 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenVO: Open-World Visual Odometry with Temporal Dynamics Awareness
Feb 22, 2026We introduce OpenVO, a novel framework for Open-world Visual Odometry (VO) with temporal awareness under limited input conditions. OpenVO effectively estimates real-world-scale ego-motion from monocular dashcam footage with varying observation rates and uncalibrated cameras, enabling robust trajectory dataset construction from rare driving events recorded in dashcam. Existing VO methods are trained on fixed observation frequency (e.g., 10Hz or 12Hz), completely overlooking temporal dynamics information. Many prior methods also require calibrated cameras with known intrinsic parameters. Consequently, their performance degrades when (1) deployed under unseen observation frequencies or (2) applied to uncalibrated cameras. These significantly limit their generalizability to many downstream tasks, such as extracting trajectories from dashcam footage. To address these challenges, OpenVO (1) explicitly encodes temporal dynamics information within a two-frame pose regression framework and (2) leverages 3D geometric priors derived from foundation models. We validate our method on three major autonomous-driving benchmarks - KITTI, nuScenes, and Argoverse 2 - achieving more than 20 performance improvement over state-of-the-art approaches. Under varying observation rate settings, our method is significantly more robust, achieving 46%-92% lower errors across all metrics. These results demonstrate the versatility of OpenVO for real-world 3D reconstruction and diverse downstream applications.
HA-RDet: Hybrid Anchor Rotation Detector for Oriented Object Detection
Dec 18, 2024



Oriented object detection in aerial images poses a significant challenge due to their varying sizes and orientations. Current state-of-the-art detectors typically rely on either two-stage or one-stage approaches, often employing Anchor-based strategies, which can result in computationally expensive operations due to the redundant number of generated anchors during training. In contrast, Anchor-free mechanisms offer faster processing but suffer from a reduction in the number of training samples, potentially impacting detection accuracy. To address these limitations, we propose the Hybrid-Anchor Rotation Detector (HA-RDet), which combines the advantages of both anchor-based and anchor-free schemes for oriented object detection. By utilizing only one preset anchor for each location on the feature maps and refining these anchors with our Orientation-Aware Convolution technique, HA-RDet achieves competitive accuracies, including 75.41 mAP on DOTA-v1, 65.3 mAP on DIOR-R, and 90.2 mAP on HRSC2016, against current anchor-based state-of-the-art methods, while significantly reducing computational resources.
Open-Ended 3D Point Cloud Instance Segmentation
Aug 21, 2024Open-Vocab 3D Instance Segmentation methods (OV-3DIS) have recently demonstrated their ability to generalize to unseen objects. However, these methods still depend on predefined class names during testing, restricting the autonomy of agents. To mitigate this constraint, we propose a novel problem termed Open-Ended 3D Instance Segmentation (OE-3DIS), which eliminates the necessity for predefined class names during testing. Moreover, we contribute a comprehensive set of strong baselines, derived from OV-3DIS approaches and leveraging 2D Multimodal Large Language Models. To assess the performance of our OE-3DIS system, we introduce a novel Open-Ended score, evaluating both the semantic and geometric quality of predicted masks and their associated class names, alongside the standard AP score. Our approach demonstrates significant performance improvements over the baselines on the ScanNet200 and ScanNet++ datasets. Remarkably, our method surpasses the performance of Open3DIS, the current state-of-the-art method in OV-3DIS, even in the absence of ground-truth object class names.
Detecting Omissions in Geographic Maps through Computer Vision
Jul 15, 2024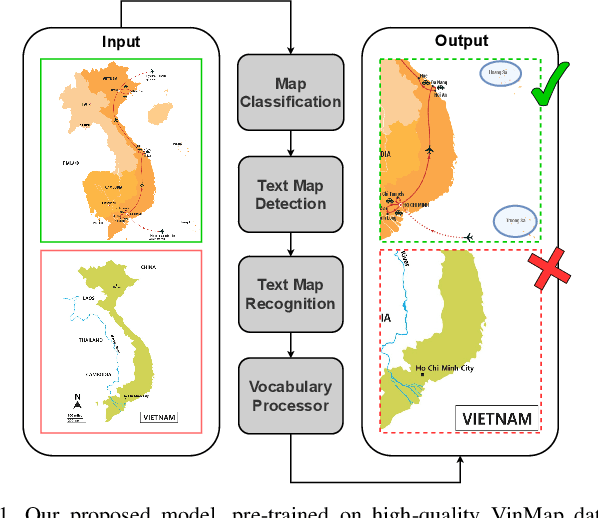
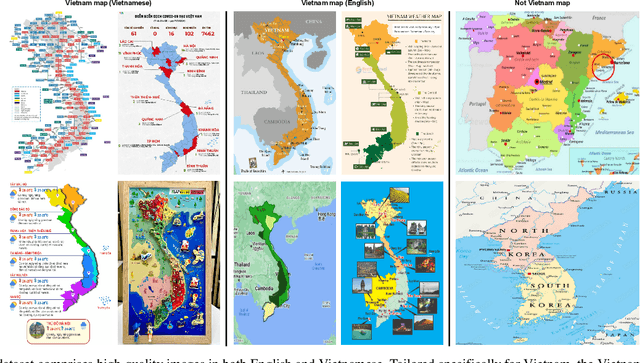
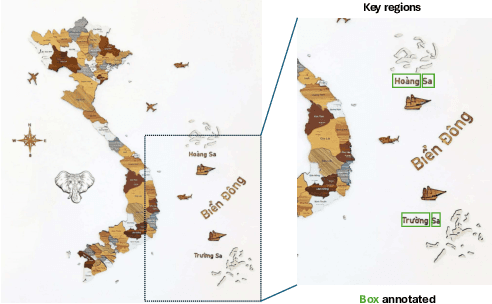
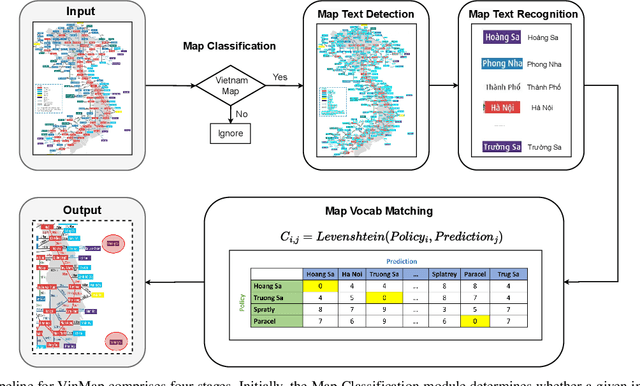
This paper explores the application of computer vision technologies to the analysis of maps, an area with substantial historical, cultural, and political significance. Our focus is on developing and evaluating a method for automatically identifying maps that depict specific regions and feature landmarks with designated names, a task that involves complex challenges due to the diverse styles and methods used in map creation. We address three main subtasks: differentiating maps from non-maps, verifying the accuracy of the region depicted, and confirming the presence or absence of particular landmark names through advanced text recognition techniques. Our approach utilizes a Convolutional Neural Network and transfer learning to differentiate maps from non-maps, verify the accuracy of depicted regions, and confirm landmark names through advanced text recognition. We also introduce the VinMap dataset, containing annotated map images of Vietnam, to train and test our method. Experiments on this dataset demonstrate that our technique achieves F1-score of 85.51% for identifying maps excluding specific territorial landmarks. This result suggests practical utility and indicates areas for future improvement.
Open3DIS: Open-vocabulary 3D Instance Segmentation with 2D Mask Guidance
Dec 17, 2023



We introduce Open3DIS, a novel solution designed to tackle the problem of Open-Vocabulary Instance Segmentation within 3D scenes. Objects within 3D environments exhibit diverse shapes, scales, and colors, making precise instance-level identification a challenging task. Recent advancements in Open-Vocabulary scene understanding have made significant strides in this area by employing class-agnostic 3D instance proposal networks for object localization and learning queryable features for each 3D mask. While these methods produce high-quality instance proposals, they struggle with identifying small-scale and geometrically ambiguous objects. The key idea of our method is a new module that aggregates 2D instance masks across frames and maps them to geometrically coherent point cloud regions as high-quality object proposals addressing the above limitations. These are then combined with 3D class-agnostic instance proposals to include a wide range of objects in the real world. To validate our approach, we conducted experiments on three prominent datasets, including ScanNet200, S3DIS, and Replica, demonstrating significant performance gains in segmenting objects with diverse categories over the state-of-the-art approaches.