 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSwiftEdit: Lightning Fast Text-Guided Image Editing via One-Step Diffusion
Dec 05, 2024Recent advances in text-guided image editing enable users to perform image edits through simple text inputs, leveraging the extensive priors of multi-step diffusion-based text-to-image models. However, these methods often fall short of the speed demands required for real-world and on-device applications due to the costly multi-step inversion and sampling process involved. In response to this, we introduce SwiftEdit, a simple yet highly efficient editing tool that achieve instant text-guided image editing (in 0.23s). The advancement of SwiftEdit lies in its two novel contributions: a one-step inversion framework that enables one-step image reconstruction via inversion and a mask-guided editing technique with our proposed attention rescaling mechanism to perform localized image editing. Extensive experiments are provided to demonstrate the effectiveness and efficiency of SwiftEdit. In particular, SwiftEdit enables instant text-guided image editing, which is extremely faster than previous multi-step methods (at least 50 times faster) while maintain a competitive performance in editing results. Our project page is at: https://swift-edit.github.io/
EditScout: Locating Forged Regions from Diffusion-based Edited Images with Multimodal LLM
Dec 05, 2024



Image editing technologies are tools used to transform, adjust, remove, or otherwise alter images. Recent research has significantly improved the capabilities of image editing tools, enabling the creation of photorealistic and semantically informed forged regions that are nearly indistinguishable from authentic imagery, presenting new challenges in digital forensics and media credibility. While current image forensic techniques are adept at localizing forged regions produced by traditional image manipulation methods, current capabilities struggle to localize regions created by diffusion-based techniques. To bridge this gap, we present a novel framework that integrates a multimodal Large Language Model (LLM) for enhanced reasoning capabilities to localize tampered regions in images produced by diffusion model-based editing methods. By leveraging the contextual and semantic strengths of LLMs, our framework achieves promising results on MagicBrush, AutoSplice, and PerfBrush (novel diffusion-based dataset) datasets, outperforming previous approaches in mIoU and F1-score metrics. Notably, our method excels on the PerfBrush dataset, a self-constructed test set featuring previously unseen types of edits. Here, where traditional methods typically falter, achieving markedly low scores, our approach demonstrates promising performance.
OpenCIL: Benchmarking Out-of-Distribution Detection in Class-Incremental Learning
Jul 09, 2024



Class incremental learning (CIL) aims to learn a model that can not only incrementally accommodate new classes, but also maintain the learned knowledge of old classes. Out-of-distribution (OOD) detection in CIL is to retain this incremental learning ability, while being able to reject unknown samples that are drawn from different distributions of the learned classes. This capability is crucial to the safety of deploying CIL models in open worlds. However, despite remarkable advancements in the respective CIL and OOD detection, there lacks a systematic and large-scale benchmark to assess the capability of advanced CIL models in detecting OOD samples. To fill this gap, in this study we design a comprehensive empirical study to establish such a benchmark, named $\textbf{OpenCIL}$. To this end, we propose two principled frameworks for enabling four representative CIL models with 15 diverse OOD detection methods, resulting in 60 baseline models for OOD detection in CIL. The empirical evaluation is performed on two popular CIL datasets with six commonly-used OOD datasets. One key observation we find through our comprehensive evaluation is that the CIL models can be severely biased towards the OOD samples and newly added classes when they are exposed to open environments. Motivated by this, we further propose a new baseline for OOD detection in CIL, namely Bi-directional Energy Regularization ($\textbf{BER}$), which is specially designed to mitigate these two biases in different CIL models by having energy regularization on both old and new classes. Its superior performance is justified in our experiments. All codes and datasets are open-source at https://github.com/mala-lab/OpenCIL.
FlexEdit: Flexible and Controllable Diffusion-based Object-centric Image Editing
Mar 28, 2024


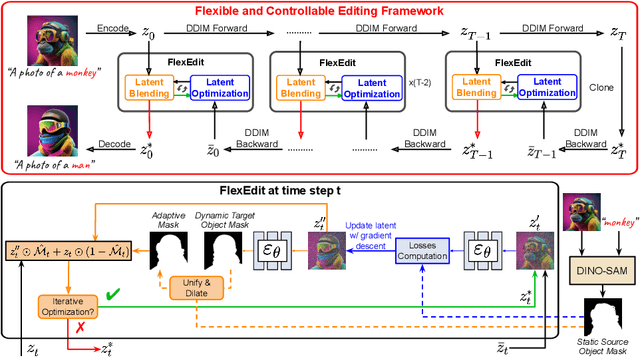
Our work addresses limitations seen in previous approaches for object-centric editing problems, such as unrealistic results due to shape discrepancies and limited control in object replacement or insertion. To this end, we introduce FlexEdit, a flexible and controllable editing framework for objects where we iteratively adjust latents at each denoising step using our FlexEdit block. Initially, we optimize latents at test time to align with specified object constraints. Then, our framework employs an adaptive mask, automatically extracted during denoising, to protect the background while seamlessly blending new content into the target image. We demonstrate the versatility of FlexEdit in various object editing tasks and curate an evaluation test suite with samples from both real and synthetic images, along with novel evaluation metrics designed for object-centric editing. We conduct extensive experiments on different editing scenarios, demonstrating the superiority of our editing framework over recent advanced text-guided image editing methods. Our project page is published at https://flex-edit.github.io/.
Multi-stream Fusion for Class Incremental Learning in Pill Image Classification
Oct 05, 2022
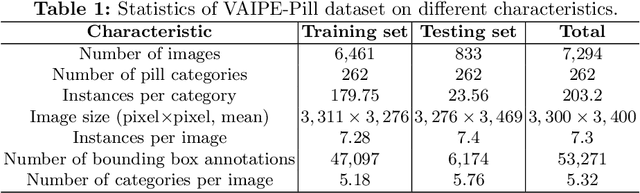

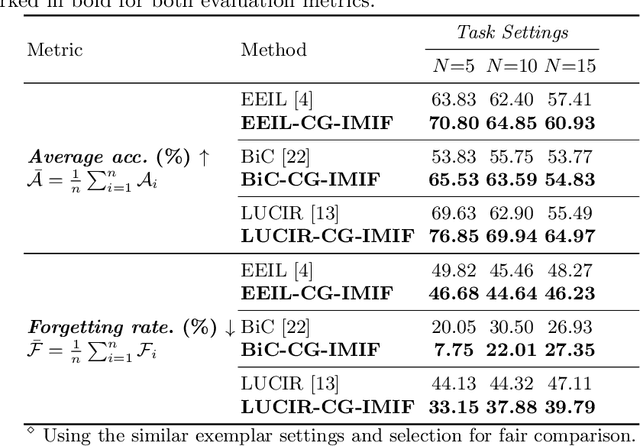
Classifying pill categories from real-world images is crucial for various smart healthcare applications. Although existing approaches in image classification might achieve a good performance on fixed pill categories, they fail to handle novel instances of pill categories that are frequently presented to the learning algorithm. To this end, a trivial solution is to train the model with novel classes. However, this may result in a phenomenon known as catastrophic forgetting, in which the system forgets what it learned in previous classes. In this paper, we address this challenge by introducing the class incremental learning (CIL) ability to traditional pill image classification systems. Specifically, we propose a novel incremental multi-stream intermediate fusion framework enabling incorporation of an additional guidance information stream that best matches the domain of the problem into various state-of-the-art CIL methods. From this framework, we consider color-specific information of pill images as a guidance stream and devise an approach, namely "Color Guidance with Multi-stream intermediate fusion"(CG-IMIF) for solving CIL pill image classification task. We conduct comprehensive experiments on real-world incremental pill image classification dataset, namely VAIPE-PCIL, and find that the CG-IMIF consistently outperforms several state-of-the-art methods by a large margin in different task settings. Our code, data, and trained model are available at https://github.com/vinuni-vishc/CG-IMIF.