 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRIDCP: Revitalizing Real Image Dehazing via High-Quality Codebook Priors
Apr 08, 2023



Existing dehazing approaches struggle to process real-world hazy images owing to the lack of paired real data and robust priors. In this work, we present a new paradigm for real image dehazing from the perspectives of synthesizing more realistic hazy data and introducing more robust priors into the network. Specifically, (1) instead of adopting the de facto physical scattering model, we rethink the degradation of real hazy images and propose a phenomenological pipeline considering diverse degradation types. (2) We propose a Real Image Dehazing network via high-quality Codebook Priors (RIDCP). Firstly, a VQGAN is pre-trained on a large-scale high-quality dataset to obtain the discrete codebook, encapsulating high-quality priors (HQPs). After replacing the negative effects brought by haze with HQPs, the decoder equipped with a novel normalized feature alignment module can effectively utilize high-quality features and produce clean results. However, although our degradation pipeline drastically mitigates the domain gap between synthetic and real data, it is still intractable to avoid it, which challenges HQPs matching in the wild. Thus, we re-calculate the distance when matching the features to the HQPs by a controllable matching operation, which facilitates finding better counterparts. We provide a recommendation to control the matching based on an explainable solution. Users can also flexibly adjust the enhancement degree as per their preference. Extensive experiments verify the effectiveness of our data synthesis pipeline and the superior performance of RIDCP in real image dehazing.
Underwater Ranker: Learn Which Is Better and How to Be Better
Aug 14, 2022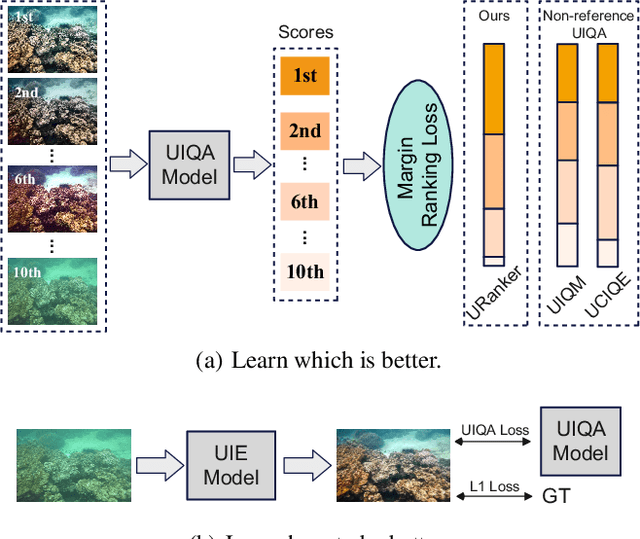
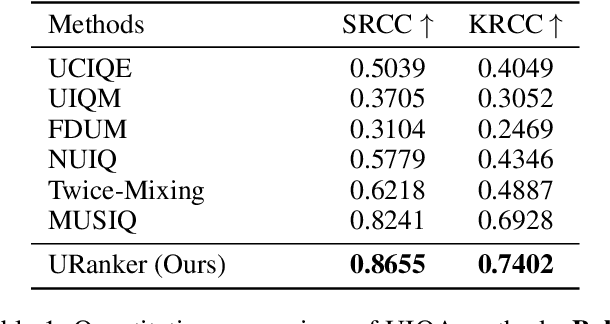

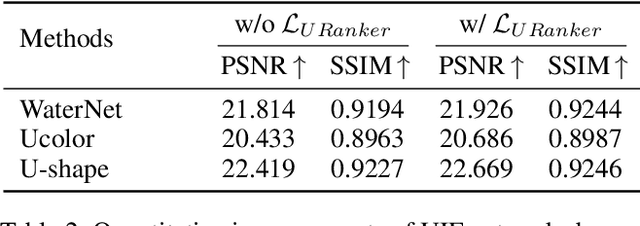
In this paper, we present a ranking-based underwater image quality assessment (UIQA) method, abbreviated as URanker. The URanker is built on the efficient conv-attentional image Transformer. In terms of underwater images, we specially devise (1) the histogram prior that embeds the color distribution of an underwater image as histogram token to attend global degradation and (2) the dynamic cross-scale correspondence to model local degradation. The final prediction depends on the class tokens from different scales, which comprehensively considers multi-scale dependencies. With the margin ranking loss, our URanker can accurately rank the order of underwater images of the same scene enhanced by different underwater image enhancement (UIE) algorithms according to their visual quality. To achieve that, we also contribute a dataset, URankerSet, containing sufficient results enhanced by different UIE algorithms and the corresponding perceptual rankings, to train our URanker. Apart from the good performance of URanker, we found that a simple U-shape UIE network can obtain promising performance when it is coupled with our pre-trained URanker as additional supervision. In addition, we also propose a normalization tail that can significantly improve the performance of UIE networks. Extensive experiments demonstrate the state-of-the-art performance of our method. The key designs of our method are discussed. We will release our dataset and code.
Image Harmonization by Matching Regional References
Apr 10, 2022
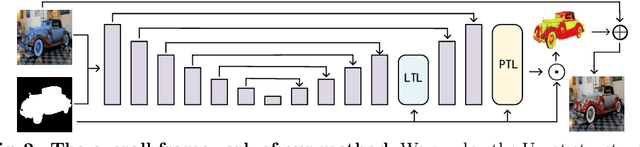
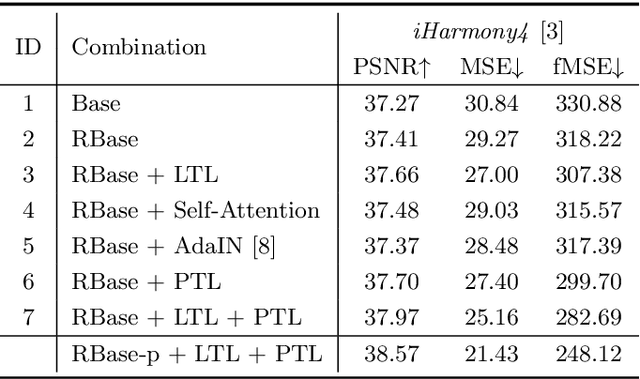
To achieve visual consistency in composite images, recent image harmonization methods typically summarize the appearance pattern of global background and apply it to the global foreground without location discrepancy. However, for a real image, the appearances (illumination, color temperature, saturation, hue, texture, etc) of different regions can vary significantly. So previous methods, which transfer the appearance globally, are not optimal. Trying to solve this issue, we firstly match the contents between the foreground and background and then adaptively adjust every foreground location according to the appearance of its content-related background regions. Further, we design a residual reconstruction strategy, that uses the predicted residual to adjust the appearance, and the composite foreground to reserve the image details. Extensive experiments demonstrate the effectiveness of our method. The source code will be available publicly.
BusyHands: A Hand-Tool Interaction Database for Assembly Tasks Semantic Segmentation
Feb 19, 2019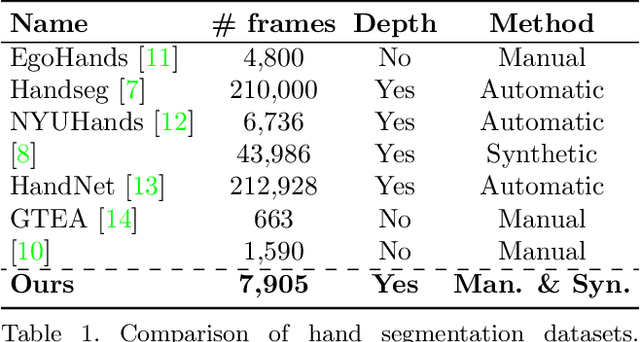

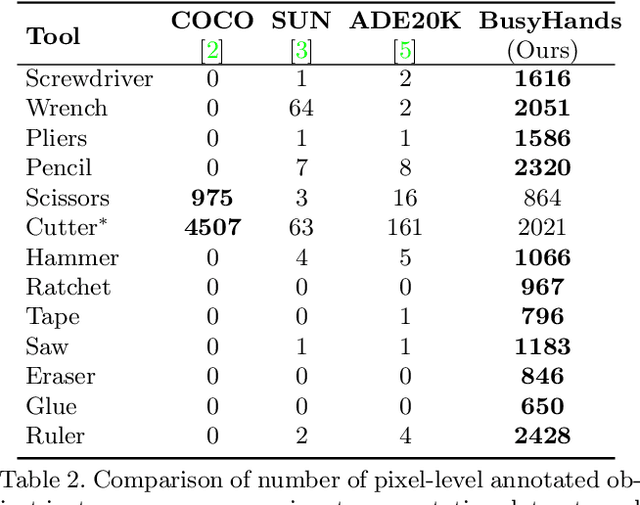

Visual segmentation has seen tremendous advancement recently with ready solutions for a wide variety of scene types, including human hands and other body parts. However, focus on segmentation of human hands while performing complex tasks, such as manual assembly, is still severely lacking. Segmenting hands from tools, work pieces, background and other body parts is extremely difficult because of self-occlusions and intricate hand grips and poses. In this paper we introduce BusyHands, a large open dataset of pixel-level annotated images of hands performing 13 different tool-based assembly tasks, from both real-world captures and virtual-world renderings. A total of 7906 samples are included in our first-in-kind dataset, with both RGB and depth images as obtained from a Kinect V2 camera and Blender. We evaluate several state-of-the-art semantic segmentation methods on our dataset as a proposed performance benchmark.