 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnti-I2V: Safeguarding your photos from malicious image-to-video generation
Mar 25, 2026Advances in diffusion-based video generation models, while significantly improving human animation, poses threats of misuse through the creation of fake videos from a specific person's photo and text prompts. Recent efforts have focused on adversarial attacks that introduce crafted perturbations to protect images from diffusion-based models. However, most existing approaches target image generation, while relatively few explicitly address image-to-video diffusion models (VDMs), and most primarily focus on UNet-based architectures. Hence, their effectiveness against Diffusion Transformer (DiT) models remains largely under-explored, as these models demonstrate improved feature retention, and stronger temporal consistency due to larger capacity and advanced attention mechanisms. In this work, we introduce Anti-I2V, a novel defense against malicious human image-to-video generation, applicable across diverse diffusion backbones. Instead of restricting noise updates to the RGB space, Anti-I2V operates in both the $L$*$a$*$b$* and frequency domains, improving robustness and concentrating on salient pixels. We then identify the network layers that capture the most distinct semantic features during the denoising process to design appropriate training objectives that maximize degradation of temporal coherence and generation fidelity. Through extensive validation, Anti-I2V demonstrates state-of-the-art defense performance against diverse video diffusion models, offering an effective solution to the problem.
InverFill: One-Step Inversion for Enhanced Few-Step Diffusion Inpainting
Mar 24, 2026Recent diffusion-based models achieve photorealism in image inpainting but require many sampling steps, limiting practical use. Few-step text-to-image models offer faster generation, but naively applying them to inpainting yields poor harmonization and artifacts between the background and inpainted region. We trace this cause to random Gaussian noise initialization, which under low function evaluations causes semantic misalignment and reduced fidelity. To overcome this, we propose InverFill, a one-step inversion method tailored for inpainting that injects semantic information from the input masked image into the initial noise, enabling high-fidelity few-step inpainting. Instead of training inpainting models, InverFill leverages few-step text-to-image models in a blended sampling pipeline with semantically aligned noise as input, significantly improving vanilla blended sampling and even matching specialized inpainting models at low NFEs. Moreover, InverFill does not require real-image supervision and only adds minimal inference overhead. Extensive experiments show that InverFill consistently boosts baseline few-step models, improving image quality and text coherence without costly retraining or heavy iterative optimization.
BluRef: Unsupervised Image Deblurring with Dense-Matching References
Mar 15, 2026This paper introduces a novel unsupervised approach for image deblurring that utilizes a simple process for training data collection, thereby enhancing the applicability and effectiveness of deblurring methods. Our technique does not require meticulously paired data of blurred and corresponding sharp images; instead, it uses unpaired blurred and sharp images of similar scenes to generate pseudo-ground truth data by leveraging a dense matching model to identify correspondences between a blurry image and reference sharp images. Thanks to the simplicity of the training data collection process, our approach does not rely on existing paired training data or pre-trained networks, making it more adaptable to various scenarios and suitable for networks of different sizes, including those designed for low-resource devices. We demonstrate that this novel approach achieves state-of-the-art performance, marking a significant advancement in the field of image deblurring.
PixelRush: Ultra-Fast, Training-Free High-Resolution Image Generation via One-step Diffusion
Feb 13, 2026Pre-trained diffusion models excel at generating high-quality images but remain inherently limited by their native training resolution. Recent training-free approaches have attempted to overcome this constraint by introducing interventions during the denoising process; however, these methods incur substantial computational overhead, often requiring more than five minutes to produce a single 4K image. In this paper, we present PixelRush, the first tuning-free framework for practical high-resolution text-to-image generation. Our method builds upon the established patch-based inference paradigm but eliminates the need for multiple inversion and regeneration cycles. Instead, PixelRush enables efficient patch-based denoising within a low-step regime. To address artifacts introduced by patch blending in few-step generation, we propose a seamless blending strategy. Furthermore, we mitigate over-smoothing effects through a noise injection mechanism. PixelRush delivers exceptional efficiency, generating 4K images in approximately 20 seconds representing a 10$\times$ to 35$\times$ speedup over state-of-the-art methods while maintaining superior visual fidelity. Extensive experiments validate both the performance gains and the quality of outputs achieved by our approach.
Featuremetric benchmarking: Quantum computer benchmarks based on circuit features
Apr 17, 2025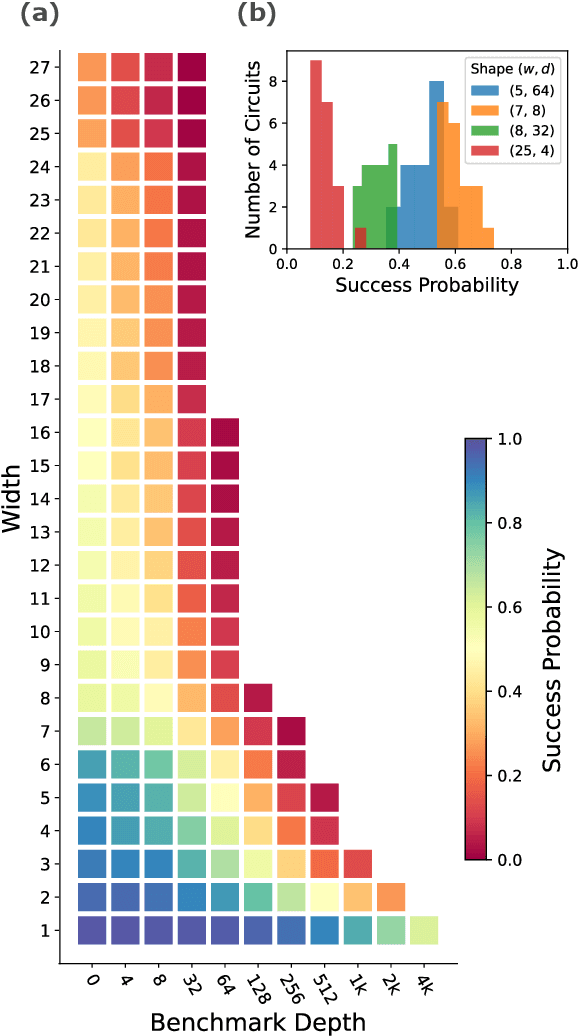
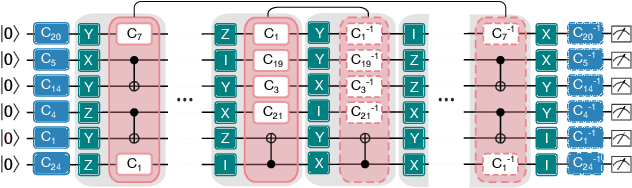
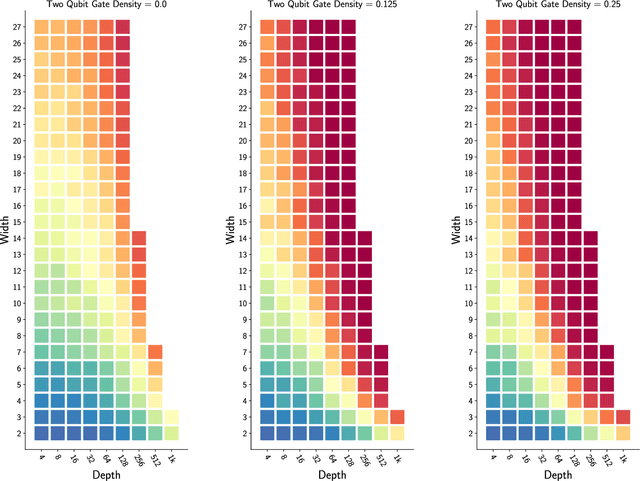
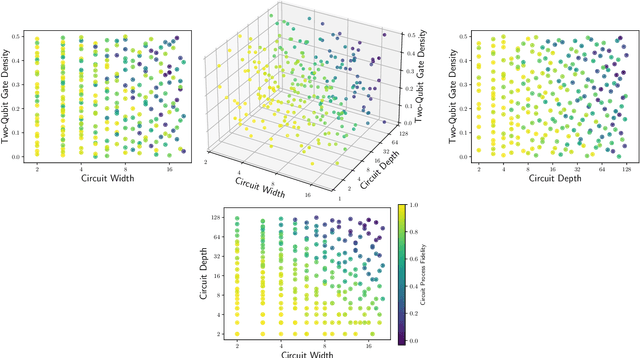
Benchmarks that concisely summarize the performance of many-qubit quantum computers are essential for measuring progress towards the goal of useful quantum computation. In this work, we present a benchmarking framework that is based on quantifying how a quantum computer's performance on quantum circuits varies as a function of features of those circuits, such as circuit depth, width, two-qubit gate density, problem input size, or algorithmic depth. Our featuremetric benchmarking framework generalizes volumetric benchmarking -- a widely-used methodology that quantifies performance versus circuit width and depth -- and we show that it enables richer and more faithful models of quantum computer performance. We demonstrate featuremetric benchmarking with example benchmarks run on IBM Q and IonQ systems of up to 27 qubits, and we show how to produce performance summaries from the data using Gaussian process regression. Our data analysis methods are also of interest in the special case of volumetric benchmarking, as they enable the creation of intuitive two-dimensional capability regions using data from few circuits.
Early Prediction of Alzheimer's and Related Dementias: A Machine Learning Approach Utilizing Social Determinants of Health Data
Mar 20, 2025Alzheimer's disease and related dementias (AD/ADRD) represent a growing healthcare crisis affecting over 6 million Americans. While genetic factors play a crucial role, emerging research reveals that social determinants of health (SDOH) significantly influence both the risk and progression of cognitive functioning, such as cognitive scores and cognitive decline. This report examines how these social, environmental, and structural factors impact cognitive health trajectories, with a particular focus on Hispanic populations, who face disproportionate risk for AD/ADRD. Using data from the Mexican Health and Aging Study (MHAS) and its cognitive assessment sub study (Mex-Cog), we employed ensemble of regression trees models to predict 4-year and 9-year cognitive scores and cognitive decline based on SDOH. This approach identified key predictive SDOH factors to inform potential multilevel interventions to address cognitive health disparities in this population.
AF-KAN: Activation Function-Based Kolmogorov-Arnold Networks for Efficient Representation Learning
Mar 08, 2025Kolmogorov-Arnold Networks (KANs) have inspired numerous works exploring their applications across a wide range of scientific problems, with the potential to replace Multilayer Perceptrons (MLPs). While many KANs are designed using basis and polynomial functions, such as B-splines, ReLU-KAN utilizes a combination of ReLU functions to mimic the structure of B-splines and take advantage of ReLU's speed. However, ReLU-KAN is not built for multiple inputs, and its limitations stem from ReLU's handling of negative values, which can restrict feature extraction. To address these issues, we introduce Activation Function-Based Kolmogorov-Arnold Networks (AF-KAN), expanding ReLU-KAN with various activations and their function combinations. This novel KAN also incorporates parameter reduction methods, primarily attention mechanisms and data normalization, to enhance performance on image classification datasets. We explore different activation functions, function combinations, grid sizes, and spline orders to validate the effectiveness of AF-KAN and determine its optimal configuration. In the experiments, AF-KAN significantly outperforms MLP, ReLU-KAN, and other KANs with the same parameter count. It also remains competitive even when using fewer than 6 to 10 times the parameters while maintaining the same network structure. However, AF-KAN requires a longer training time and consumes more FLOPs. The repository for this work is available at https://github.com/hoangthangta/All-KAN.
PRKAN: Parameter-Reduced Kolmogorov-Arnold Networks
Jan 13, 2025Kolmogorov-Arnold Networks (KANs) represent an innovation in neural network architectures, offering a compelling alternative to Multi-Layer Perceptrons (MLPs) in models such as Convolutional Neural Networks (CNNs), Recurrent Neural Networks (RNNs), and Transformers. By advancing network design, KANs are driving groundbreaking research and enabling transformative applications across various scientific domains involving neural networks. However, existing KANs often require significantly more parameters in their network layers compared to MLPs. To address this limitation, this paper introduces PRKANs (\textbf{P}arameter-\textbf{R}educed \textbf{K}olmogorov-\textbf{A}rnold \textbf{N}etworks), which employ several methods to reduce the parameter count in KAN layers, making them comparable to MLP layers. Experimental results on the MNIST and Fashion-MNIST datasets demonstrate that PRKANs with attention mechanisms outperform several existing KANs and rival the performance of MLPs, albeit with slightly longer training times. Furthermore, the study highlights the advantages of Gaussian Radial Basis Functions (GRBFs) and layer normalization in KAN designs. The repository for this work is available at: \url{https://github.com/hoangthangta/All-KAN}.
Semise: Semi-supervised learning for severity representation in medical image
Jan 07, 2025This paper introduces SEMISE, a novel method for representation learning in medical imaging that combines self-supervised and supervised learning. By leveraging both labeled and augmented data, SEMISE addresses the challenge of data scarcity and enhances the encoder's ability to extract meaningful features. This integrated approach leads to more informative representations, improving performance on downstream tasks. As result, our approach achieved a 12% improvement in classification and a 3% improvement in segmentation, outperforming existing methods. These results demonstrate the potential of SIMESE to advance medical image analysis and offer more accurate solutions for healthcare applications, particularly in contexts where labeled data is limited.
Enhancing Fine-grained Image Classification through Attentive Batch Training
Dec 27, 2024Fine-grained image classification, which is a challenging task in computer vision, requires precise differentiation among visually similar object categories. In this paper, we propose 1) a novel module called Residual Relationship Attention (RRA) that leverages the relationships between images within each training batch to effectively integrate visual feature vectors of batch images and 2) a novel technique called Relationship Position Encoding (RPE), which encodes the positions of relationships between original images in a batch and effectively preserves the relationship information between images within the batch. Additionally, we design a novel framework, namely Relationship Batch Integration (RBI), which utilizes RRA in conjunction with RPE, allowing the discernment of vital visual features that may remain elusive when examining a singular image representative of a particular class. Through extensive experiments, our proposed method demonstrates significant improvements in the accuracy of different fine-grained classifiers, with an average increase of $(+2.78\%)$ and $(+3.83\%)$ on the CUB200-2011 and Stanford Dog datasets, respectively, while achieving a state-of-the-art results $(95.79\%)$ on the Stanford Dog dataset. Despite not achieving the same level of improvement as in fine-grained image classification, our method still demonstrates its prowess in leveraging general image classification by attaining a state-of-the-art result of $(93.71\%)$ on the Tiny-Imagenet dataset. Furthermore, our method serves as a plug-in refinement module and can be easily integrated into different networks.