 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEdit2Restore:Few-Shot Image Restoration via Parameter-Efficient Adaptation of Pre-trained Editing Models
Jan 06, 2026Image restoration has traditionally required training specialized models on thousands of paired examples per degradation type. We challenge this paradigm by demonstrating that powerful pre-trained text-conditioned image editing models can be efficiently adapted for multiple restoration tasks through parameter-efficient fine-tuning with remarkably few examples. Our approach fine-tunes LoRA adapters on FLUX.1 Kontext, a state-of-the-art 12B parameter flow matching model for image-to-image translation, using only 16-128 paired images per task, guided by simple text prompts that specify the restoration operation. Unlike existing methods that train specialized restoration networks from scratch with thousands of samples, we leverage the rich visual priors already encoded in large-scale pre-trained editing models, dramatically reducing data requirements while maintaining high perceptual quality. A single unified LoRA adapter, conditioned on task-specific text prompts, effectively handles multiple degradations including denoising, deraining, and dehazing. Through comprehensive ablation studies, we analyze: (i) the impact of training set size on restoration quality, (ii) trade-offs between task-specific versus unified multi-task adapters, (iii) the role of text encoder fine-tuning, and (iv) zero-shot baseline performance. While our method prioritizes perceptual quality over pixel-perfect reconstruction metrics like PSNR/SSIM, our results demonstrate that pre-trained image editing models, when properly adapted, offer a compelling and data-efficient alternative to traditional image restoration approaches, opening new avenues for few-shot, prompt-guided image enhancement. The code to reproduce our results are available at: https://github.com/makinyilmaz/Edit2Restore
Content-Adaptive Inference for State-of-the-art Learned Video Compression
Oct 08, 2025While the BD-rate performance of recent learned video codec models in both low-delay and random-access modes exceed that of respective modes of traditional codecs on average over common benchmarks, the performance improvements for individual videos with complex/large motions is much smaller compared to scenes with simple motion. This is related to the inability of a learned encoder model to generalize to motion vector ranges that have not been seen in the training set, which causes loss of performance in both coding of flow fields as well as frame prediction and coding. As a remedy, we propose a generic (model-agnostic) framework to control the scale of motion vectors in a scene during inference (encoding) to approximately match the range of motion vectors in the test and training videos by adaptively downsampling frames. This results in down-scaled motion vectors enabling: i) better flow estimation; hence, frame prediction and ii) more efficient flow compression. We show that the proposed framework for content-adaptive inference improves the BD-rate performance of already state-of-the-art low-delay video codec DCVC-FM by up to 41\% on individual videos without any model fine tuning. We present ablation studies to show measures of motion and scene complexity can be used to predict the effectiveness of the proposed framework.
Exploring Sparsity for Parameter Efficient Fine Tuning Using Wavelets
May 18, 2025Efficiently adapting large foundation models is critical, especially with tight compute and memory budgets. Parameter-Efficient Fine-Tuning (PEFT) methods such as LoRA offer limited granularity and effectiveness in few-parameter regimes. We propose Wavelet Fine-Tuning (WaveFT), a novel PEFT method that learns highly sparse updates in the wavelet domain of residual matrices. WaveFT allows precise control of trainable parameters, offering fine-grained capacity adjustment and excelling with remarkably low parameter count, potentially far fewer than LoRA's minimum -- ideal for extreme parameter-efficient scenarios. In order to demonstrate the effect of the wavelet transform, we compare WaveFT with a special case, called SHiRA, that entails applying sparse updates directly in the weight domain. Evaluated on personalized text-to-image generation using Stable Diffusion XL as baseline, WaveFT significantly outperforms LoRA and other PEFT methods, especially at low parameter counts; achieving superior subject fidelity, prompt alignment, and image diversity.
FG-DFPN: Flow Guided Deformable Frame Prediction Network
Mar 14, 2025Video frame prediction remains a fundamental challenge in computer vision with direct implications for autonomous systems, video compression, and media synthesis. We present FG-DFPN, a novel architecture that harnesses the synergy between optical flow estimation and deformable convolutions to model complex spatio-temporal dynamics. By guiding deformable sampling with motion cues, our approach addresses the limitations of fixed-kernel networks when handling diverse motion patterns. The multi-scale design enables FG-DFPN to simultaneously capture global scene transformations and local object movements with remarkable precision. Our experiments demonstrate that FG-DFPN achieves state-of-the-art performance on eight diverse MPEG test sequences, outperforming existing methods by 1dB PSNR while maintaining competitive inference speeds. The integration of motion cues with adaptive geometric transformations makes FG-DFPN a promising solution for next-generation video processing systems that require high-fidelity temporal predictions. The model and instructions to reproduce our results will be released at: https://github.com/KUIS-AI-Tekalp-Research Group/frame-prediction
Multi-Scale Deformable Alignment and Content-Adaptive Inference for Flexible-Rate Bi-Directional Video Compression
Jun 28, 2023The lack of ability to adapt the motion compensation model to video content is an important limitation of current end-to-end learned video compression models. This paper advances the state-of-the-art by proposing an adaptive motion-compensation model for end-to-end rate-distortion optimized hierarchical bi-directional video compression. In particular, we propose two novelties: i) a multi-scale deformable alignment scheme at the feature level combined with multi-scale conditional coding, ii) motion-content adaptive inference. In addition, we employ a gain unit, which enables a single model to operate at multiple rate-distortion operating points. We also exploit the gain unit to control bit allocation among intra-coded vs. bi-directionally coded frames by fine tuning corresponding models for truly flexible-rate learned video coding. Experimental results demonstrate state-of-the-art rate-distortion performance exceeding those of all prior art in learned video coding.
End-to-End Rate-Distortion Optimized Learned Hierarchical Bi-Directional Video Compression
Dec 17, 2021



Conventional video compression (VC) methods are based on motion compensated transform coding, and the steps of motion estimation, mode and quantization parameter selection, and entropy coding are optimized individually due to the combinatorial nature of the end-to-end optimization problem. Learned VC allows end-to-end rate-distortion (R-D) optimized training of nonlinear transform, motion and entropy model simultaneously. Most works on learned VC consider end-to-end optimization of a sequential video codec based on R-D loss averaged over pairs of successive frames. It is well-known in conventional VC that hierarchical, bi-directional coding outperforms sequential compression because of its ability to use both past and future reference frames. This paper proposes a learned hierarchical bi-directional video codec (LHBDC) that combines the benefits of hierarchical motion-compensated prediction and end-to-end optimization. Experimental results show that we achieve the best R-D results that are reported for learned VC schemes to date in both PSNR and MS-SSIM. Compared to conventional video codecs, the R-D performance of our end-to-end optimized codec outperforms those of both x265 and SVT-HEVC encoders ("veryslow" preset) in PSNR and MS-SSIM as well as HM 16.23 reference software in MS-SSIM. We present ablation studies showing performance gains due to proposed novel tools such as learned masking, flow-field subsampling, and temporal flow vector prediction. The models and instructions to reproduce our results can be found in https://github.com/makinyilmaz/LHBDC/
Self-Organized Variational Autoencoders (Self-VAE) for Learned Image Compression
May 28, 2021
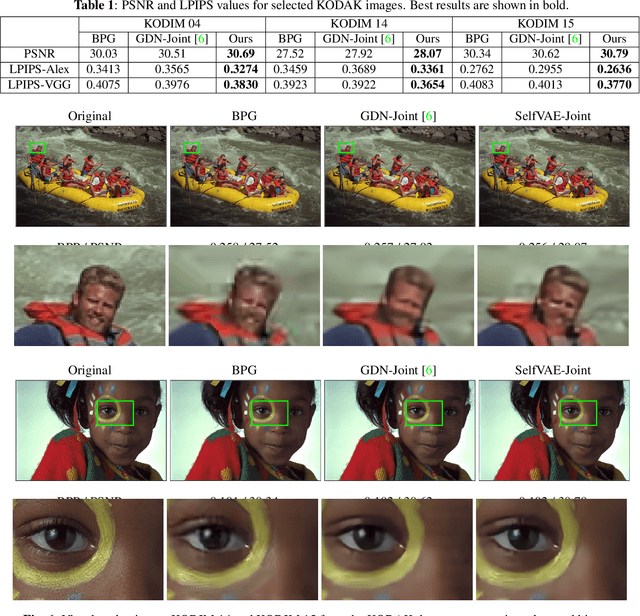
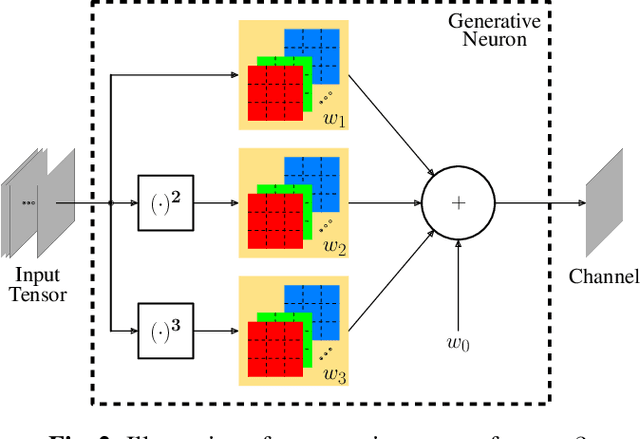
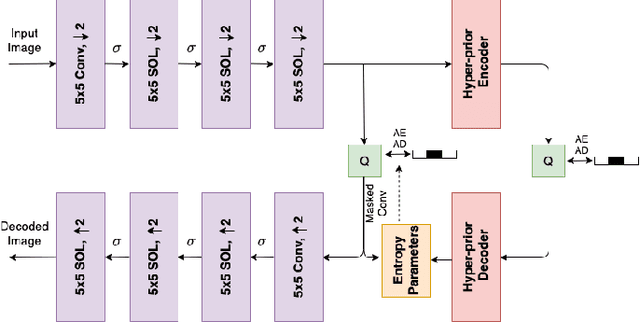
In end-to-end optimized learned image compression, it is standard practice to use a convolutional variational autoencoder with generalized divisive normalization (GDN) to transform images into a latent space. Recently, Operational Neural Networks (ONNs) that learn the best non-linearity from a set of alternatives, and their self-organized variants, Self-ONNs, that approximate any non-linearity via Taylor series have been proposed to address the limitations of convolutional layers and a fixed nonlinear activation. In this paper, we propose to replace the convolutional and GDN layers in the variational autoencoder with self-organized operational layers, and propose a novel self-organized variational autoencoder (Self-VAE) architecture that benefits from stronger non-linearity. The experimental results demonstrate that the proposed Self-VAE yields improvements in both rate-distortion performance and perceptual image quality.
DFPN: Deformable Frame Prediction Network
May 26, 2021


Learned frame prediction is a current problem of interest in computer vision and video compression. Although several deep network architectures have been proposed for learned frame prediction, to the best of our knowledge, there is no work based on using deformable convolutions for frame prediction. To this effect, we propose a deformable frame prediction network (DFPN) for task oriented implicit motion modeling and next frame prediction. Experimental results demonstrate that the proposed DFPN model achieves state of the art results in next frame prediction. Our models and results are available at https://github.com/makinyilmaz/DFPN.
On the Computation of PSNR for a Set of Images or Video
Apr 30, 2021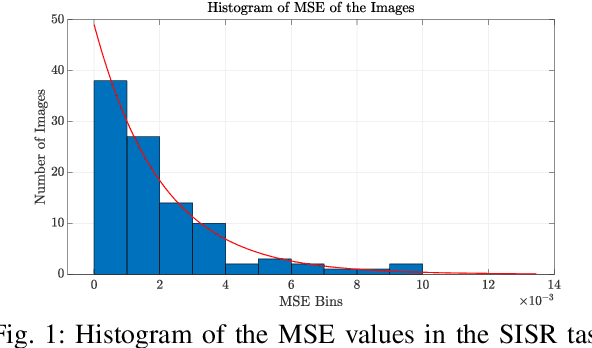
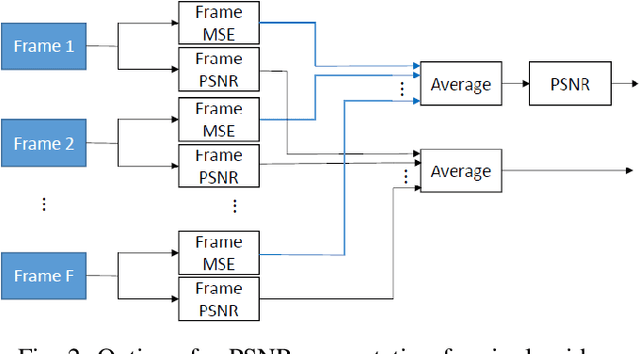
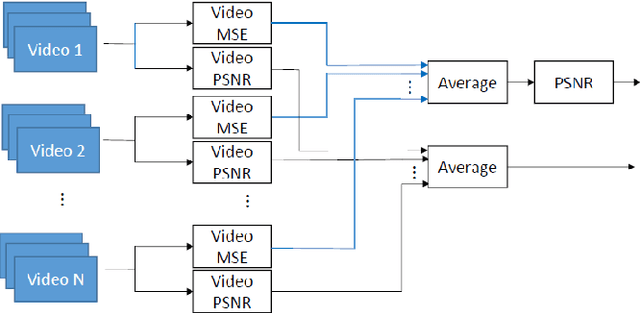
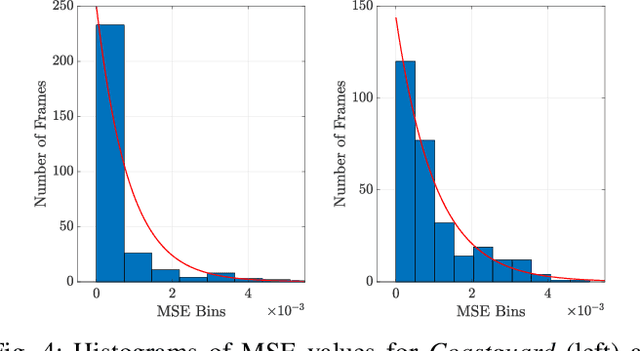
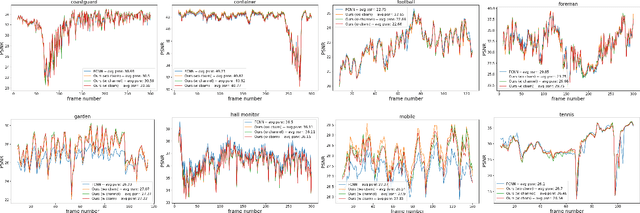
When comparing learned image/video restoration and compression methods, it is common to report peak-signal to noise ratio (PSNR) results. However, there does not exist a generally agreed upon practice to compute PSNR for sets of images or video. Some authors report average of individual image/frame PSNR, which is equivalent to computing a single PSNR from the geometric mean of individual image/frame mean-square error (MSE). Others compute a single PSNR from the arithmetic mean of frame MSEs for each video. Furthermore, some compute the MSE/PSNR of Y-channel only, while others compute MSE/PSNR for RGB channels. This paper investigates different approaches to computing PSNR for sets of images, single video, and sets of video and the relation between them. We show the difference between computing the PSNR based on arithmetic vs. geometric mean of MSE depends on the distribution of MSE over the set of images or video, and that this distribution is task-dependent. In particular, these two methods yield larger differences in restoration problems, where the MSE is exponentially distributed and smaller differences in compression problems, where the MSE distribution is narrower. We hope this paper will motivate the community to clearly describe how they compute reported PSNR values to enable consistent comparison.