 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotion-Adaptive Inference for Flexible Learned B-Frame Compression
Feb 13, 2024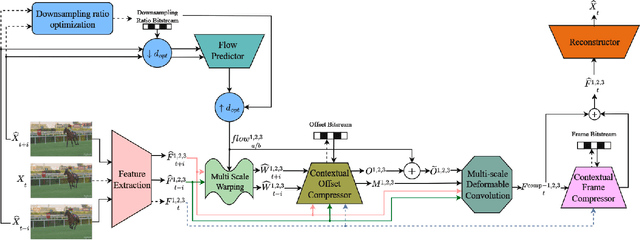
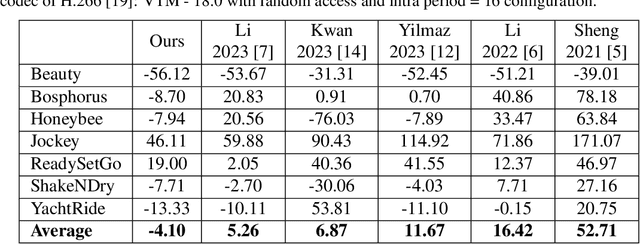

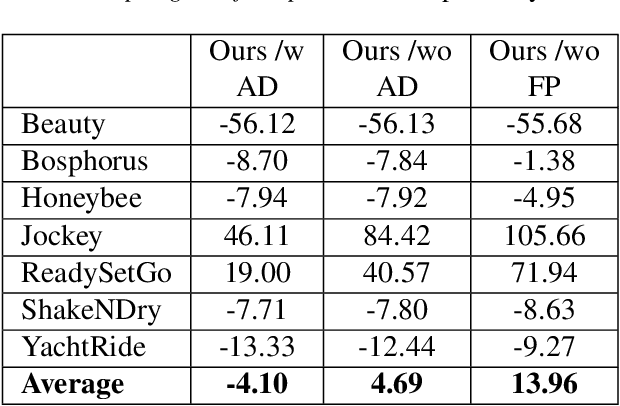
While the performance of recent learned intra and sequential video compression models exceed that of respective traditional codecs, the performance of learned B-frame compression models generally lag behind traditional B-frame coding. The performance gap is bigger for complex scenes with large motions. This is related to the fact that the distance between the past and future references vary in hierarchical B-frame compression depending on the level of hierarchy, which causes motion range to vary. The inability of a single B-frame compression model to adapt to various motion ranges causes loss of performance. As a remedy, we propose controlling the motion range for flow prediction during inference (to approximately match the range of motions in the training data) by downsampling video frames adaptively according to amount of motion and level of hierarchy in order to compress all B-frames using a single flexible-rate model. We present state-of-the-art BD rate results to demonstrate the superiority of our proposed single-model motion-adaptive inference approach to all existing learned B-frame compression models.
Multi-Scale Deformable Alignment and Content-Adaptive Inference for Flexible-Rate Bi-Directional Video Compression
Jun 28, 2023The lack of ability to adapt the motion compensation model to video content is an important limitation of current end-to-end learned video compression models. This paper advances the state-of-the-art by proposing an adaptive motion-compensation model for end-to-end rate-distortion optimized hierarchical bi-directional video compression. In particular, we propose two novelties: i) a multi-scale deformable alignment scheme at the feature level combined with multi-scale conditional coding, ii) motion-content adaptive inference. In addition, we employ a gain unit, which enables a single model to operate at multiple rate-distortion operating points. We also exploit the gain unit to control bit allocation among intra-coded vs. bi-directionally coded frames by fine tuning corresponding models for truly flexible-rate learned video coding. Experimental results demonstrate state-of-the-art rate-distortion performance exceeding those of all prior art in learned video coding.