 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePadé Neurons for Efficient Neural Models
Jan 07, 2026Neural networks commonly employ the McCulloch-Pitts neuron model, which is a linear model followed by a point-wise non-linear activation. Various researchers have already advanced inherently non-linear neuron models, such as quadratic neurons, generalized operational neurons, generative neurons, and super neurons, which offer stronger non-linearity compared to point-wise activation functions. In this paper, we introduce a novel and better non-linear neuron model called Padé neurons (Paons), inspired by Padé approximants. Paons offer several advantages, such as diversity of non-linearity, since each Paon learns a different non-linear function of its inputs, and layer efficiency, since Paons provide stronger non-linearity in much fewer layers compared to piecewise linear approximation. Furthermore, Paons include all previously proposed neuron models as special cases, thus any neuron model in any network can be replaced by Paons. We note that there has been a proposal to employ the Padé approximation as a generalized point-wise activation function, which is fundamentally different from our model. To validate the efficacy of Paons, in our experiments, we replace classic neurons in some well-known neural image super-resolution, compression, and classification models based on the ResNet architecture with Paons. Our comprehensive experimental results and analyses demonstrate that neural models built by Paons provide better or equal performance than their classic counterparts with a smaller number of layers. The PyTorch implementation code for Paon is open-sourced at https://github.com/onur-keles/Paon.
On the Computation of BD-Rate over a Set of Videos for Fair Assessment of Performance of Learned Video Codecs
Sep 13, 2024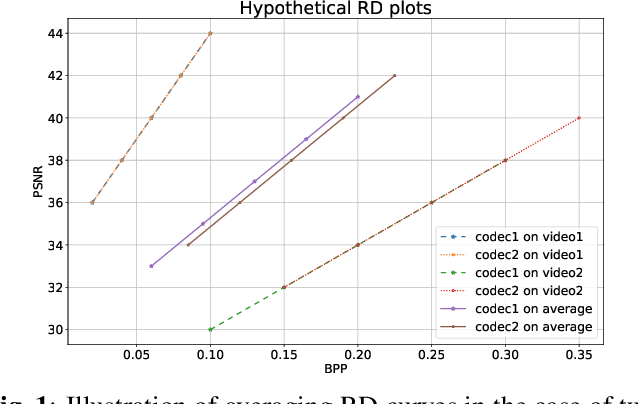
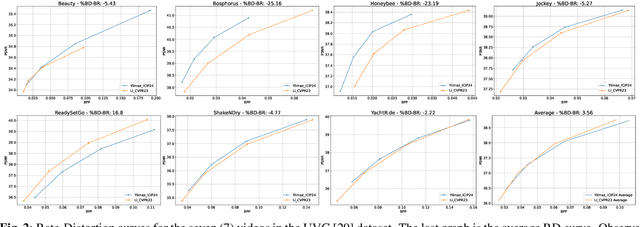
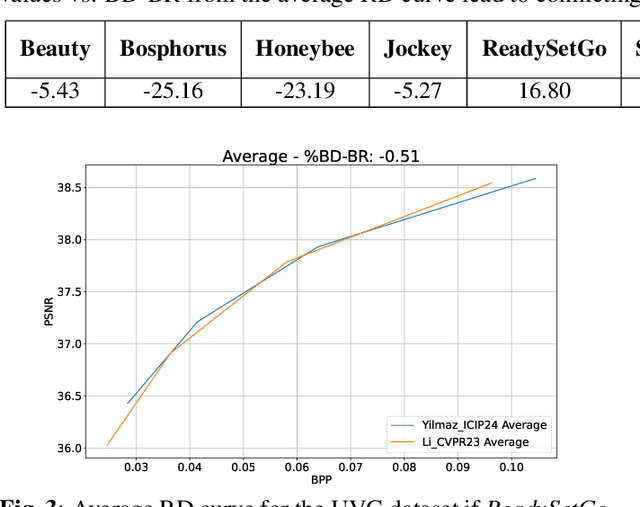
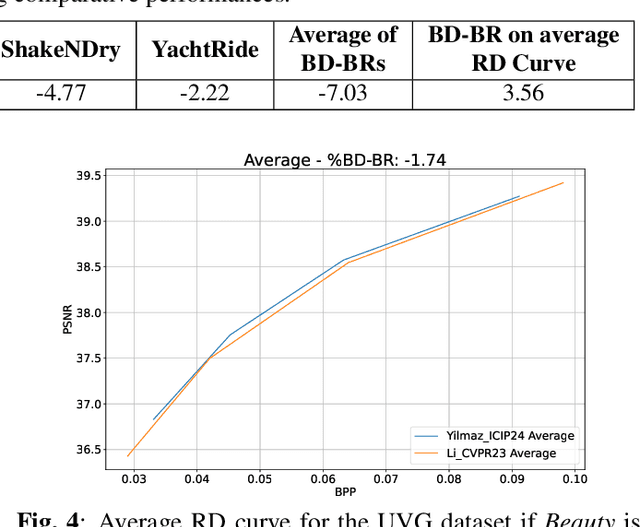
The Bj{\o}ntegaard Delta (BD) measure is widely employed to evaluate and quantify the variations in the rate-distortion(RD) performance across different codecs. Many researchers report the average BD value over multiple videos within a dataset for different codecs. We claim that the current practice in the learned video compression community of computing the average BD value over a dataset based on the average RD curve of multiple videos can lead to misleading conclusions. We show both by analysis of a simplistic case of linear RD curves and experimental results with two recent learned video codecs that averaging RD curves can lead to a single video to disproportionately influence the average BD value especially when the operating bitrate range of different codecs do not exactly match. Instead, we advocate for calculating the BD measure per-video basis, as commonly done by the traditional video compression community, followed by averaging the individual BD values over videos, to provide a fair comparison of learned video codecs. Our experimental results demonstrate that the comparison of two recent learned video codecs is affected by how we evaluate the average BD measure.
PAON: A New Neuron Model using Padé Approximants
Mar 18, 2024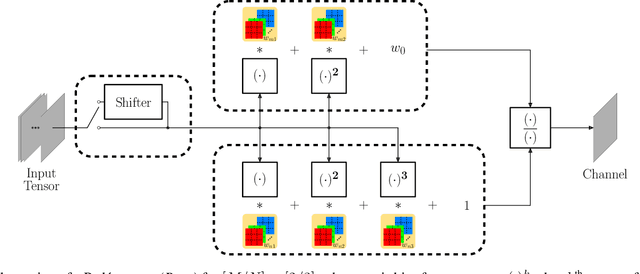

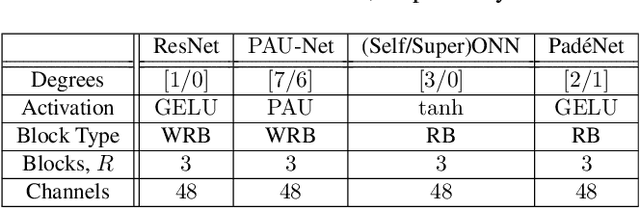
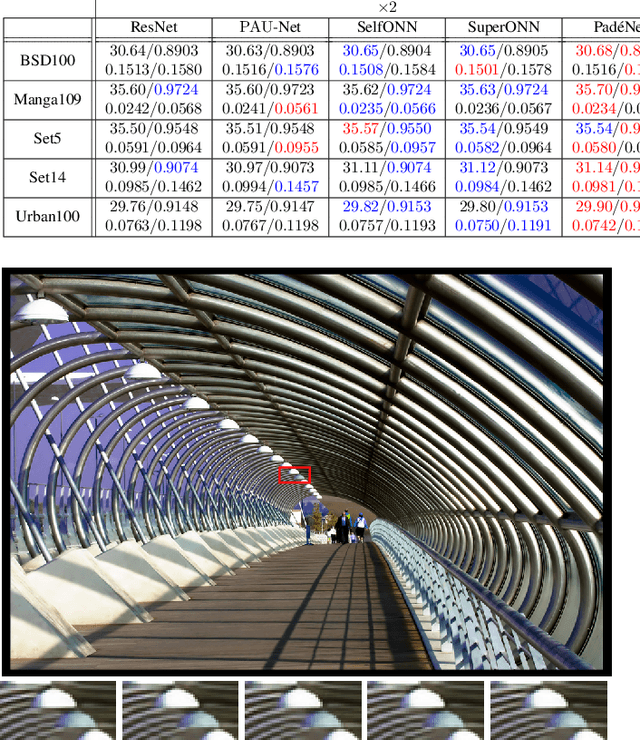
Convolutional neural networks (CNN) are built upon the classical McCulloch-Pitts neuron model, which is essentially a linear model, where the nonlinearity is provided by a separate activation function. Several researchers have proposed enhanced neuron models, including quadratic neurons, generalized operational neurons, generative neurons, and super neurons, with stronger nonlinearity than that provided by the pointwise activation function. There has also been a proposal to use Pade approximation as a generalized activation function. In this paper, we introduce a brand new neuron model called Pade neurons (Paons), inspired by the Pade approximants, which is the best mathematical approximation of a transcendental function as a ratio of polynomials with different orders. We show that Paons are a super set of all other proposed neuron models. Hence, the basic neuron in any known CNN model can be replaced by Paons. In this paper, we extend the well-known ResNet to PadeNet (built by Paons) to demonstrate the concept. Our experiments on the single-image super-resolution task show that PadeNets can obtain better results than competing architectures.
Self-Organized Residual Blocks for Image Super-Resolution
May 31, 2021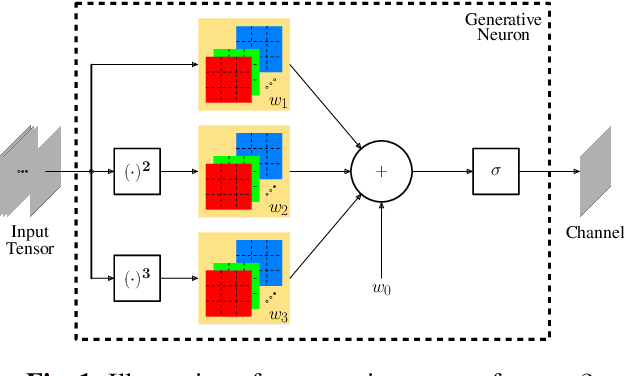
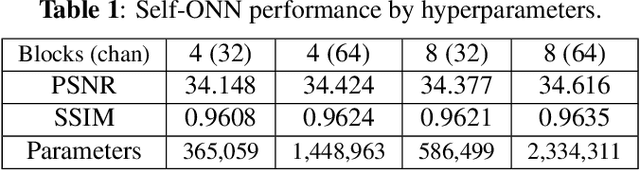
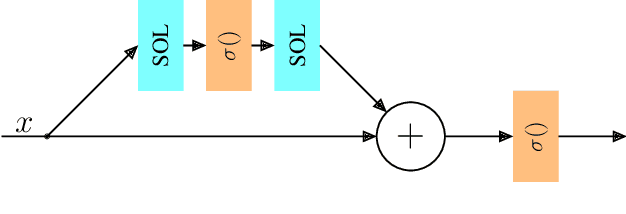
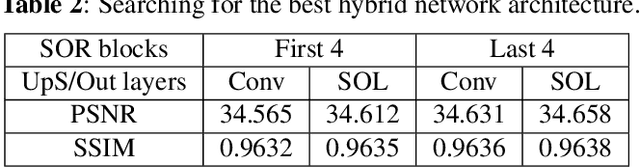
It has become a standard practice to use the convolutional networks (ConvNet) with RELU non-linearity in image restoration and super-resolution (SR). Although the universal approximation theorem states that a multi-layer neural network can approximate any non-linear function with the desired precision, it does not reveal the best network architecture to do so. Recently, operational neural networks (ONNs) that choose the best non-linearity from a set of alternatives, and their "self-organized" variants (Self-ONN) that approximate any non-linearity via Taylor series have been proposed to address the well-known limitations and drawbacks of conventional ConvNets such as network homogeneity using only the McCulloch-Pitts neuron model. In this paper, we propose the concept of self-organized operational residual (SOR) blocks, and present hybrid network architectures combining regular residual and SOR blocks to strike a balance between the benefits of stronger non-linearity and the overall number of parameters. The experimental results demonstrate that the~proposed architectures yield performance improvements in both PSNR and perceptual metrics.
Self-Organized Variational Autoencoders (Self-VAE) for Learned Image Compression
May 28, 2021
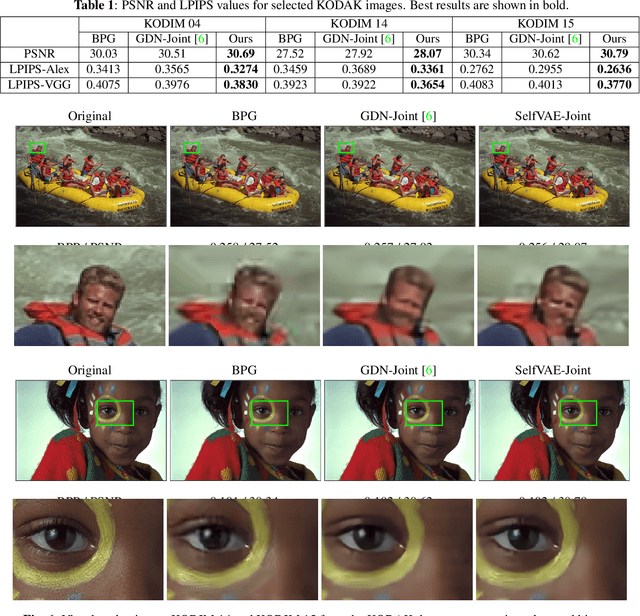
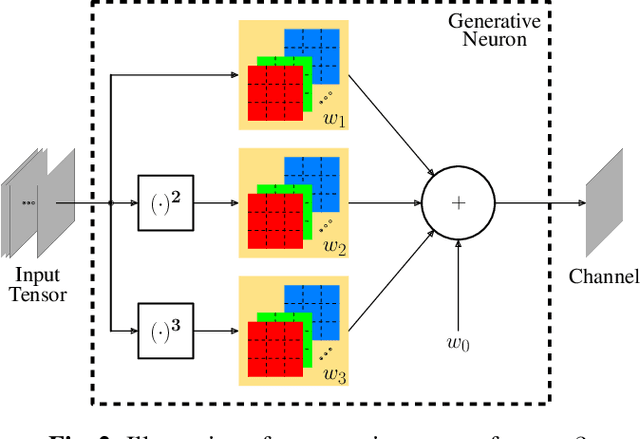
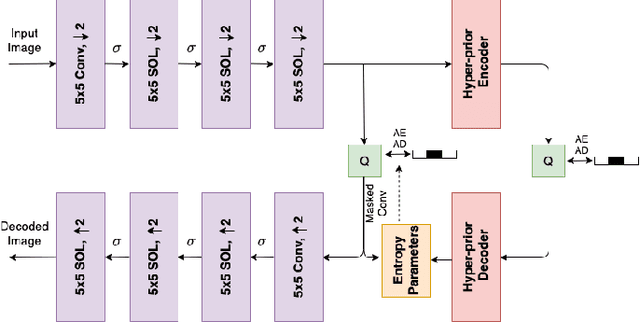
In end-to-end optimized learned image compression, it is standard practice to use a convolutional variational autoencoder with generalized divisive normalization (GDN) to transform images into a latent space. Recently, Operational Neural Networks (ONNs) that learn the best non-linearity from a set of alternatives, and their self-organized variants, Self-ONNs, that approximate any non-linearity via Taylor series have been proposed to address the limitations of convolutional layers and a fixed nonlinear activation. In this paper, we propose to replace the convolutional and GDN layers in the variational autoencoder with self-organized operational layers, and propose a novel self-organized variational autoencoder (Self-VAE) architecture that benefits from stronger non-linearity. The experimental results demonstrate that the proposed Self-VAE yields improvements in both rate-distortion performance and perceptual image quality.
On the Computation of PSNR for a Set of Images or Video
Apr 30, 2021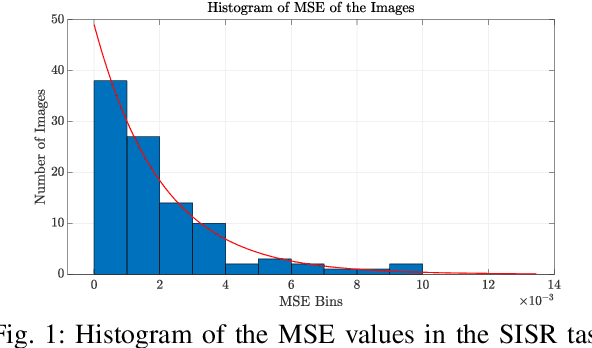
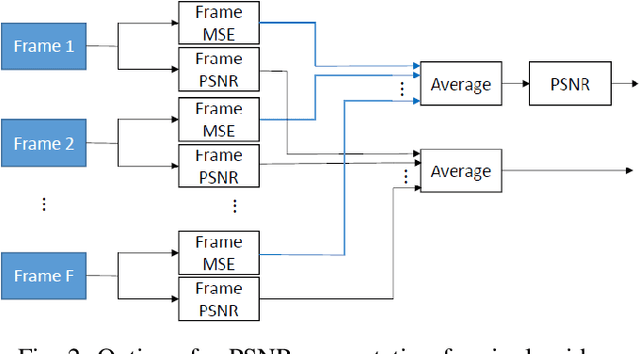
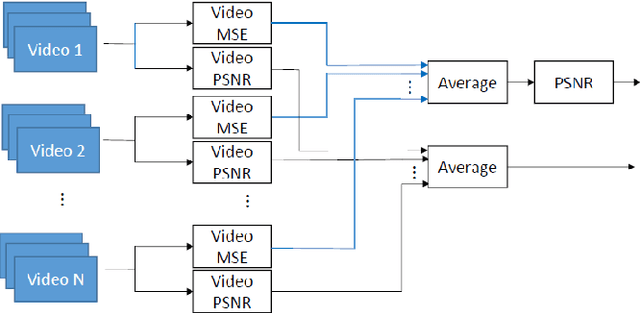
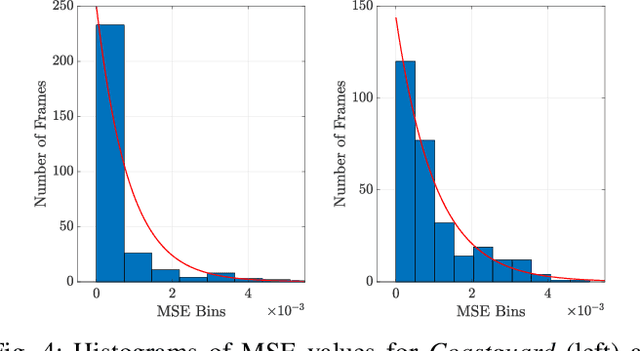
When comparing learned image/video restoration and compression methods, it is common to report peak-signal to noise ratio (PSNR) results. However, there does not exist a generally agreed upon practice to compute PSNR for sets of images or video. Some authors report average of individual image/frame PSNR, which is equivalent to computing a single PSNR from the geometric mean of individual image/frame mean-square error (MSE). Others compute a single PSNR from the arithmetic mean of frame MSEs for each video. Furthermore, some compute the MSE/PSNR of Y-channel only, while others compute MSE/PSNR for RGB channels. This paper investigates different approaches to computing PSNR for sets of images, single video, and sets of video and the relation between them. We show the difference between computing the PSNR based on arithmetic vs. geometric mean of MSE depends on the distribution of MSE over the set of images or video, and that this distribution is task-dependent. In particular, these two methods yield larger differences in restoration problems, where the MSE is exponentially distributed and smaller differences in compression problems, where the MSE distribution is narrower. We hope this paper will motivate the community to clearly describe how they compute reported PSNR values to enable consistent comparison.