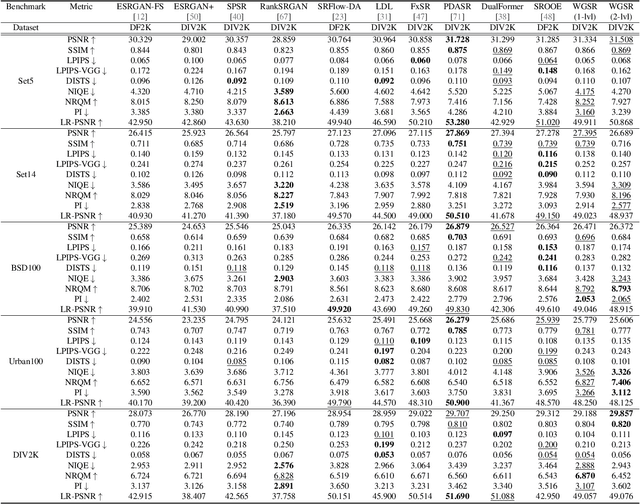

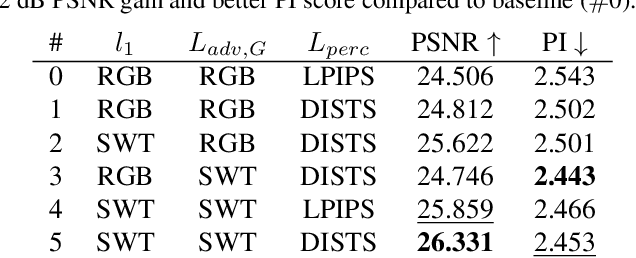
Super-resolution (SR) is an ill-posed inverse problem, where the size of the set of feasible solutions that are consistent with a given low-resolution image is very large. Many algorithms have been proposed to find a "good" solution among the feasible solutions that strike a balance between fidelity and perceptual quality. Unfortunately, all known methods generate artifacts and hallucinations while trying to reconstruct high-frequency (HF) image details. A fundamental question is: Can a model learn to distinguish genuine image details from artifacts? Although some recent works focused on the differentiation of details and artifacts, this is a very challenging problem and a satisfactory solution is yet to be found. This paper shows that the characterization of genuine HF details versus artifacts can be better learned by training GAN-based SR models using wavelet-domain loss functions compared to RGB-domain or Fourier-space losses. Although wavelet-domain losses have been used in the literature before, they have not been used in the context of the SR task. More specifically, we train the discriminator only on the HF wavelet sub-bands instead of on RGB images and the generator is trained by a fidelity loss over wavelet subbands to make it sensitive to the scale and orientation of structures. Extensive experimental results demonstrate that our model achieves better perception-distortion trade-off according to multiple objective measures and visual evaluations.
Trustworthy SR: Resolving Ambiguity in Image Super-resolution via Diffusion Models and Human Feedback
Feb 12, 2024



Super-resolution (SR) is an ill-posed inverse problem with a large set of feasible solutions that are consistent with a given low-resolution image. Various deterministic algorithms aim to find a single solution that balances fidelity and perceptual quality; however, this trade-off often causes visual artifacts that bring ambiguity in information-centric applications. On the other hand, diffusion models (DMs) excel in generating a diverse set of feasible SR images that span the solution space. The challenge is then how to determine the most likely solution among this set in a trustworthy manner. We observe that quantitative measures, such as PSNR, LPIPS, DISTS, are not reliable indicators to resolve ambiguous cases. To this effect, we propose employing human feedback, where we ask human subjects to select a small number of likely samples and we ensemble the averages of selected samples. This strategy leverages the high-quality image generation capabilities of DMs, while recognizing the importance of obtaining a single trustworthy solution, especially in use cases, such as identification of specific digits or letters, where generating multiple feasible solutions may not lead to a reliable outcome. Experimental results demonstrate that our proposed strategy provides more trustworthy solutions when compared to state-of-the art SR methods.
MMSR: Multiple-Model Learned Image Super-Resolution Benefiting From Class-Specific Image Priors
Sep 18, 2022
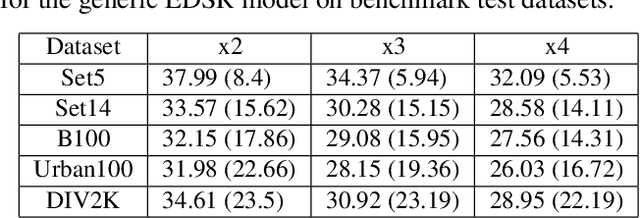
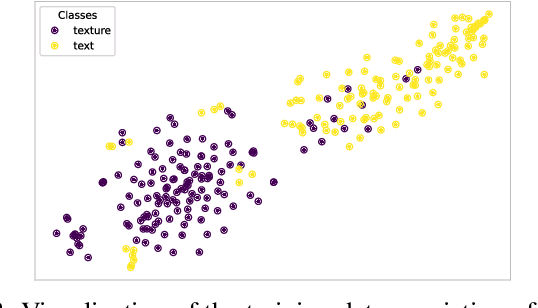

Assuming a known degradation model, the performance of a learned image super-resolution (SR) model depends on how well the variety of image characteristics within the training set matches those in the test set. As a result, the performance of an SR model varies noticeably from image to image over a test set depending on whether characteristics of specific images are similar to those in the training set or not. Hence, in general, a single SR model cannot generalize well enough for all types of image content. In this work, we show that training multiple SR models for different classes of images (e.g., for text, texture, etc.) to exploit class-specific image priors and employing a post-processing network that learns how to best fuse the outputs produced by these multiple SR models surpasses the performance of state-of-the-art generic SR models. Experimental results clearly demonstrate that the proposed multiple-model SR (MMSR) approach significantly outperforms a single pre-trained state-of-the-art SR model both quantitatively and visually. It even exceeds the performance of the best single class-specific SR model trained on similar text or texture images.
Perception-Distortion Trade-off in the SR Space Spanned by Flow Models
Sep 18, 2022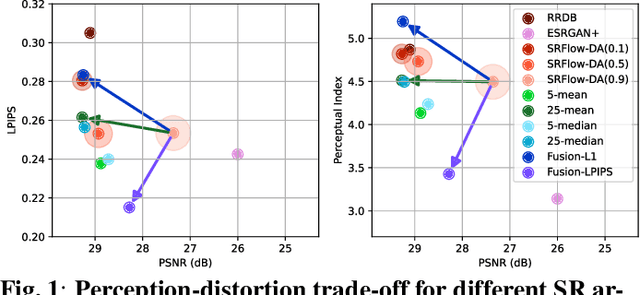
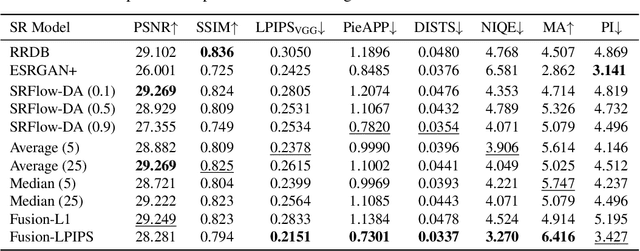


Flow-based generative super-resolution (SR) models learn to produce a diverse set of feasible SR solutions, called the SR space. Diversity of SR solutions increases with the temperature ($\tau$) of latent variables, which introduces random variations of texture among sample solutions, resulting in visual artifacts and low fidelity. In this paper, we present a simple but effective image ensembling/fusion approach to obtain a single SR image eliminating random artifacts and improving fidelity without significantly compromising perceptual quality. We achieve this by benefiting from a diverse set of feasible photo-realistic solutions in the SR space spanned by flow models. We propose different image ensembling and fusion strategies which offer multiple paths to move sample solutions in the SR space to more desired destinations in the perception-distortion plane in a controllable manner depending on the fidelity vs. perceptual quality requirements of the task at hand. Experimental results demonstrate that our image ensembling/fusion strategy achieves more promising perception-distortion trade-off compared to sample SR images produced by flow models and adversarially trained models in terms of both quantitative metrics and visual quality.
Two-stage domain adapted training for better generalization in real-world image restoration and super-resolution
Jun 01, 2021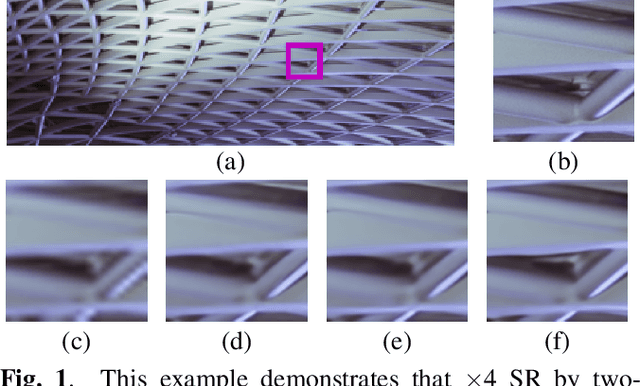



It is well-known that in inverse problems, end-to-end trained networks overfit the degradation model seen in the training set, i.e., they do not generalize to other types of degradations well. Recently, an approach to first map images downsampled by unknown filters to bicubicly downsampled look-alike images was proposed to successfully super-resolve such images. In this paper, we show that any inverse problem can be formulated by first mapping the input degraded images to an intermediate domain, and then training a second network to form output images from these intermediate images. Furthermore, the best intermediate domain may vary according to the task. Our experimental results demonstrate that this two-stage domain-adapted training strategy does not only achieve better results on a given class of unknown degradations but can also generalize to other unseen classes of degradations better.
On the Computation of PSNR for a Set of Images or Video
Apr 30, 2021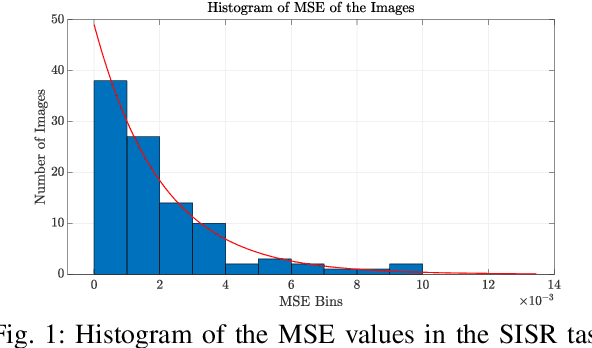
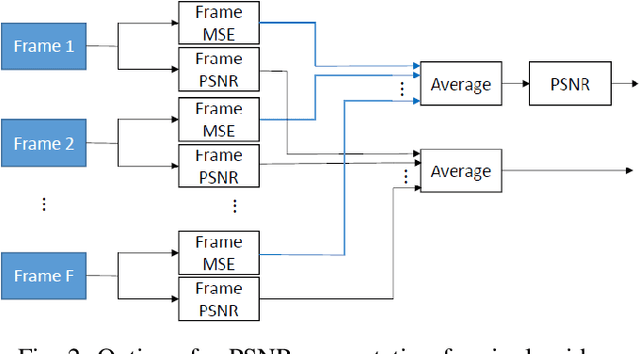
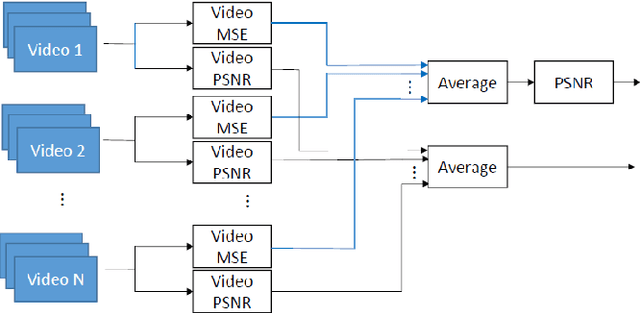
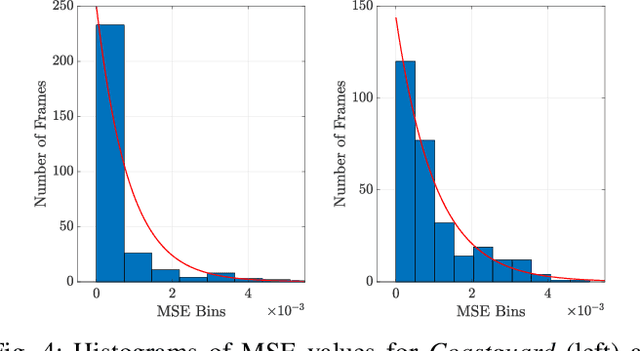
When comparing learned image/video restoration and compression methods, it is common to report peak-signal to noise ratio (PSNR) results. However, there does not exist a generally agreed upon practice to compute PSNR for sets of images or video. Some authors report average of individual image/frame PSNR, which is equivalent to computing a single PSNR from the geometric mean of individual image/frame mean-square error (MSE). Others compute a single PSNR from the arithmetic mean of frame MSEs for each video. Furthermore, some compute the MSE/PSNR of Y-channel only, while others compute MSE/PSNR for RGB channels. This paper investigates different approaches to computing PSNR for sets of images, single video, and sets of video and the relation between them. We show the difference between computing the PSNR based on arithmetic vs. geometric mean of MSE depends on the distribution of MSE over the set of images or video, and that this distribution is task-dependent. In particular, these two methods yield larger differences in restoration problems, where the MSE is exponentially distributed and smaller differences in compression problems, where the MSE distribution is narrower. We hope this paper will motivate the community to clearly describe how they compute reported PSNR values to enable consistent comparison.