 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMSR: Multiple-Model Learned Image Super-Resolution Benefiting From Class-Specific Image Priors
Paper and Code
Sep 18, 2022
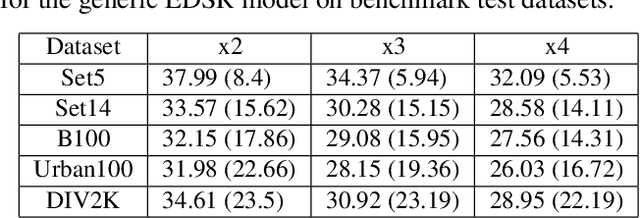
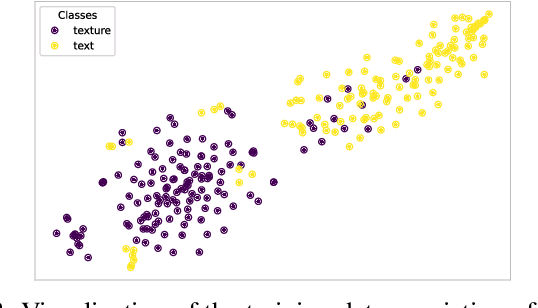

Assuming a known degradation model, the performance of a learned image super-resolution (SR) model depends on how well the variety of image characteristics within the training set matches those in the test set. As a result, the performance of an SR model varies noticeably from image to image over a test set depending on whether characteristics of specific images are similar to those in the training set or not. Hence, in general, a single SR model cannot generalize well enough for all types of image content. In this work, we show that training multiple SR models for different classes of images (e.g., for text, texture, etc.) to exploit class-specific image priors and employing a post-processing network that learns how to best fuse the outputs produced by these multiple SR models surpasses the performance of state-of-the-art generic SR models. Experimental results clearly demonstrate that the proposed multiple-model SR (MMSR) approach significantly outperforms a single pre-trained state-of-the-art SR model both quantitatively and visually. It even exceeds the performance of the best single class-specific SR model trained on similar text or texture images.