 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometry OR Tracker: Universal Geometric Operating Room Tracking
Feb 28, 2026In operating rooms (OR), world-scale multi-view 3D tracking supports downstream applications such as surgeon behavior recognition, where physically meaningful quantities such as distances and motion statistics must be measured in meters. However, real clinical deployments rarely satisfy the geometric prerequisites for stable multi-view fusion and tracking: camera calibration and RGB-D registration are always unreliable, leading to cross-view geometric inconsistency that produces "ghosting" during fusion and degrades 3D trajectories in a shared OR coordinate frame. To address this, we introduce Geometry OR Tracker, a two-stage pipeline that first rectifies imprecise calibration into a scaleconsistent and geometrically consistent camera setup with a single global scale via a Multi-view Metric Geometry Rectification module, and then performs Occlusion-Robust 3D Point Tracking directly in the unified OR world frame. On the MM-OR benchmark, improved geometric consistency translates into tracking gains: our rectification front-end reduces cross-view depth disagreement by more than 30$\times$ compared to raw calibration. Ablation studies further demonstrate the relationship between calibration quality and tracking accuracy, showing that improved geometric consistency yields stronger world-frame tracking.
VQualA 2025 Challenge on Visual Quality Comparison for Large Multimodal Models: Methods and Results
Sep 11, 2025
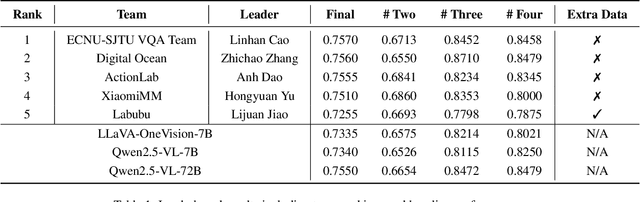
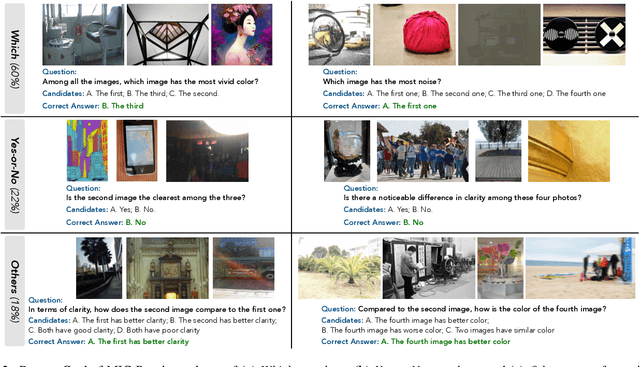
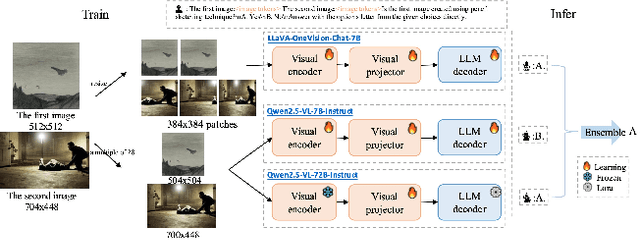
This paper presents a summary of the VQualA 2025 Challenge on Visual Quality Comparison for Large Multimodal Models (LMMs), hosted as part of the ICCV 2025 Workshop on Visual Quality Assessment. The challenge aims to evaluate and enhance the ability of state-of-the-art LMMs to perform open-ended and detailed reasoning about visual quality differences across multiple images. To this end, the competition introduces a novel benchmark comprising thousands of coarse-to-fine grained visual quality comparison tasks, spanning single images, pairs, and multi-image groups. Each task requires models to provide accurate quality judgments. The competition emphasizes holistic evaluation protocols, including 2AFC-based binary preference and multi-choice questions (MCQs). Around 100 participants submitted entries, with five models demonstrating the emerging capabilities of instruction-tuned LMMs on quality assessment. This challenge marks a significant step toward open-domain visual quality reasoning and comparison and serves as a catalyst for future research on interpretable and human-aligned quality evaluation systems.
Sample-aware RandAugment: Search-free Automatic Data Augmentation for Effective Image Recognition
Aug 11, 2025Automatic data augmentation (AutoDA) plays an important role in enhancing the generalization of neural networks. However, mainstream AutoDA methods often encounter two challenges: either the search process is excessively time-consuming, hindering practical application, or the performance is suboptimal due to insufficient policy adaptation during training. To address these issues, we propose Sample-aware RandAugment (SRA), an asymmetric, search-free AutoDA method that dynamically adjusts augmentation policies while maintaining straightforward implementation. SRA incorporates a heuristic scoring module that evaluates the complexity of the original training data, enabling the application of tailored augmentations for each sample. Additionally, an asymmetric augmentation strategy is employed to maximize the potential of this scoring module. In multiple experimental settings, SRA narrows the performance gap between search-based and search-free AutoDA methods, achieving a state-of-the-art Top-1 accuracy of 78.31\% on ImageNet with ResNet-50. Notably, SRA demonstrates good compatibility with existing augmentation pipelines and solid generalization across new tasks, without requiring hyperparameter tuning. The pretrained models leveraging SRA also enhance recognition in downstream object detection tasks. SRA represents a promising step towards simpler, more effective, and practical AutoDA designs applicable to a variety of future tasks. Our code is available at \href{https://github.com/ainieli/Sample-awareRandAugment}{https://github.com/ainieli/Sample-awareRandAugment
SurgVisAgent: Multimodal Agentic Model for Versatile Surgical Visual Enhancement
Jul 03, 2025



Precise surgical interventions are vital to patient safety, and advanced enhancement algorithms have been developed to assist surgeons in decision-making. Despite significant progress, these algorithms are typically designed for single tasks in specific scenarios, limiting their effectiveness in complex real-world situations. To address this limitation, we propose SurgVisAgent, an end-to-end intelligent surgical vision agent built on multimodal large language models (MLLMs). SurgVisAgent dynamically identifies distortion categories and severity levels in endoscopic images, enabling it to perform a variety of enhancement tasks such as low-light enhancement, overexposure correction, motion blur elimination, and smoke removal. Specifically, to achieve superior surgical scenario understanding, we design a prior model that provides domain-specific knowledge. Additionally, through in-context few-shot learning and chain-of-thought (CoT) reasoning, SurgVisAgent delivers customized image enhancements tailored to a wide range of distortion types and severity levels, thereby addressing the diverse requirements of surgeons. Furthermore, we construct a comprehensive benchmark simulating real-world surgical distortions, on which extensive experiments demonstrate that SurgVisAgent surpasses traditional single-task models, highlighting its potential as a unified solution for surgical assistance.
NTIRE 2025 Challenge on Image Super-Resolution ($\times$4): Methods and Results
Apr 20, 2025This paper presents the NTIRE 2025 image super-resolution ($\times$4) challenge, one of the associated competitions of the 10th NTIRE Workshop at CVPR 2025. The challenge aims to recover high-resolution (HR) images from low-resolution (LR) counterparts generated through bicubic downsampling with a $\times$4 scaling factor. The objective is to develop effective network designs or solutions that achieve state-of-the-art SR performance. To reflect the dual objectives of image SR research, the challenge includes two sub-tracks: (1) a restoration track, emphasizes pixel-wise accuracy and ranks submissions based on PSNR; (2) a perceptual track, focuses on visual realism and ranks results by a perceptual score. A total of 286 participants registered for the competition, with 25 teams submitting valid entries. This report summarizes the challenge design, datasets, evaluation protocol, the main results, and methods of each team. The challenge serves as a benchmark to advance the state of the art and foster progress in image SR.
The Tenth NTIRE 2025 Image Denoising Challenge Report
Apr 16, 2025



This paper presents an overview of the NTIRE 2025 Image Denoising Challenge ({\sigma} = 50), highlighting the proposed methodologies and corresponding results. The primary objective is to develop a network architecture capable of achieving high-quality denoising performance, quantitatively evaluated using PSNR, without constraints on computational complexity or model size. The task assumes independent additive white Gaussian noise (AWGN) with a fixed noise level of 50. A total of 290 participants registered for the challenge, with 20 teams successfully submitting valid results, providing insights into the current state-of-the-art in image denoising.
NTIRE 2025 Challenge on Event-Based Image Deblurring: Methods and Results
Apr 16, 2025This paper presents an overview of NTIRE 2025 the First Challenge on Event-Based Image Deblurring, detailing the proposed methodologies and corresponding results. The primary goal of the challenge is to design an event-based method that achieves high-quality image deblurring, with performance quantitatively assessed using Peak Signal-to-Noise Ratio (PSNR). Notably, there are no restrictions on computational complexity or model size. The task focuses on leveraging both events and images as inputs for single-image deblurring. A total of 199 participants registered, among whom 15 teams successfully submitted valid results, offering valuable insights into the current state of event-based image deblurring. We anticipate that this challenge will drive further advancements in event-based vision research.
The Tenth NTIRE 2025 Efficient Super-Resolution Challenge Report
Apr 14, 2025This paper presents a comprehensive review of the NTIRE 2025 Challenge on Single-Image Efficient Super-Resolution (ESR). The challenge aimed to advance the development of deep models that optimize key computational metrics, i.e., runtime, parameters, and FLOPs, while achieving a PSNR of at least 26.90 dB on the $\operatorname{DIV2K\_LSDIR\_valid}$ dataset and 26.99 dB on the $\operatorname{DIV2K\_LSDIR\_test}$ dataset. A robust participation saw \textbf{244} registered entrants, with \textbf{43} teams submitting valid entries. This report meticulously analyzes these methods and results, emphasizing groundbreaking advancements in state-of-the-art single-image ESR techniques. The analysis highlights innovative approaches and establishes benchmarks for future research in the field.
SliceMamba for Medical Image Segmentation
Jul 11, 2024



Despite the progress made in Mamba-based medical image segmentation models, current methods utilizing unidirectional or multi-directional feature scanning mechanisms fail to well model dependencies between neighboring positions in the image, hindering the effective modeling of local features. However, local features are crucial for medical image segmentation as they provide vital information about lesions and tissue structures. To address this limitation, we propose a simple yet effective method named SliceMamba, a locally sensitive pure Mamba medical image segmentation model. The proposed SliceMamba includes an efffcient Bidirectional Slice Scan module (BSS), which performs bidirectional feature segmentation while employing varied scanning mechanisms for distinct features. This ensures that spatially adjacent features maintain proximity in the scanning sequence, thereby enhancing segmentation performance. Extensive experiments on skin lesion and polyp segmentation datasets validate the effectiveness of our method.
MIPI 2024 Challenge on Demosaic for HybridEVS Camera: Methods and Results
May 08, 2024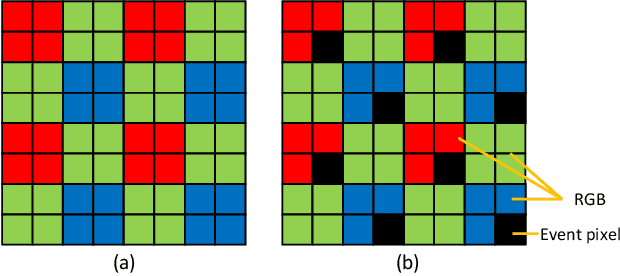
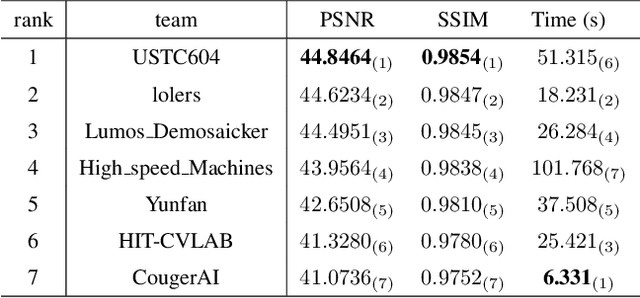
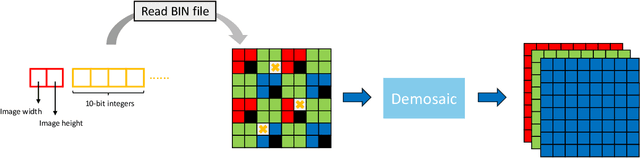

The increasing demand for computational photography and imaging on mobile platforms has led to the widespread development and integration of advanced image sensors with novel algorithms in camera systems. However, the scarcity of high-quality data for research and the rare opportunity for in-depth exchange of views from industry and academia constrain the development of mobile intelligent photography and imaging (MIPI). Building on the achievements of the previous MIPI Workshops held at ECCV 2022 and CVPR 2023, we introduce our third MIPI challenge including three tracks focusing on novel image sensors and imaging algorithms. In this paper, we summarize and review the Nighttime Flare Removal track on MIPI 2024. In total, 170 participants were successfully registered, and 14 teams submitted results in the final testing phase. The developed solutions in this challenge achieved state-of-the-art performance on Nighttime Flare Removal. More details of this challenge and the link to the dataset can be found at https://mipi-challenge.org/MIPI2024/.