 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiMoSR: Feature Modulation via Multi-Branch Dilated Convolutions for Efficient Image Super-Resolution
May 27, 2025Balancing reconstruction quality versus model efficiency remains a critical challenge in lightweight single image super-resolution (SISR). Despite the prevalence of attention mechanisms in recent state-of-the-art SISR approaches that primarily emphasize or suppress feature maps, alternative architectural paradigms warrant further exploration. This paper introduces DiMoSR (Dilated Modulation Super-Resolution), a novel architecture that enhances feature representation through modulation to complement attention in lightweight SISR networks. The proposed approach leverages multi-branch dilated convolutions to capture rich contextual information over a wider receptive field while maintaining computational efficiency. Experimental results demonstrate that DiMoSR outperforms state-of-the-art lightweight methods across diverse benchmark datasets, achieving superior PSNR and SSIM metrics with comparable or reduced computational complexity. Through comprehensive ablation studies, this work not only validates the effectiveness of DiMoSR but also provides critical insights into the interplay between attention mechanisms and feature modulation to guide future research in efficient network design. The code and model weights to reproduce our results are available at: https://github.com/makinyilmaz/DiMoSR
On the Computation of BD-Rate over a Set of Videos for Fair Assessment of Performance of Learned Video Codecs
Sep 13, 2024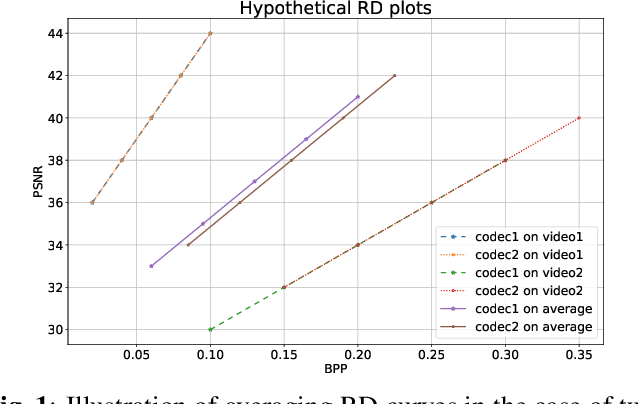
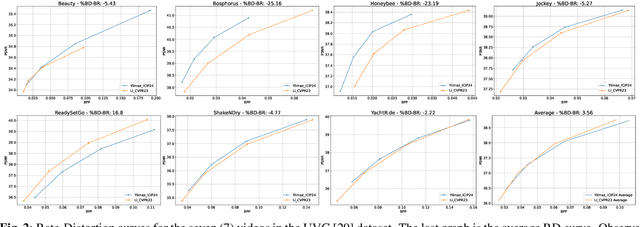
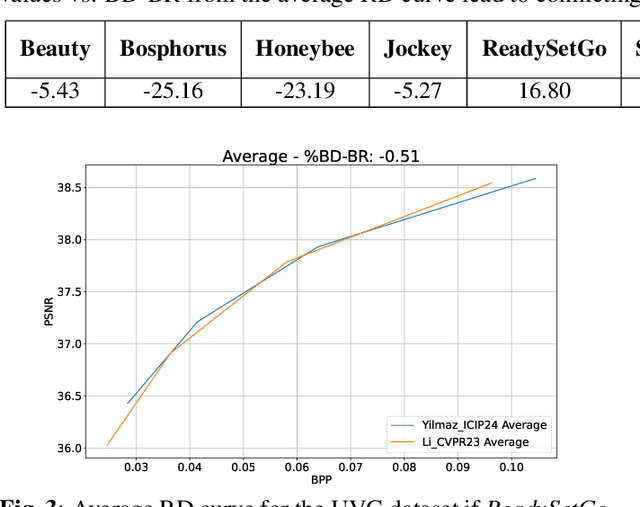
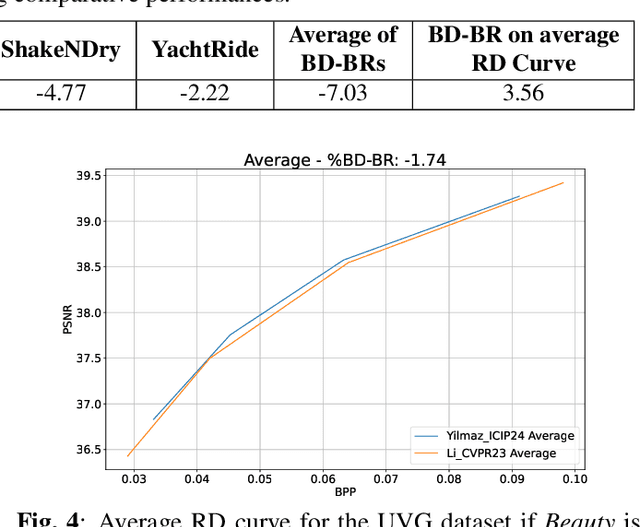
The Bj{\o}ntegaard Delta (BD) measure is widely employed to evaluate and quantify the variations in the rate-distortion(RD) performance across different codecs. Many researchers report the average BD value over multiple videos within a dataset for different codecs. We claim that the current practice in the learned video compression community of computing the average BD value over a dataset based on the average RD curve of multiple videos can lead to misleading conclusions. We show both by analysis of a simplistic case of linear RD curves and experimental results with two recent learned video codecs that averaging RD curves can lead to a single video to disproportionately influence the average BD value especially when the operating bitrate range of different codecs do not exactly match. Instead, we advocate for calculating the BD measure per-video basis, as commonly done by the traditional video compression community, followed by averaging the individual BD values over videos, to provide a fair comparison of learned video codecs. Our experimental results demonstrate that the comparison of two recent learned video codecs is affected by how we evaluate the average BD measure.
Motion-Adaptive Inference for Flexible Learned B-Frame Compression
Feb 13, 2024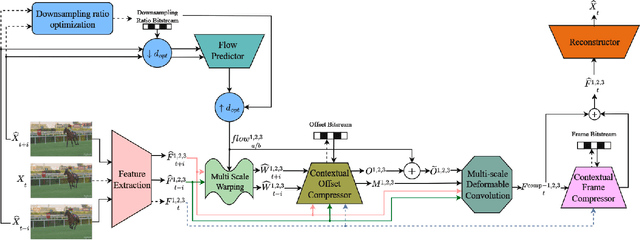
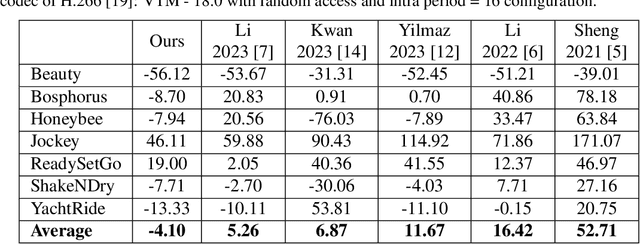

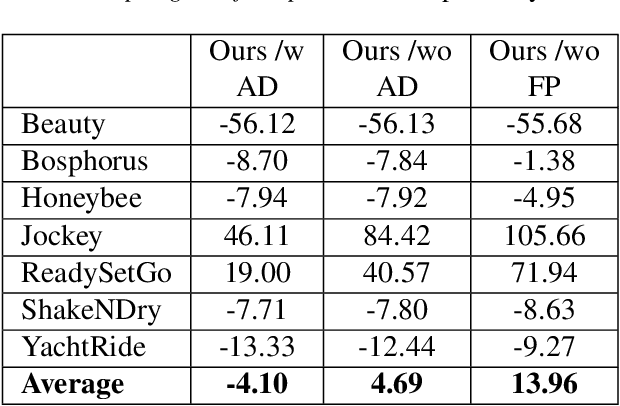
While the performance of recent learned intra and sequential video compression models exceed that of respective traditional codecs, the performance of learned B-frame compression models generally lag behind traditional B-frame coding. The performance gap is bigger for complex scenes with large motions. This is related to the fact that the distance between the past and future references vary in hierarchical B-frame compression depending on the level of hierarchy, which causes motion range to vary. The inability of a single B-frame compression model to adapt to various motion ranges causes loss of performance. As a remedy, we propose controlling the motion range for flow prediction during inference (to approximately match the range of motions in the training data) by downsampling video frames adaptively according to amount of motion and level of hierarchy in order to compress all B-frames using a single flexible-rate model. We present state-of-the-art BD rate results to demonstrate the superiority of our proposed single-model motion-adaptive inference approach to all existing learned B-frame compression models.
Flexible-Rate Learned Hierarchical Bi-Directional Video Compression With Motion Refinement and Frame-Level Bit Allocation
Jun 27, 2022



This paper presents improvements and novel additions to our recent work on end-to-end optimized hierarchical bi-directional video compression to further advance the state-of-the-art in learned video compression. As an improvement, we combine motion estimation and prediction modules and compress refined residual motion vectors for improved rate-distortion performance. As novel addition, we adapted the gain unit proposed for image compression to flexible-rate video compression in two ways: first, the gain unit enables a single encoder model to operate at multiple rate-distortion operating points; second, we exploit the gain unit to control bit allocation among intra-coded vs. bi-directionally coded frames by fine tuning corresponding models for truly flexible-rate learned video coding. Experimental results demonstrate that we obtain state-of-the-art rate-distortion performance exceeding those of all prior art in learned video coding.
Effect of Architectures and Training Methods on the Performance of Learned Video Frame Prediction
Aug 13, 2020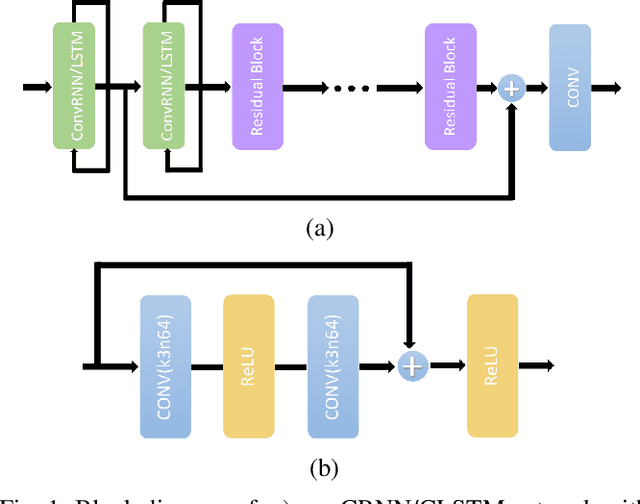
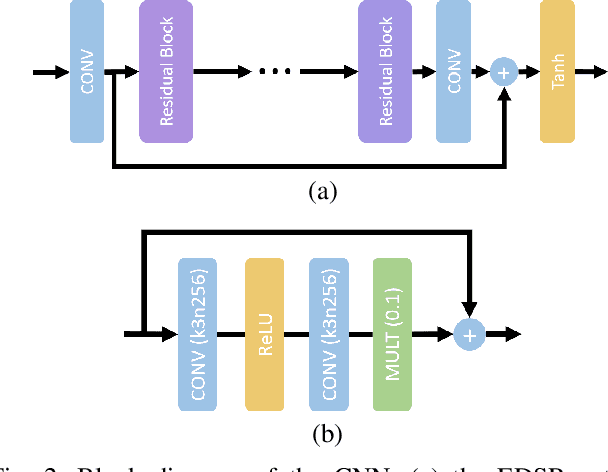
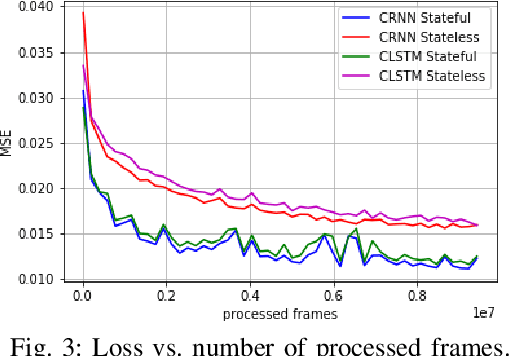
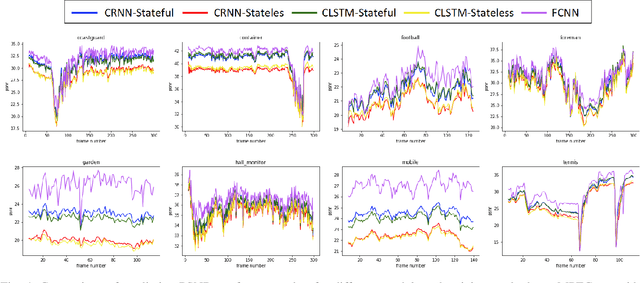
We analyze the performance of feedforward vs. recurrent neural network (RNN) architectures and associated training methods for learned frame prediction. To this effect, we trained a residual fully convolutional neural network (FCNN), a convolutional RNN (CRNN), and a convolutional long short-term memory (CLSTM) network for next frame prediction using the mean square loss. We performed both stateless and stateful training for recurrent networks. Experimental results show that the residual FCNN architecture performs the best in terms of peak signal to noise ratio (PSNR) at the expense of higher training and test (inference) computational complexity. The CRNN can be trained stably and very efficiently using the stateful truncated backpropagation through time procedure, and it requires an order of magnitude less inference runtime to achieve near real-time frame prediction with an acceptable performance.
End-to-End Rate-Distortion Optimization for Bi-Directional Learned Video Compression
Aug 11, 2020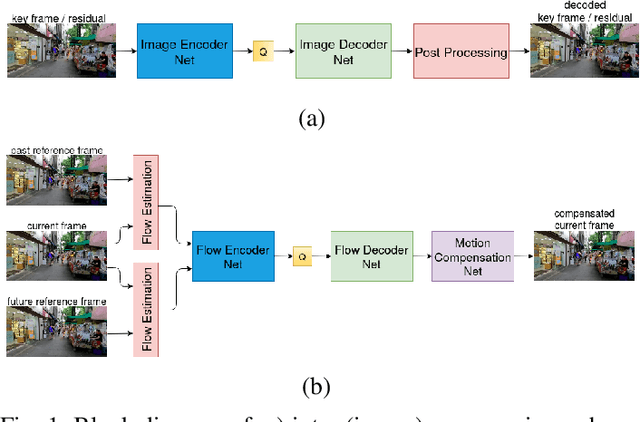
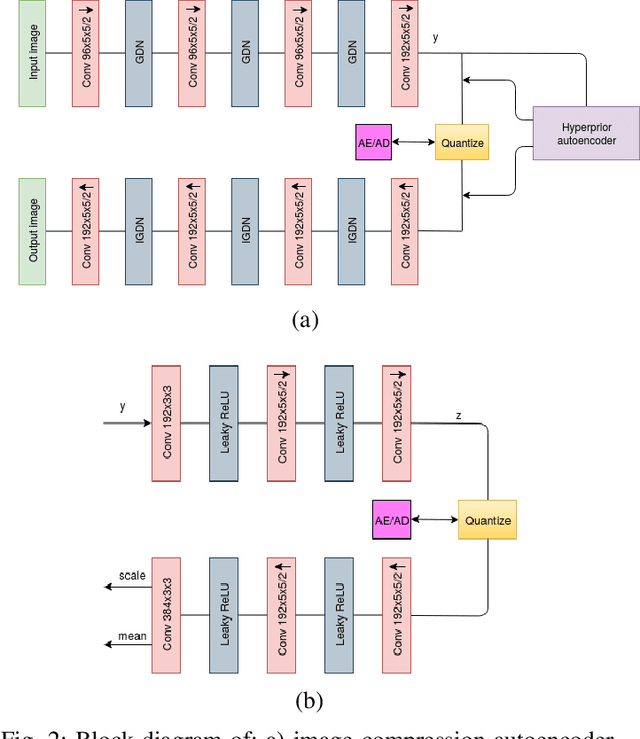
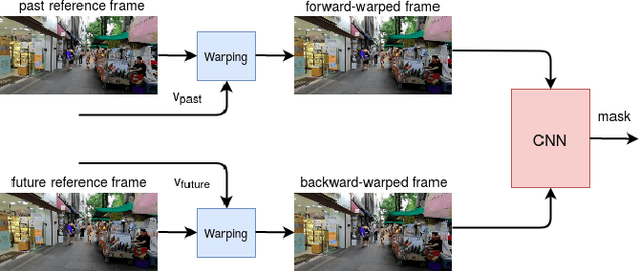
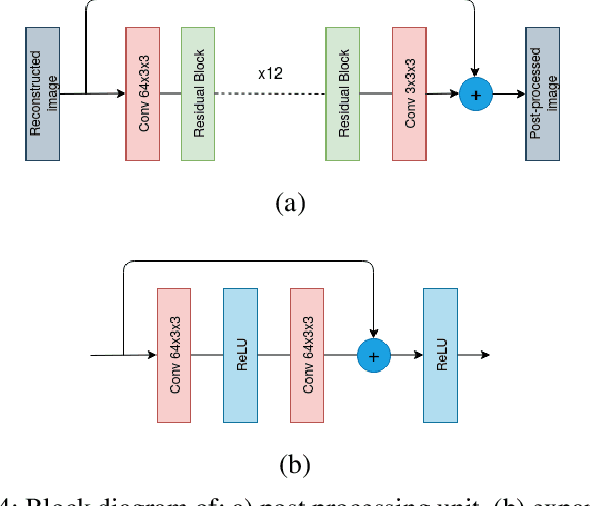
Conventional video compression methods employ a linear transform and block motion model, and the steps of motion estimation, mode and quantization parameter selection, and entropy coding are optimized individually due to combinatorial nature of the end-to-end optimization problem. Learned video compression allows end-to-end rate-distortion optimized training of all nonlinear modules, quantization parameter and entropy model simultaneously. While previous work on learned video compression considered training a sequential video codec based on end-to-end optimization of cost averaged over pairs of successive frames, it is well-known in conventional video compression that hierarchical, bi-directional coding outperforms sequential compression. In this paper, we propose for the first time end-to-end optimization of a hierarchical, bi-directional motion compensated learned codec by accumulating cost function over fixed-size groups of pictures (GOP). Experimental results show that the rate-distortion performance of our proposed learned bi-directional {\it GOP coder} outperforms the state-of-the-art end-to-end optimized learned sequential compression as expected.