 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBluRef: Unsupervised Image Deblurring with Dense-Matching References
Mar 15, 2026This paper introduces a novel unsupervised approach for image deblurring that utilizes a simple process for training data collection, thereby enhancing the applicability and effectiveness of deblurring methods. Our technique does not require meticulously paired data of blurred and corresponding sharp images; instead, it uses unpaired blurred and sharp images of similar scenes to generate pseudo-ground truth data by leveraging a dense matching model to identify correspondences between a blurry image and reference sharp images. Thanks to the simplicity of the training data collection process, our approach does not rely on existing paired training data or pre-trained networks, making it more adaptable to various scenarios and suitable for networks of different sizes, including those designed for low-resource devices. We demonstrate that this novel approach achieves state-of-the-art performance, marking a significant advancement in the field of image deblurring.
CountEx: Fine-Grained Counting via Exemplars and Exclusion
Feb 23, 2026This paper presents CountEx, a discriminative visual counting framework designed to address a key limitation of existing prompt-based methods: the inability to explicitly exclude visually similar distractors. While current approaches allow users to specify what to count via inclusion prompts, they often struggle in cluttered scenes with confusable object categories, leading to ambiguity and overcounting. CountEx enables users to express both inclusion and exclusion intent, specifying what to count and what to ignore, through multimodal prompts including natural language descriptions and optional visual exemplars. At the core of CountEx is a novel Discriminative Query Refinement module, which jointly reasons over inclusion and exclusion cues by first identifying shared visual features, then isolating exclusion-specific patterns, and finally applying selective suppression to refine the counting query. To support systematic evaluation of fine-grained counting methods, we introduce CoCount, a benchmark comprising 1,780 videos and 10,086 annotated frames across 97 category pairs. Experiments show that CountEx achieves substantial improvements over state-of-the-art methods for counting objects from both known and novel categories. The data and code are available at https://github.com/bbvisual/CountEx.
MoBind: Motion Binding for Fine-Grained IMU-Video Pose Alignment
Feb 22, 2026We aim to learn a joint representation between inertial measurement unit (IMU) signals and 2D pose sequences extracted from video, enabling accurate cross-modal retrieval, temporal synchronization, subject and body-part localization, and action recognition. To this end, we introduce MoBind, a hierarchical contrastive learning framework designed to address three challenges: (1) filtering out irrelevant visual background, (2) modeling structured multi-sensor IMU configurations, and (3) achieving fine-grained, sub-second temporal alignment. To isolate motion-relevant cues, MoBind aligns IMU signals with skeletal motion sequences rather than raw pixels. We further decompose full-body motion into local body-part trajectories, pairing each with its corresponding IMU to enable semantically grounded multi-sensor alignment. To capture detailed temporal correspondence, MoBind employs a hierarchical contrastive strategy that first aligns token-level temporal segments, then fuses local (body-part) alignment with global (body-wide) motion aggregation. Evaluated on mRi, TotalCapture, and EgoHumans, MoBind consistently outperforms strong baselines across all four tasks, demonstrating robust fine-grained temporal alignment while preserving coarse semantic consistency across modalities. Code is available at https://github.com/bbvisual/ MoBind.
Can Current AI Models Count What We Mean, Not What They See? A Benchmark and Systematic Evaluation
Sep 17, 2025Visual counting is a fundamental yet challenging task, especially when users need to count objects of a specific type in complex scenes. While recent models, including class-agnostic counting models and large vision-language models (VLMs), show promise in counting tasks, their ability to perform fine-grained, intent-driven counting remains unclear. In this paper, we introduce PairTally, a benchmark dataset specifically designed to evaluate fine-grained visual counting. Each of the 681 high-resolution images in PairTally contains two object categories, requiring models to distinguish and count based on subtle differences in shape, size, color, or semantics. The dataset includes both inter-category (distinct categories) and intra-category (closely related subcategories) settings, making it suitable for rigorous evaluation of selective counting capabilities. We benchmark a variety of state-of-the-art models, including exemplar-based methods, language-prompted models, and large VLMs. Our results show that despite recent advances, current models struggle to reliably count what users intend, especially in fine-grained and visually ambiguous cases. PairTally provides a new foundation for diagnosing and improving fine-grained visual counting systems.
DualMat: PBR Material Estimation via Coherent Dual-Path Diffusion
Aug 07, 2025We present DualMat, a novel dual-path diffusion framework for estimating Physically Based Rendering (PBR) materials from single images under complex lighting conditions. Our approach operates in two distinct latent spaces: an albedo-optimized path leveraging pretrained visual knowledge through RGB latent space, and a material-specialized path operating in a compact latent space designed for precise metallic and roughness estimation. To ensure coherent predictions between the albedo-optimized and material-specialized paths, we introduce feature distillation during training. We employ rectified flow to enhance efficiency by reducing inference steps while maintaining quality. Our framework extends to high-resolution and multi-view inputs through patch-based estimation and cross-view attention, enabling seamless integration into image-to-3D pipelines. DualMat achieves state-of-the-art performance on both Objaverse and real-world data, significantly outperforming existing methods with up to 28% improvement in albedo estimation and 39% reduction in metallic-roughness prediction errors.
Few-shot Personalized Scanpath Prediction
Apr 07, 2025A personalized model for scanpath prediction provides insights into the visual preferences and attention patterns of individual subjects. However, existing methods for training scanpath prediction models are data-intensive and cannot be effectively personalized to new individuals with only a few available examples. In this paper, we propose few-shot personalized scanpath prediction task (FS-PSP) and a novel method to address it, which aims to predict scanpaths for an unseen subject using minimal support data of that subject's scanpath behavior. The key to our method's adaptability is the Subject-Embedding Network (SE-Net), specifically designed to capture unique, individualized representations for each subject's scanpaths. SE-Net generates subject embeddings that effectively distinguish between subjects while minimizing variability among scanpaths from the same individual. The personalized scanpath prediction model is then conditioned on these subject embeddings to produce accurate, personalized results. Experiments on multiple eye-tracking datasets demonstrate that our method excels in FS-PSP settings and does not require any fine-tuning steps at test time. Code is available at: https://github.com/cvlab-stonybrook/few-shot-scanpath
Look Hear: Gaze Prediction for Speech-directed Human Attention
Jul 28, 2024
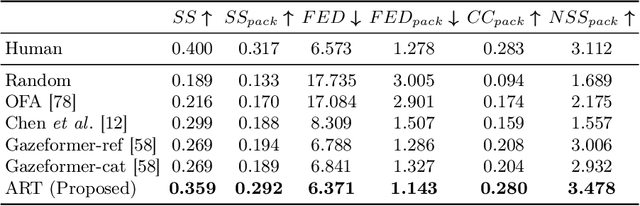

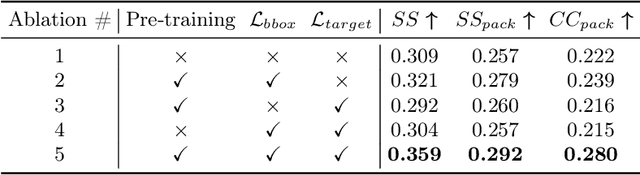
For computer systems to effectively interact with humans using spoken language, they need to understand how the words being generated affect the users' moment-by-moment attention. Our study focuses on the incremental prediction of attention as a person is seeing an image and hearing a referring expression defining the object in the scene that should be fixated by gaze. To predict the gaze scanpaths in this incremental object referral task, we developed the Attention in Referral Transformer model or ART, which predicts the human fixations spurred by each word in a referring expression. ART uses a multimodal transformer encoder to jointly learn gaze behavior and its underlying grounding tasks, and an autoregressive transformer decoder to predict, for each word, a variable number of fixations based on fixation history. To train ART, we created RefCOCO-Gaze, a large-scale dataset of 19,738 human gaze scanpaths, corresponding to 2,094 unique image-expression pairs, from 220 participants performing our referral task. In our quantitative and qualitative analyses, ART not only outperforms existing methods in scanpath prediction, but also appears to capture several human attention patterns, such as waiting, scanning, and verification.
Detecting Omissions in Geographic Maps through Computer Vision
Jul 15, 2024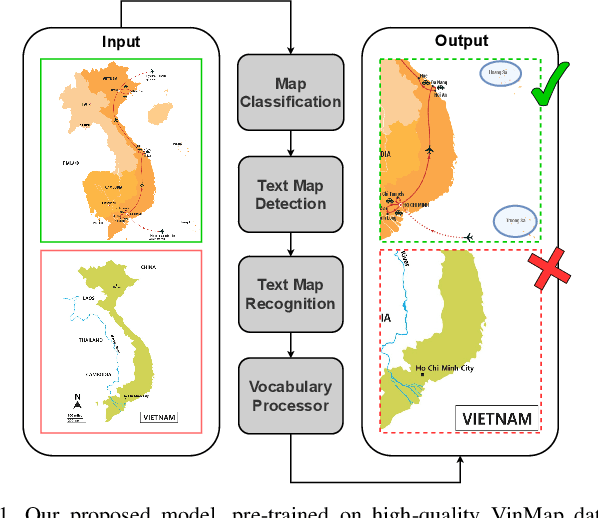
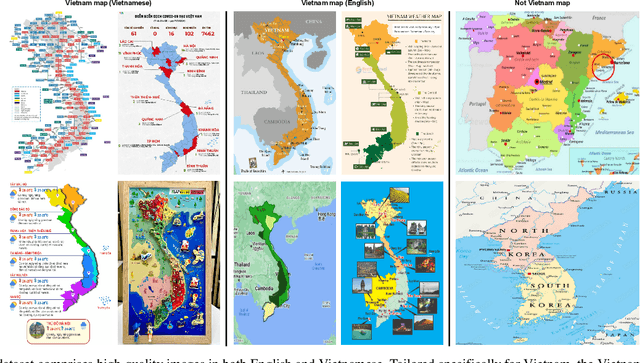
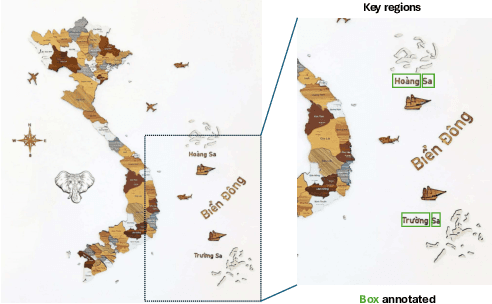
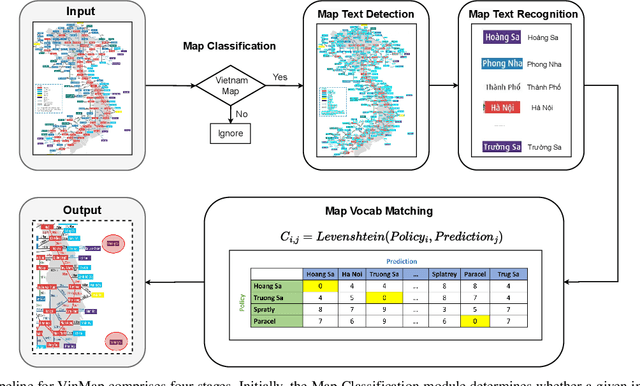
This paper explores the application of computer vision technologies to the analysis of maps, an area with substantial historical, cultural, and political significance. Our focus is on developing and evaluating a method for automatically identifying maps that depict specific regions and feature landmarks with designated names, a task that involves complex challenges due to the diverse styles and methods used in map creation. We address three main subtasks: differentiating maps from non-maps, verifying the accuracy of the region depicted, and confirming the presence or absence of particular landmark names through advanced text recognition techniques. Our approach utilizes a Convolutional Neural Network and transfer learning to differentiate maps from non-maps, verify the accuracy of depicted regions, and confirm landmark names through advanced text recognition. We also introduce the VinMap dataset, containing annotated map images of Vietnam, to train and test our method. Experiments on this dataset demonstrate that our technique achieves F1-score of 85.51% for identifying maps excluding specific territorial landmarks. This result suggests practical utility and indicates areas for future improvement.
Diffusion-Refined VQA Annotations for Semi-Supervised Gaze Following
Jun 04, 2024Training gaze following models requires a large number of images with gaze target coordinates annotated by human annotators, which is a laborious and inherently ambiguous process. We propose the first semi-supervised method for gaze following by introducing two novel priors to the task. We obtain the first prior using a large pretrained Visual Question Answering (VQA) model, where we compute Grad-CAM heatmaps by `prompting' the VQA model with a gaze following question. These heatmaps can be noisy and not suited for use in training. The need to refine these noisy annotations leads us to incorporate a second prior. We utilize a diffusion model trained on limited human annotations and modify the reverse sampling process to refine the Grad-CAM heatmaps. By tuning the diffusion process we achieve a trade-off between the human annotation prior and the VQA heatmap prior, which retains the useful VQA prior information while exhibiting similar properties to the training data distribution. Our method outperforms simple pseudo-annotation generation baselines on the GazeFollow image dataset. More importantly, our pseudo-annotation strategy, applied to a widely used supervised gaze following model (VAT), reduces the annotation need by 50%. Our method also performs the best on the VideoAttentionTarget dataset.
HOIST-Former: Hand-held Objects Identification, Segmentation, and Tracking in the Wild
Apr 22, 2024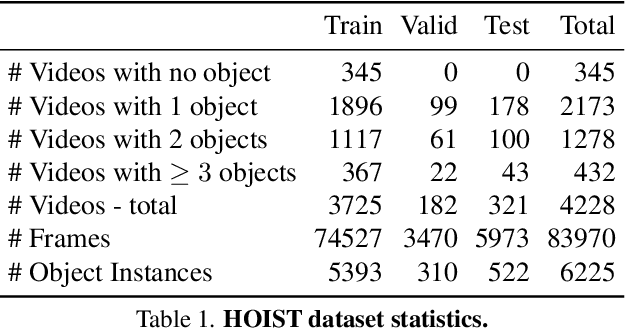
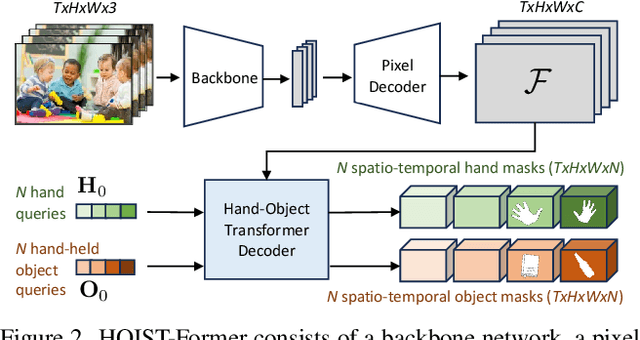
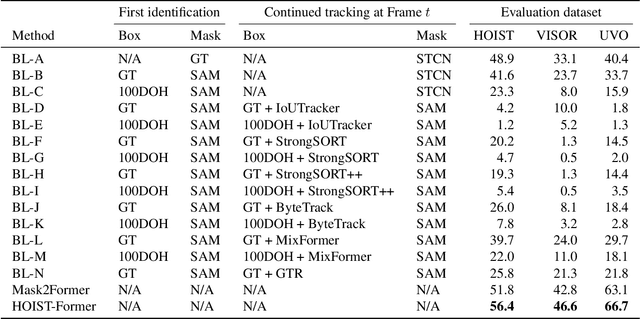
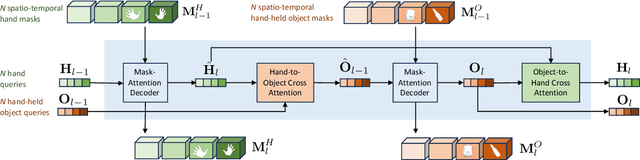
We address the challenging task of identifying, segmenting, and tracking hand-held objects, which is crucial for applications such as human action segmentation and performance evaluation. This task is particularly challenging due to heavy occlusion, rapid motion, and the transitory nature of objects being hand-held, where an object may be held, released, and subsequently picked up again. To tackle these challenges, we have developed a novel transformer-based architecture called HOIST-Former. HOIST-Former is adept at spatially and temporally segmenting hands and objects by iteratively pooling features from each other, ensuring that the processes of identification, segmentation, and tracking of hand-held objects depend on the hands' positions and their contextual appearance. We further refine HOIST-Former with a contact loss that focuses on areas where hands are in contact with objects. Moreover, we also contribute an in-the-wild video dataset called HOIST, which comprises 4,125 videos complete with bounding boxes, segmentation masks, and tracking IDs for hand-held objects. Through experiments on the HOIST dataset and two additional public datasets, we demonstrate the efficacy of HOIST-Former in segmenting and tracking hand-held objects.