 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Beyond the Gaussian Data: Learning Dynamics of Neural Networks on an Expressive and Cumulant-Controllable Data Model
Feb 02, 2026We study the effect of high-order statistics of data on the learning dynamics of neural networks (NNs) by using a moment-controllable non-Gaussian data model. Considering the expressivity of two-layer neural networks, we first construct the data model as a generative two-layer NN where the activation function is expanded by using Hermite polynomials. This allows us to achieve interpretable control over high-order cumulants such as skewness and kurtosis through the Hermite coefficients while keeping the data model realistic. Using samples generated from the data model, we perform controlled online learning experiments with a two-layer NN. Our results reveal a moment-wise progression in training: networks first capture low-order statistics such as mean and covariance, and progressively learn high-order cumulants. Finally, we pretrain the generative model on the Fashion-MNIST dataset and leverage the generated samples for further experiments. The results of these additional experiments confirm our conclusions and show the utility of the data model in a real-world scenario. Overall, our proposed approach bridges simplified data assumptions and practical data complexity, which offers a principled framework for investigating distributional effects in machine learning and signal processing.
How Data Mixing Shapes In-Context Learning: Asymptotic Equivalence for Transformers with MLPs
Oct 29, 2025
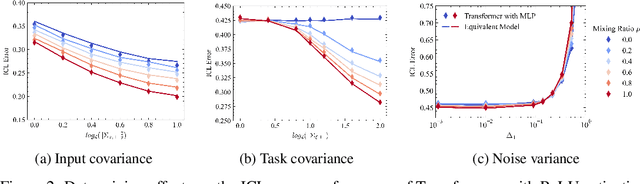

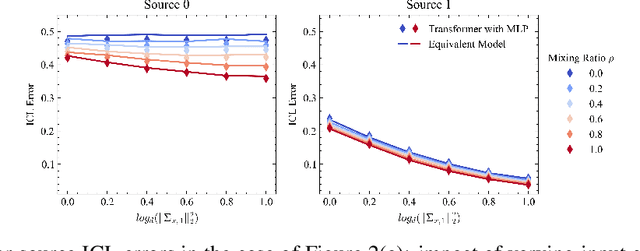
Pretrained Transformers demonstrate remarkable in-context learning (ICL) capabilities, enabling them to adapt to new tasks from demonstrations without parameter updates. However, theoretical studies often rely on simplified architectures (e.g., omitting MLPs), data models (e.g., linear regression with isotropic inputs), and single-source training, limiting their relevance to realistic settings. In this work, we study ICL in pretrained Transformers with nonlinear MLP heads on nonlinear tasks drawn from multiple data sources with heterogeneous input, task, and noise distributions. We analyze a model where the MLP comprises two layers, with the first layer trained via a single gradient step and the second layer fully optimized. Under high-dimensional asymptotics, we prove that such models are equivalent in ICL error to structured polynomial predictors, leveraging results from the theory of Gaussian universality and orthogonal polynomials. This equivalence reveals that nonlinear MLPs meaningfully enhance ICL performance, particularly on nonlinear tasks, compared to linear baselines. It also enables a precise analysis of data mixing effects: we identify key properties of high-quality data sources (low noise, structured covariances) and show that feature learning emerges only when the task covariance exhibits sufficient structure. These results are validated empirically across various activation functions, model sizes, and data distributions. Finally, we experiment with a real-world scenario involving multilingual sentiment analysis where each language is treated as a different source. Our experimental results for this case exemplify how our findings extend to real-world cases. Overall, our work advances the theoretical foundations of ICL in Transformers and provides actionable insight into the role of architecture and data in ICL.
Asymptotic Study of In-context Learning with Random Transformers through Equivalent Models
Sep 18, 2025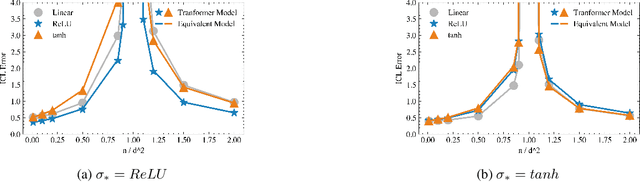
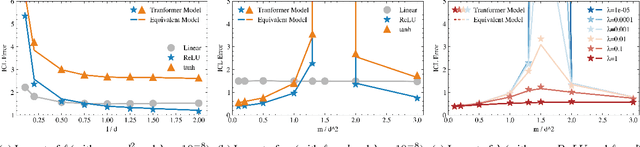
We study the in-context learning (ICL) capabilities of pretrained Transformers in the setting of nonlinear regression. Specifically, we focus on a random Transformer with a nonlinear MLP head where the first layer is randomly initialized and fixed while the second layer is trained. Furthermore, we consider an asymptotic regime where the context length, input dimension, hidden dimension, number of training tasks, and number of training samples jointly grow. In this setting, we show that the random Transformer behaves equivalent to a finite-degree Hermite polynomial model in terms of ICL error. This equivalence is validated through simulations across varying activation functions, context lengths, hidden layer widths (revealing a double-descent phenomenon), and regularization settings. Our results offer theoretical and empirical insights into when and how MLP layers enhance ICL, and how nonlinearity and over-parameterization influence model performance.
Learning Rate Should Scale Inversely with High-Order Data Moments in High-Dimensional Online Independent Component Analysis
Sep 18, 2025We investigate the impact of high-order moments on the learning dynamics of an online Independent Component Analysis (ICA) algorithm under a high-dimensional data model composed of a weighted sum of two non-Gaussian random variables. This model allows precise control of the input moment structure via a weighting parameter. Building on an existing ordinary differential equation (ODE)-based analysis in the high-dimensional limit, we demonstrate that as the high-order moments increase, the algorithm exhibits slower convergence and demands both a lower learning rate and greater initial alignment to achieve informative solutions. Our findings highlight the algorithm's sensitivity to the statistical structure of the input data, particularly its moment characteristics. Furthermore, the ODE framework reveals a critical learning rate threshold necessary for learning when moments approach their maximum. These insights motivate future directions in moment-aware initialization and adaptive learning rate strategies to counteract the degradation in learning speed caused by high non-Gaussianity, thereby enhancing the robustness and efficiency of ICA in complex, high-dimensional settings.
Benefits of Online Tilted Empirical Risk Minimization: A Case Study of Outlier Detection and Robust Regression
Sep 18, 2025


Empirical Risk Minimization (ERM) is a foundational framework for supervised learning but primarily optimizes average-case performance, often neglecting fairness and robustness considerations. Tilted Empirical Risk Minimization (TERM) extends ERM by introducing an exponential tilt hyperparameter $t$ to balance average-case accuracy with worst-case fairness and robustness. However, in online or streaming settings where data arrive one sample at a time, the classical TERM objective degenerates to standard ERM, losing tilt sensitivity. We address this limitation by proposing an online TERM formulation that removes the logarithm from the classical objective, preserving tilt effects without additional computational or memory overhead. This formulation enables a continuous trade-off controlled by $t$, smoothly interpolating between ERM ($t \to 0$), fairness emphasis ($t > 0$), and robustness to outliers ($t < 0$). We empirically validate online TERM on two representative streaming tasks: robust linear regression with adversarial outliers and minority-class detection in binary classification. Our results demonstrate that negative tilting effectively suppresses outlier influence, while positive tilting improves recall with minimal impact on precision, all at per-sample computational cost equivalent to ERM. Online TERM thus recovers the full robustness-fairness spectrum of classical TERM in an efficient single-sample learning regime.
Leveraging Vision-Language Models to Select Trustworthy Super-Resolution Samples Generated by Diffusion Models
Jun 25, 2025Super-resolution (SR) is an ill-posed inverse problem with many feasible solutions consistent with a given low-resolution image. On one hand, regressive SR models aim to balance fidelity and perceptual quality to yield a single solution, but this trade-off often introduces artifacts that create ambiguity in information-critical applications such as recognizing digits or letters. On the other hand, diffusion models generate a diverse set of SR images, but selecting the most trustworthy solution from this set remains a challenge. This paper introduces a robust, automated framework for identifying the most trustworthy SR sample from a diffusion-generated set by leveraging the semantic reasoning capabilities of vision-language models (VLMs). Specifically, VLMs such as BLIP-2, GPT-4o, and their variants are prompted with structured queries to assess semantic correctness, visual quality, and artifact presence. The top-ranked SR candidates are then ensembled to yield a single trustworthy output in a cost-effective manner. To rigorously assess the validity of VLM-selected samples, we propose a novel Trustworthiness Score (TWS) a hybrid metric that quantifies SR reliability based on three complementary components: semantic similarity via CLIP embeddings, structural integrity using SSIM on edge maps, and artifact sensitivity through multi-level wavelet decomposition. We empirically show that TWS correlates strongly with human preference in both ambiguous and natural images, and that VLM-guided selections consistently yield high TWS values. Compared to conventional metrics like PSNR, LPIPS, which fail to reflect information fidelity, our approach offers a principled, scalable, and generalizable solution for navigating the uncertainty of the diffusion SR space. By aligning outputs with human expectations and semantic correctness, this work sets a new benchmark for trustworthiness in generative SR.
Exploring the Precise Dynamics of Single-Layer GAN Models: Leveraging Multi-Feature Discriminators for High-Dimensional Subspace Learning
Nov 01, 2024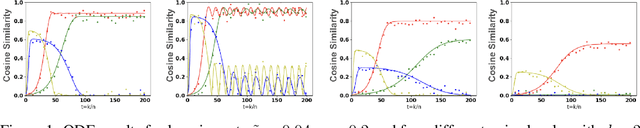
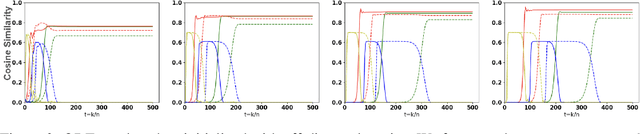
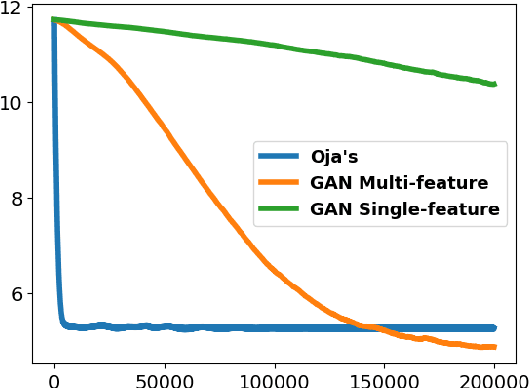

Subspace learning is a critical endeavor in contemporary machine learning, particularly given the vast dimensions of modern datasets. In this study, we delve into the training dynamics of a single-layer GAN model from the perspective of subspace learning, framing these GANs as a novel approach to this fundamental task. Through a rigorous scaling limit analysis, we offer insights into the behavior of this model. Extending beyond prior research that primarily focused on sequential feature learning, we investigate the non-sequential scenario, emphasizing the pivotal role of inter-feature interactions in expediting training and enhancing performance, particularly with an uninformed initialization strategy. Our investigation encompasses both synthetic and real-world datasets, such as MNIST and Olivetti Faces, demonstrating the robustness and applicability of our findings to practical scenarios. By bridging our analysis to the realm of subspace learning, we systematically compare the efficacy of GAN-based methods against conventional approaches, both theoretically and empirically. Notably, our results unveil that while all methodologies successfully capture the underlying subspace, GANs exhibit a remarkable capability to acquire a more informative basis, owing to their intrinsic ability to generate new data samples. This elucidates the unique advantage of GAN-based approaches in subspace learning tasks.
Random Features Outperform Linear Models: Effect of Strong Input-Label Correlation in Spiked Covariance Data
Sep 30, 2024



Random Feature Model (RFM) with a nonlinear activation function is instrumental in understanding training and generalization performance in high-dimensional learning. While existing research has established an asymptotic equivalence in performance between the RFM and noisy linear models under isotropic data assumptions, empirical observations indicate that the RFM frequently surpasses linear models in practical applications. To address this gap, we ask, "When and how does the RFM outperform linear models?" In practice, inputs often have additional structures that significantly influence learning. Therefore, we explore the RFM under anisotropic input data characterized by spiked covariance in the proportional asymptotic limit, where dimensions diverge jointly while maintaining finite ratios. Our analysis reveals that a high correlation between inputs and labels is a critical factor enabling the RFM to outperform linear models. Moreover, we show that the RFM performs equivalent to noisy polynomial models, where the polynomial degree depends on the strength of the correlation between inputs and labels. Our numerical simulations validate these theoretical insights, confirming the performance-wise superiority of RFM in scenarios characterized by strong input-label correlation.
Training Generative Image Super-Resolution Models by Wavelet-Domain Losses Enables Better Control of Artifacts
Feb 29, 2024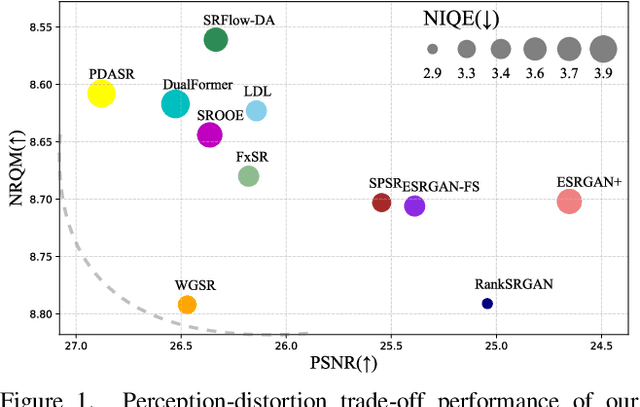
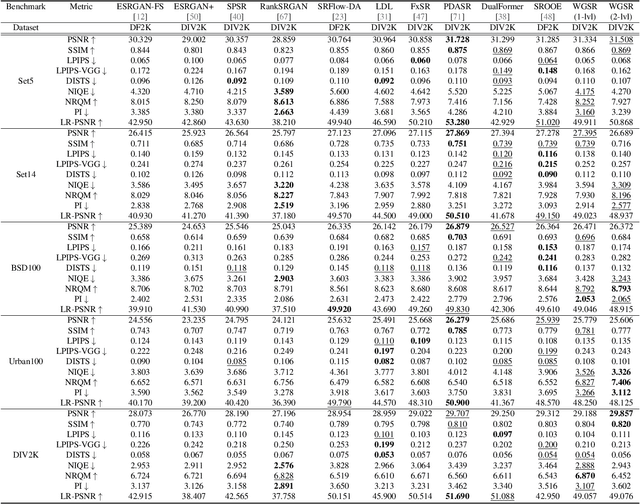

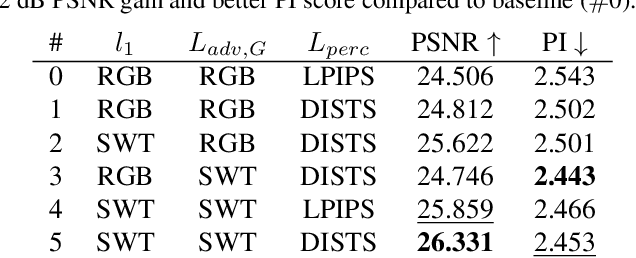
Super-resolution (SR) is an ill-posed inverse problem, where the size of the set of feasible solutions that are consistent with a given low-resolution image is very large. Many algorithms have been proposed to find a "good" solution among the feasible solutions that strike a balance between fidelity and perceptual quality. Unfortunately, all known methods generate artifacts and hallucinations while trying to reconstruct high-frequency (HF) image details. A fundamental question is: Can a model learn to distinguish genuine image details from artifacts? Although some recent works focused on the differentiation of details and artifacts, this is a very challenging problem and a satisfactory solution is yet to be found. This paper shows that the characterization of genuine HF details versus artifacts can be better learned by training GAN-based SR models using wavelet-domain loss functions compared to RGB-domain or Fourier-space losses. Although wavelet-domain losses have been used in the literature before, they have not been used in the context of the SR task. More specifically, we train the discriminator only on the HF wavelet sub-bands instead of on RGB images and the generator is trained by a fidelity loss over wavelet subbands to make it sensitive to the scale and orientation of structures. Extensive experimental results demonstrate that our model achieves better perception-distortion trade-off according to multiple objective measures and visual evaluations.
Trustworthy SR: Resolving Ambiguity in Image Super-resolution via Diffusion Models and Human Feedback
Feb 12, 2024



Super-resolution (SR) is an ill-posed inverse problem with a large set of feasible solutions that are consistent with a given low-resolution image. Various deterministic algorithms aim to find a single solution that balances fidelity and perceptual quality; however, this trade-off often causes visual artifacts that bring ambiguity in information-centric applications. On the other hand, diffusion models (DMs) excel in generating a diverse set of feasible SR images that span the solution space. The challenge is then how to determine the most likely solution among this set in a trustworthy manner. We observe that quantitative measures, such as PSNR, LPIPS, DISTS, are not reliable indicators to resolve ambiguous cases. To this effect, we propose employing human feedback, where we ask human subjects to select a small number of likely samples and we ensemble the averages of selected samples. This strategy leverages the high-quality image generation capabilities of DMs, while recognizing the importance of obtaining a single trustworthy solution, especially in use cases, such as identification of specific digits or letters, where generating multiple feasible solutions may not lead to a reliable outcome. Experimental results demonstrate that our proposed strategy provides more trustworthy solutions when compared to state-of-the art SR methods.