 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeedance 1.5 pro: A Native Audio-Visual Joint Generation Foundation Model
Dec 23, 2025Recent strides in video generation have paved the way for unified audio-visual generation. In this work, we present Seedance 1.5 pro, a foundational model engineered specifically for native, joint audio-video generation. Leveraging a dual-branch Diffusion Transformer architecture, the model integrates a cross-modal joint module with a specialized multi-stage data pipeline, achieving exceptional audio-visual synchronization and superior generation quality. To ensure practical utility, we implement meticulous post-training optimizations, including Supervised Fine-Tuning (SFT) on high-quality datasets and Reinforcement Learning from Human Feedback (RLHF) with multi-dimensional reward models. Furthermore, we introduce an acceleration framework that boosts inference speed by over 10X. Seedance 1.5 pro distinguishes itself through precise multilingual and dialect lip-syncing, dynamic cinematic camera control, and enhanced narrative coherence, positioning it as a robust engine for professional-grade content creation. Seedance 1.5 pro is now accessible on Volcano Engine at https://console.volcengine.com/ark/region:ark+cn-beijing/experience/vision?type=GenVideo.
PerTouch: VLM-Driven Agent for Personalized and Semantic Image Retouching
Nov 17, 2025Image retouching aims to enhance visual quality while aligning with users' personalized aesthetic preferences. To address the challenge of balancing controllability and subjectivity, we propose a unified diffusion-based image retouching framework called PerTouch. Our method supports semantic-level image retouching while maintaining global aesthetics. Using parameter maps containing attribute values in specific semantic regions as input, PerTouch constructs an explicit parameter-to-image mapping for fine-grained image retouching. To improve semantic boundary perception, we introduce semantic replacement and parameter perturbation mechanisms in the training process. To connect natural language instructions with visual control, we develop a VLM-driven agent that can handle both strong and weak user instructions. Equipped with mechanisms of feedback-driven rethinking and scene-aware memory, PerTouch better aligns with user intent and captures long-term preferences. Extensive experiments demonstrate each component's effectiveness and the superior performance of PerTouch in personalized image retouching. Code is available at: https://github.com/Auroral703/PerTouch.
Iterative Predictor-Critic Code Decoding for Real-World Image Dehazing
Mar 17, 2025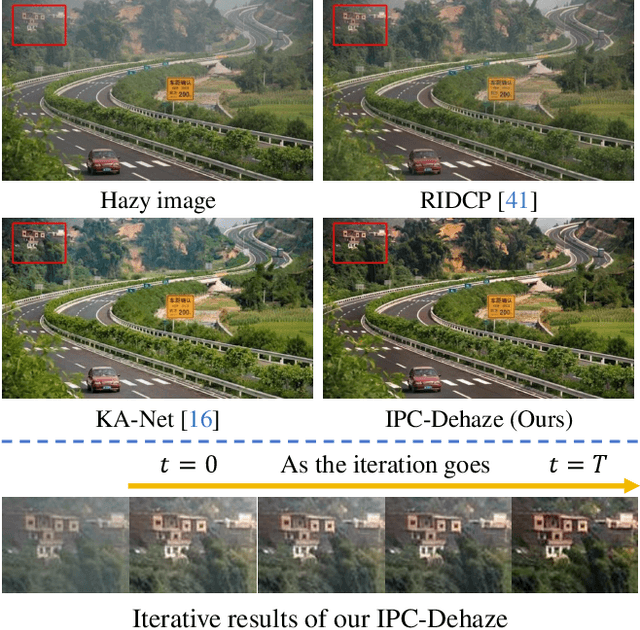
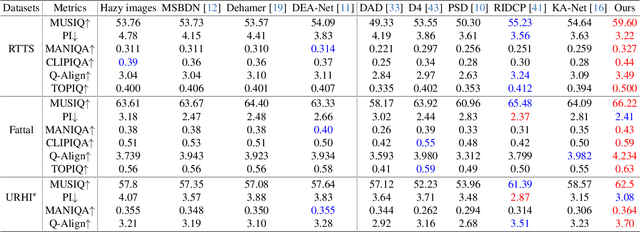
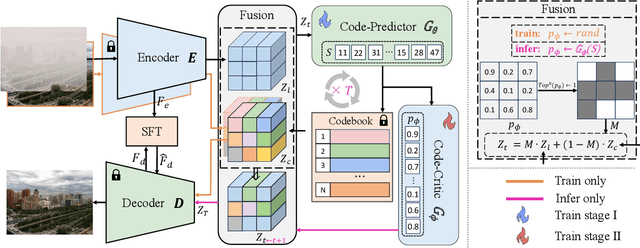

We propose a novel Iterative Predictor-Critic Code Decoding framework for real-world image dehazing, abbreviated as IPC-Dehaze, which leverages the high-quality codebook prior encapsulated in a pre-trained VQGAN. Apart from previous codebook-based methods that rely on one-shot decoding, our method utilizes high-quality codes obtained in the previous iteration to guide the prediction of the Code-Predictor in the subsequent iteration, improving code prediction accuracy and ensuring stable dehazing performance. Our idea stems from the observations that 1) the degradation of hazy images varies with haze density and scene depth, and 2) clear regions play crucial cues in restoring dense haze regions. However, it is non-trivial to progressively refine the obtained codes in subsequent iterations, owing to the difficulty in determining which codes should be retained or replaced at each iteration. Another key insight of our study is to propose Code-Critic to capture interrelations among codes. The Code-Critic is used to evaluate code correlations and then resample a set of codes with the highest mask scores, i.e., a higher score indicates that the code is more likely to be rejected, which helps retain more accurate codes and predict difficult ones. Extensive experiments demonstrate the superiority of our method over state-of-the-art methods in real-world dehazing.
FaceMe: Robust Blind Face Restoration with Personal Identification
Jan 10, 2025
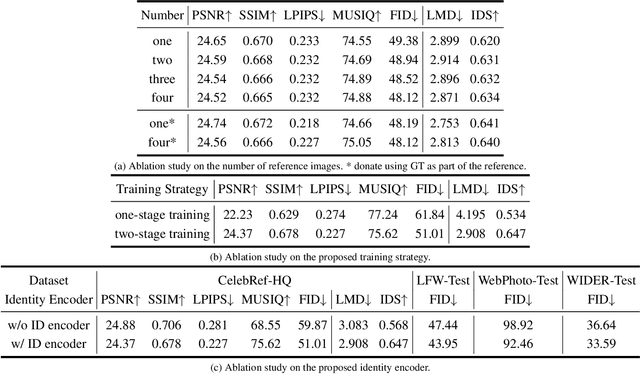


Blind face restoration is a highly ill-posed problem due to the lack of necessary context. Although existing methods produce high-quality outputs, they often fail to faithfully preserve the individual's identity. In this paper, we propose a personalized face restoration method, FaceMe, based on a diffusion model. Given a single or a few reference images, we use an identity encoder to extract identity-related features, which serve as prompts to guide the diffusion model in restoring high-quality and identity-consistent facial images. By simply combining identity-related features, we effectively minimize the impact of identity-irrelevant features during training and support any number of reference image inputs during inference. Additionally, thanks to the robustness of the identity encoder, synthesized images can be used as reference images during training, and identity changing during inference does not require fine-tuning the model. We also propose a pipeline for constructing a reference image training pool that simulates the poses and expressions that may appear in real-world scenarios. Experimental results demonstrate that our FaceMe can restore high-quality facial images while maintaining identity consistency, achieving excellent performance and robustness.
EnsIR: An Ensemble Algorithm for Image Restoration via Gaussian Mixture Models
Oct 30, 2024

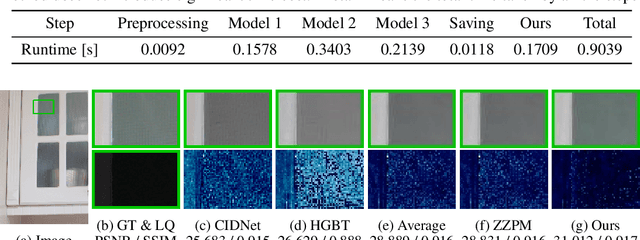

Image restoration has experienced significant advancements due to the development of deep learning. Nevertheless, it encounters challenges related to ill-posed problems, resulting in deviations between single model predictions and ground-truths. Ensemble learning, as a powerful machine learning technique, aims to address these deviations by combining the predictions of multiple base models. Most existing works adopt ensemble learning during the design of restoration models, while only limited research focuses on the inference-stage ensemble of pre-trained restoration models. Regression-based methods fail to enable efficient inference, leading researchers in academia and industry to prefer averaging as their choice for post-training ensemble. To address this, we reformulate the ensemble problem of image restoration into Gaussian mixture models (GMMs) and employ an expectation maximization (EM)-based algorithm to estimate ensemble weights for aggregating prediction candidates. We estimate the range-wise ensemble weights on a reference set and store them in a lookup table (LUT) for efficient ensemble inference on the test set. Our algorithm is model-agnostic and training-free, allowing seamless integration and enhancement of various pre-trained image restoration models. It consistently outperforms regression based methods and averaging ensemble approaches on 14 benchmarks across 3 image restoration tasks, including super-resolution, deblurring and deraining. The codes and all estimated weights have been released in Github.
Restore Anything with Masks: Leveraging Mask Image Modeling for Blind All-in-One Image Restoration
Sep 28, 2024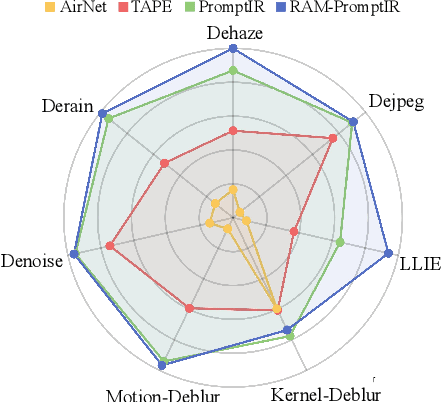
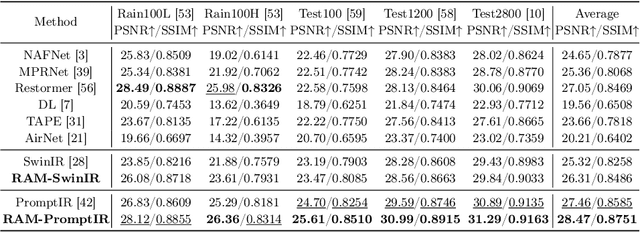

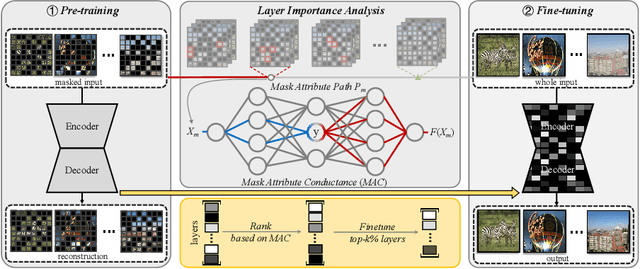
All-in-one image restoration aims to handle multiple degradation types using one model. This paper proposes a simple pipeline for all-in-one blind image restoration to Restore Anything with Masks (RAM). We focus on the image content by utilizing Mask Image Modeling to extract intrinsic image information rather than distinguishing degradation types like other methods. Our pipeline consists of two stages: masked image pre-training and fine-tuning with mask attribute conductance. We design a straightforward masking pre-training approach specifically tailored for all-in-one image restoration. This approach enhances networks to prioritize the extraction of image content priors from various degradations, resulting in a more balanced performance across different restoration tasks and achieving stronger overall results. To bridge the gap of input integrity while preserving learned image priors as much as possible, we selectively fine-tuned a small portion of the layers. Specifically, the importance of each layer is ranked by the proposed Mask Attribute Conductance (MAC), and the layers with higher contributions are selected for finetuning. Extensive experiments demonstrate that our method achieves state-of-the-art performance. Our code and model will be released at \href{https://github.com/Dragonisss/RAM}{https://github.com/Dragonisss/RAM}.
MIPI 2024 Challenge on Few-shot RAW Image Denoising: Methods and Results
Jun 11, 2024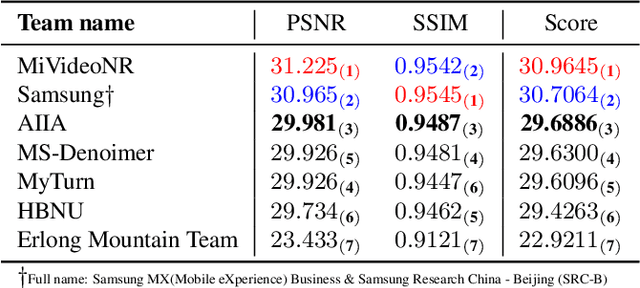
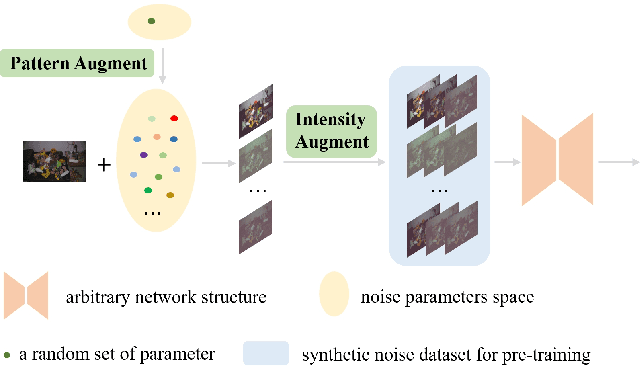

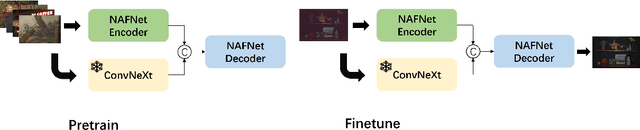
The increasing demand for computational photography and imaging on mobile platforms has led to the widespread development and integration of advanced image sensors with novel algorithms in camera systems. However, the scarcity of high-quality data for research and the rare opportunity for in-depth exchange of views from industry and academia constrain the development of mobile intelligent photography and imaging (MIPI). Building on the achievements of the previous MIPI Workshops held at ECCV 2022 and CVPR 2023, we introduce our third MIPI challenge including three tracks focusing on novel image sensors and imaging algorithms. In this paper, we summarize and review the Few-shot RAW Image Denoising track on MIPI 2024. In total, 165 participants were successfully registered, and 7 teams submitted results in the final testing phase. The developed solutions in this challenge achieved state-of-the-art erformance on Few-shot RAW Image Denoising. More details of this challenge and the link to the dataset can be found at https://mipichallenge.org/MIPI2024.
Deep RAW Image Super-Resolution. A NTIRE 2024 Challenge Survey
Apr 24, 2024
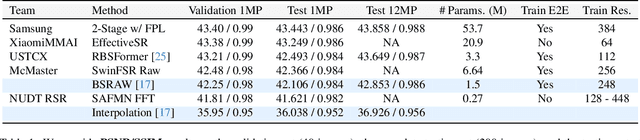
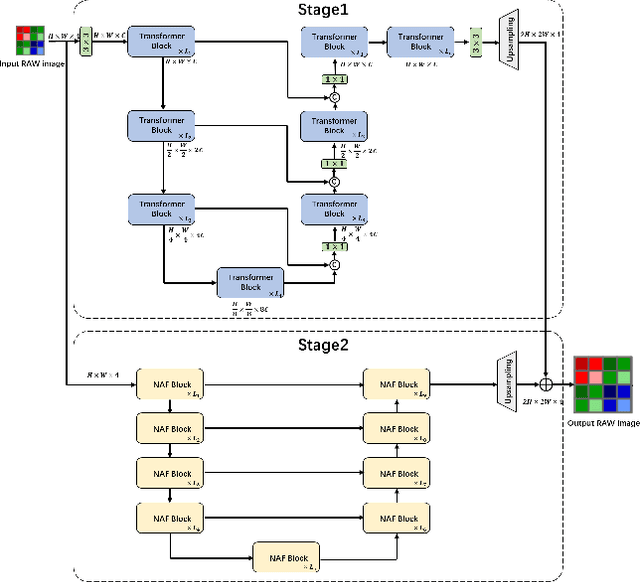
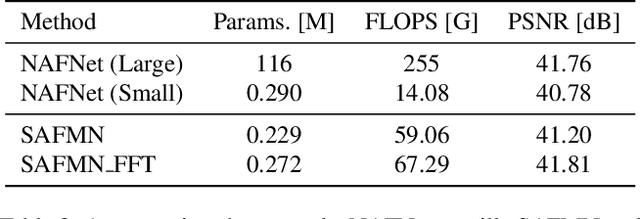
This paper reviews the NTIRE 2024 RAW Image Super-Resolution Challenge, highlighting the proposed solutions and results. New methods for RAW Super-Resolution could be essential in modern Image Signal Processing (ISP) pipelines, however, this problem is not as explored as in the RGB domain. Th goal of this challenge is to upscale RAW Bayer images by 2x, considering unknown degradations such as noise and blur. In the challenge, a total of 230 participants registered, and 45 submitted results during thee challenge period. The performance of the top-5 submissions is reviewed and provided here as a gauge for the current state-of-the-art in RAW Image Super-Resolution.
Segmentation Guided Sparse Transformer for Under-Display Camera Image Restoration
Mar 09, 2024



Under-Display Camera (UDC) is an emerging technology that achieves full-screen display via hiding the camera under the display panel. However, the current implementation of UDC causes serious degradation. The incident light required for camera imaging undergoes attenuation and diffraction when passing through the display panel, leading to various artifacts in UDC imaging. Presently, the prevailing UDC image restoration methods predominantly utilize convolutional neural network architectures, whereas Transformer-based methods have exhibited superior performance in the majority of image restoration tasks. This is attributed to the Transformer's capability to sample global features for the local reconstruction of images, thereby achieving high-quality image restoration. In this paper, we observe that when using the Vision Transformer for UDC degraded image restoration, the global attention samples a large amount of redundant information and noise. Furthermore, compared to the ordinary Transformer employing dense attention, the Transformer utilizing sparse attention can alleviate the adverse impact of redundant information and noise. Building upon this discovery, we propose a Segmentation Guided Sparse Transformer method (SGSFormer) for the task of restoring high-quality images from UDC degraded images. Specifically, we utilize sparse self-attention to filter out redundant information and noise, directing the model's attention to focus on the features more relevant to the degraded regions in need of reconstruction. Moreover, we integrate the instance segmentation map as prior information to guide the sparse self-attention in filtering and focusing on the correct regions.
Deep Video Restoration for Under-Display Camera
Sep 09, 2023



Images or videos captured by the Under-Display Camera (UDC) suffer from severe degradation, such as saturation degeneration and color shift. While restoration for UDC has been a critical task, existing works of UDC restoration focus only on images. UDC video restoration (UDC-VR) has not been explored in the community. In this work, we first propose a GAN-based generation pipeline to simulate the realistic UDC degradation process. With the pipeline, we build the first large-scale UDC video restoration dataset called PexelsUDC, which includes two subsets named PexelsUDC-T and PexelsUDC-P corresponding to different displays for UDC. Using the proposed dataset, we conduct extensive benchmark studies on existing video restoration methods and observe their limitations on the UDC-VR task. To this end, we propose a novel transformer-based baseline method that adaptively enhances degraded videos. The key components of the method are a spatial branch with local-aware transformers, a temporal branch embedded temporal transformers, and a spatial-temporal fusion module. These components drive the model to fully exploit spatial and temporal information for UDC-VR. Extensive experiments show that our method achieves state-of-the-art performance on PexelsUDC. The benchmark and the baseline method are expected to promote the progress of UDC-VR in the community, which will be made public.