 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Reconstruction of Representation Autoencoder
Feb 09, 2026Recent work leverages Vision Foundation Models as image encoders to boost the generative performance of latent diffusion models (LDMs), as their semantic feature distributions are easy to learn. However, such semantic features often lack low-level information (\eg, color and texture), leading to degraded reconstruction fidelity, which has emerged as a primary bottleneck in further scaling LDMs. To address this limitation, we propose LV-RAE, a representation autoencoder that augments semantic features with missing low-level information, enabling high-fidelity reconstruction while remaining highly aligned with the semantic distribution. We further observe that the resulting high-dimensional, information-rich latent make decoders sensitive to latent perturbations, causing severe artifacts when decoding generated latent and consequently degrading generation quality. Our analysis suggests that this sensitivity primarily stems from excessive decoder responses along directions off the data manifold. Building on these insights, we propose fine-tuning the decoder to increase its robustness and smoothing the generated latent via controlled noise injection, thereby enhancing generation quality. Experiments demonstrate that LV-RAE significantly improves reconstruction fidelity while preserving the semantic abstraction and achieving strong generative quality. Our code is available at https://github.com/modyu-liu/LVRAE.
PerTouch: VLM-Driven Agent for Personalized and Semantic Image Retouching
Nov 17, 2025Image retouching aims to enhance visual quality while aligning with users' personalized aesthetic preferences. To address the challenge of balancing controllability and subjectivity, we propose a unified diffusion-based image retouching framework called PerTouch. Our method supports semantic-level image retouching while maintaining global aesthetics. Using parameter maps containing attribute values in specific semantic regions as input, PerTouch constructs an explicit parameter-to-image mapping for fine-grained image retouching. To improve semantic boundary perception, we introduce semantic replacement and parameter perturbation mechanisms in the training process. To connect natural language instructions with visual control, we develop a VLM-driven agent that can handle both strong and weak user instructions. Equipped with mechanisms of feedback-driven rethinking and scene-aware memory, PerTouch better aligns with user intent and captures long-term preferences. Extensive experiments demonstrate each component's effectiveness and the superior performance of PerTouch in personalized image retouching. Code is available at: https://github.com/Auroral703/PerTouch.
A Diffusion-Based Framework for Occluded Object Movement
Apr 02, 2025Seamlessly moving objects within a scene is a common requirement for image editing, but it is still a challenge for existing editing methods. Especially for real-world images, the occlusion situation further increases the difficulty. The main difficulty is that the occluded portion needs to be completed before movement can proceed. To leverage the real-world knowledge embedded in the pre-trained diffusion models, we propose a Diffusion-based framework specifically designed for Occluded Object Movement, named DiffOOM. The proposed DiffOOM consists of two parallel branches that perform object de-occlusion and movement simultaneously. The de-occlusion branch utilizes a background color-fill strategy and a continuously updated object mask to focus the diffusion process on completing the obscured portion of the target object. Concurrently, the movement branch employs latent optimization to place the completed object in the target location and adopts local text-conditioned guidance to integrate the object into new surroundings appropriately. Extensive evaluations demonstrate the superior performance of our method, which is further validated by a comprehensive user study.
DiT4SR: Taming Diffusion Transformer for Real-World Image Super-Resolution
Mar 30, 2025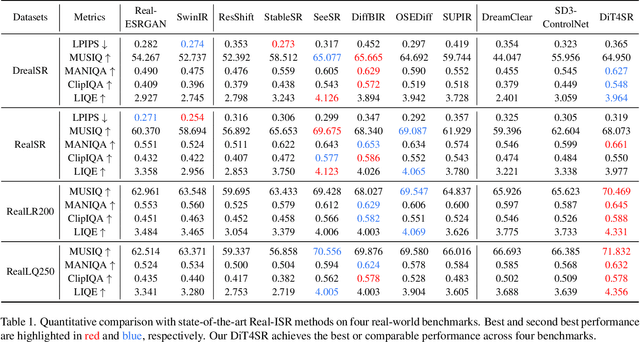
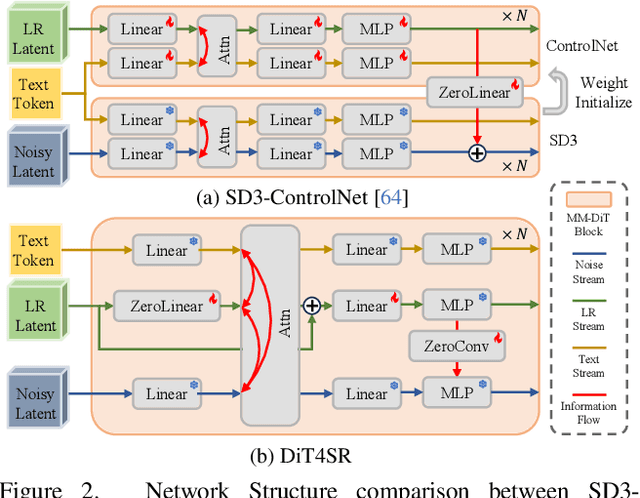
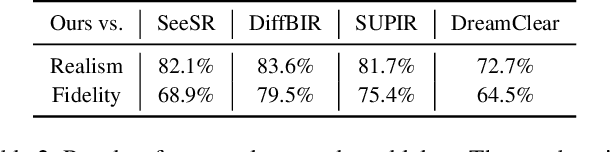
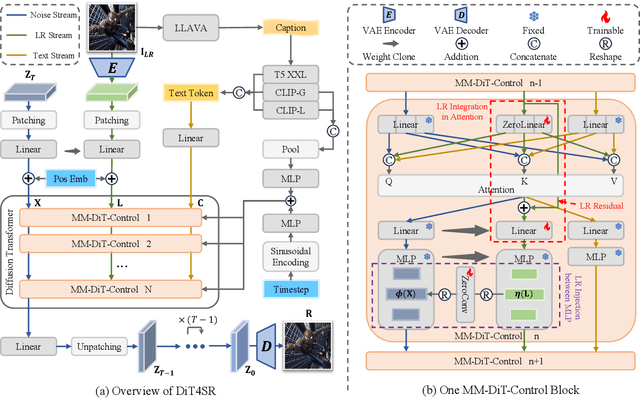
Large-scale pre-trained diffusion models are becoming increasingly popular in solving the Real-World Image Super-Resolution (Real-ISR) problem because of their rich generative priors. The recent development of diffusion transformer (DiT) has witnessed overwhelming performance over the traditional UNet-based architecture in image generation, which also raises the question: Can we adopt the advanced DiT-based diffusion model for Real-ISR? To this end, we propose our DiT4SR, one of the pioneering works to tame the large-scale DiT model for Real-ISR. Instead of directly injecting embeddings extracted from low-resolution (LR) images like ControlNet, we integrate the LR embeddings into the original attention mechanism of DiT, allowing for the bidirectional flow of information between the LR latent and the generated latent. The sufficient interaction of these two streams allows the LR stream to evolve with the diffusion process, producing progressively refined guidance that better aligns with the generated latent at each diffusion step. Additionally, the LR guidance is injected into the generated latent via a cross-stream convolution layer, compensating for DiT's limited ability to capture local information. These simple but effective designs endow the DiT model with superior performance in Real-ISR, which is demonstrated by extensive experiments. Project Page: https://adam-duan.github.io/projects/dit4sr/.
FaceMe: Robust Blind Face Restoration with Personal Identification
Jan 10, 2025Blind face restoration is a highly ill-posed problem due to the lack of necessary context. Although existing methods produce high-quality outputs, they often fail to faithfully preserve the individual's identity. In this paper, we propose a personalized face restoration method, FaceMe, based on a diffusion model. Given a single or a few reference images, we use an identity encoder to extract identity-related features, which serve as prompts to guide the diffusion model in restoring high-quality and identity-consistent facial images. By simply combining identity-related features, we effectively minimize the impact of identity-irrelevant features during training and support any number of reference image inputs during inference. Additionally, thanks to the robustness of the identity encoder, synthesized images can be used as reference images during training, and identity changing during inference does not require fine-tuning the model. We also propose a pipeline for constructing a reference image training pool that simulates the poses and expressions that may appear in real-world scenarios. Experimental results demonstrate that our FaceMe can restore high-quality facial images while maintaining identity consistency, achieving excellent performance and robustness.
DiffRetouch: Using Diffusion to Retouch on the Shoulder of Experts
Jul 04, 2024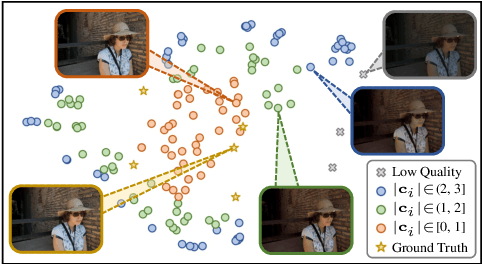
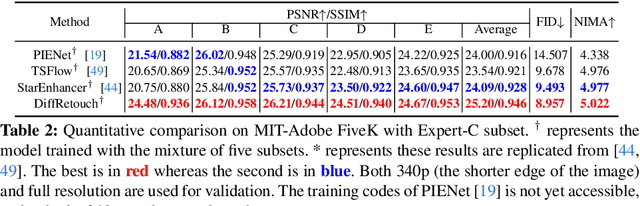
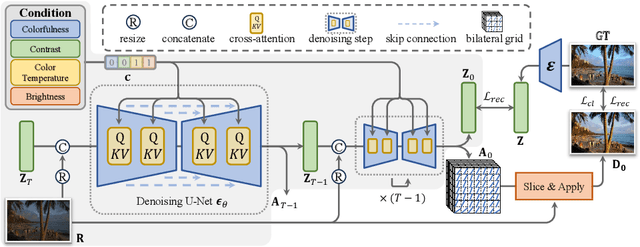
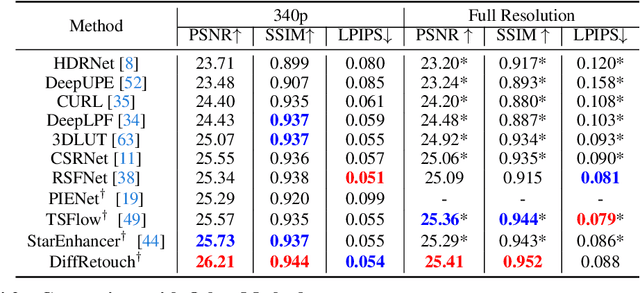
Image retouching aims to enhance the visual quality of photos. Considering the different aesthetic preferences of users, the target of retouching is subjective. However, current retouching methods mostly adopt deterministic models, which not only neglects the style diversity in the expert-retouched results and tends to learn an average style during training, but also lacks sample diversity during inference. In this paper, we propose a diffusion-based method, named DiffRetouch. Thanks to the excellent distribution modeling ability of diffusion, our method can capture the complex fine-retouched distribution covering various visual-pleasing styles in the training data. Moreover, four image attributes are made adjustable to provide a user-friendly editing mechanism. By adjusting these attributes in specified ranges, users are allowed to customize preferred styles within the learned fine-retouched distribution. Additionally, the affine bilateral grid and contrastive learning scheme are introduced to handle the problem of texture distortion and control insensitivity respectively. Extensive experiments have demonstrated the superior performance of our method on visually appealing and sample diversity. The code will be made available to the community.
Lighting Every Darkness with 3DGS: Fast Training and Real-Time Rendering for HDR View Synthesis
Jun 10, 2024Volumetric rendering based methods, like NeRF, excel in HDR view synthesis from RAWimages, especially for nighttime scenes. While, they suffer from long training times and cannot perform real-time rendering due to dense sampling requirements. The advent of 3D Gaussian Splatting (3DGS) enables real-time rendering and faster training. However, implementing RAW image-based view synthesis directly using 3DGS is challenging due to its inherent drawbacks: 1) in nighttime scenes, extremely low SNR leads to poor structure-from-motion (SfM) estimation in distant views; 2) the limited representation capacity of spherical harmonics (SH) function is unsuitable for RAW linear color space; and 3) inaccurate scene structure hampers downstream tasks such as refocusing. To address these issues, we propose LE3D (Lighting Every darkness with 3DGS). Our method proposes Cone Scatter Initialization to enrich the estimation of SfM, and replaces SH with a Color MLP to represent the RAW linear color space. Additionally, we introduce depth distortion and near-far regularizations to improve the accuracy of scene structure for downstream tasks. These designs enable LE3D to perform real-time novel view synthesis, HDR rendering, refocusing, and tone-mapping changes. Compared to previous volumetric rendering based methods, LE3D reduces training time to 1% and improves rendering speed by up to 4,000 times for 2K resolution images in terms of FPS. Code and viewer can be found in https://github.com/Srameo/LE3D .
RIDCP: Revitalizing Real Image Dehazing via High-Quality Codebook Priors
Apr 08, 2023



Existing dehazing approaches struggle to process real-world hazy images owing to the lack of paired real data and robust priors. In this work, we present a new paradigm for real image dehazing from the perspectives of synthesizing more realistic hazy data and introducing more robust priors into the network. Specifically, (1) instead of adopting the de facto physical scattering model, we rethink the degradation of real hazy images and propose a phenomenological pipeline considering diverse degradation types. (2) We propose a Real Image Dehazing network via high-quality Codebook Priors (RIDCP). Firstly, a VQGAN is pre-trained on a large-scale high-quality dataset to obtain the discrete codebook, encapsulating high-quality priors (HQPs). After replacing the negative effects brought by haze with HQPs, the decoder equipped with a novel normalized feature alignment module can effectively utilize high-quality features and produce clean results. However, although our degradation pipeline drastically mitigates the domain gap between synthetic and real data, it is still intractable to avoid it, which challenges HQPs matching in the wild. Thus, we re-calculate the distance when matching the features to the HQPs by a controllable matching operation, which facilitates finding better counterparts. We provide a recommendation to control the matching based on an explainable solution. Users can also flexibly adjust the enhancement degree as per their preference. Extensive experiments verify the effectiveness of our data synthesis pipeline and the superior performance of RIDCP in real image dehazing.