 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCT to PET Translation: A Large-scale Dataset and Domain-Knowledge-Guided Diffusion Approach
Oct 29, 2024



Positron Emission Tomography (PET) and Computed Tomography (CT) are essential for diagnosing, staging, and monitoring various diseases, particularly cancer. Despite their importance, the use of PET/CT systems is limited by the necessity for radioactive materials, the scarcity of PET scanners, and the high cost associated with PET imaging. In contrast, CT scanners are more widely available and significantly less expensive. In response to these challenges, our study addresses the issue of generating PET images from CT images, aiming to reduce both the medical examination cost and the associated health risks for patients. Our contributions are twofold: First, we introduce a conditional diffusion model named CPDM, which, to our knowledge, is one of the initial attempts to employ a diffusion model for translating from CT to PET images. Second, we provide the largest CT-PET dataset to date, comprising 2,028,628 paired CT-PET images, which facilitates the training and evaluation of CT-to-PET translation models. For the CPDM model, we incorporate domain knowledge to develop two conditional maps: the Attention map and the Attenuation map. The former helps the diffusion process focus on areas of interest, while the latter improves PET data correction and ensures accurate diagnostic information. Experimental evaluations across various benchmarks demonstrate that CPDM surpasses existing methods in generating high-quality PET images in terms of multiple metrics. The source code and data samples are available at https://github.com/thanhhff/CPDM.
FedGrad: Mitigating Backdoor Attacks in Federated Learning Through Local Ultimate Gradients Inspection
Apr 29, 2023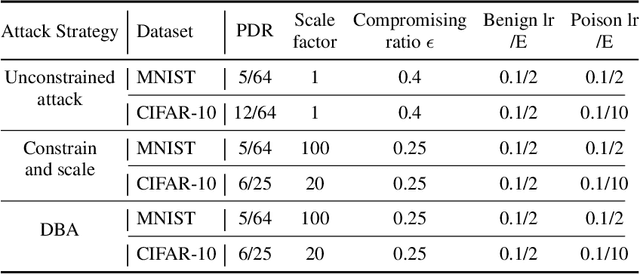
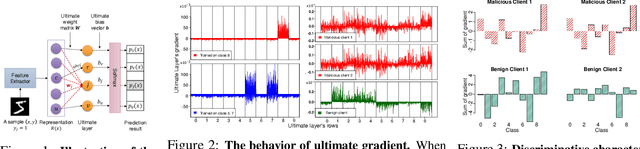
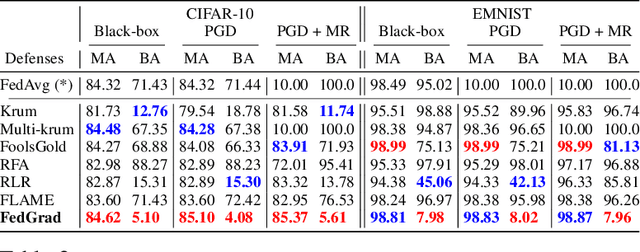
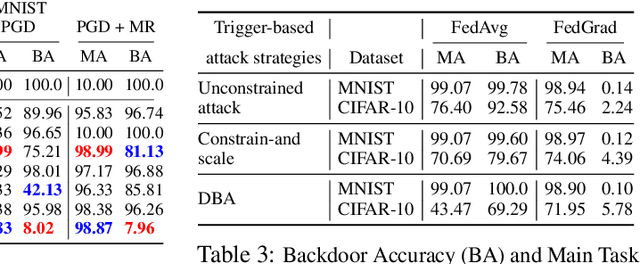
Federated learning (FL) enables multiple clients to train a model without compromising sensitive data. The decentralized nature of FL makes it susceptible to adversarial attacks, especially backdoor insertion during training. Recently, the edge-case backdoor attack employing the tail of the data distribution has been proposed as a powerful one, raising questions about the shortfall in current defenses' robustness guarantees. Specifically, most existing defenses cannot eliminate edge-case backdoor attacks or suffer from a trade-off between backdoor-defending effectiveness and overall performance on the primary task. To tackle this challenge, we propose FedGrad, a novel backdoor-resistant defense for FL that is resistant to cutting-edge backdoor attacks, including the edge-case attack, and performs effectively under heterogeneous client data and a large number of compromised clients. FedGrad is designed as a two-layer filtering mechanism that thoroughly analyzes the ultimate layer's gradient to identify suspicious local updates and remove them from the aggregation process. We evaluate FedGrad under different attack scenarios and show that it significantly outperforms state-of-the-art defense mechanisms. Notably, FedGrad can almost 100% correctly detect the malicious participants, thus providing a significant reduction in the backdoor effect (e.g., backdoor accuracy is less than 8%) while not reducing the main accuracy on the primary task.
Multi-stream Fusion for Class Incremental Learning in Pill Image Classification
Oct 05, 2022
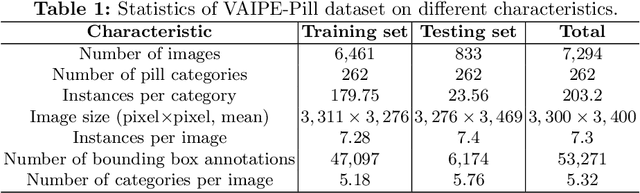

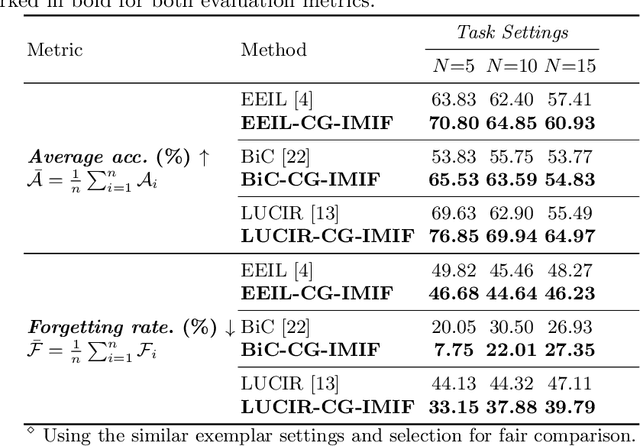
Classifying pill categories from real-world images is crucial for various smart healthcare applications. Although existing approaches in image classification might achieve a good performance on fixed pill categories, they fail to handle novel instances of pill categories that are frequently presented to the learning algorithm. To this end, a trivial solution is to train the model with novel classes. However, this may result in a phenomenon known as catastrophic forgetting, in which the system forgets what it learned in previous classes. In this paper, we address this challenge by introducing the class incremental learning (CIL) ability to traditional pill image classification systems. Specifically, we propose a novel incremental multi-stream intermediate fusion framework enabling incorporation of an additional guidance information stream that best matches the domain of the problem into various state-of-the-art CIL methods. From this framework, we consider color-specific information of pill images as a guidance stream and devise an approach, namely "Color Guidance with Multi-stream intermediate fusion"(CG-IMIF) for solving CIL pill image classification task. We conduct comprehensive experiments on real-world incremental pill image classification dataset, namely VAIPE-PCIL, and find that the CG-IMIF consistently outperforms several state-of-the-art methods by a large margin in different task settings. Our code, data, and trained model are available at https://github.com/vinuni-vishc/CG-IMIF.
A Novel Approach for Pill-Prescription Matching with GNN Assistance and Contrastive Learning
Sep 02, 2022

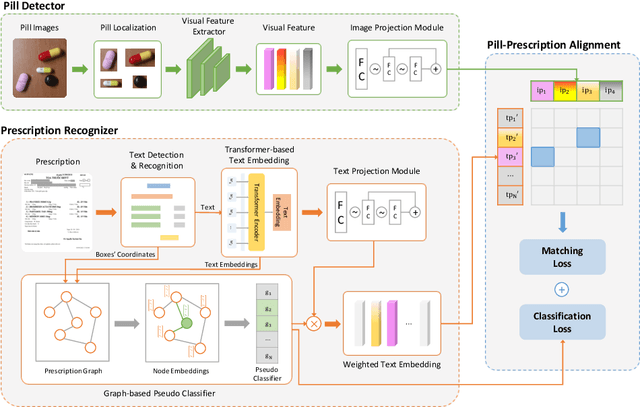
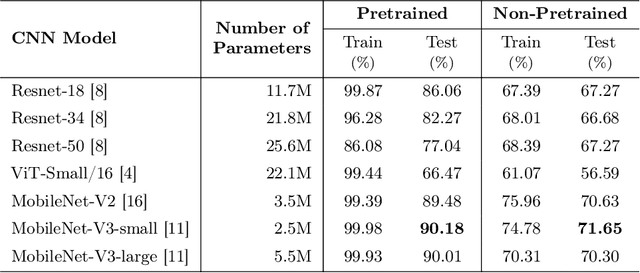
Medication mistaking is one of the risks that can result in unpredictable consequences for patients. To mitigate this risk, we develop an automatic system that correctly identifies pill-prescription from mobile images. Specifically, we define a so-called pill-prescription matching task, which attempts to match the images of the pills taken with the pills' names in the prescription. We then propose PIMA, a novel approach using Graph Neural Network (GNN) and contrastive learning to address the targeted problem. In particular, GNN is used to learn the spatial correlation between the text boxes in the prescription and thereby highlight the text boxes carrying the pill names. In addition, contrastive learning is employed to facilitate the modeling of cross-modal similarity between textual representations of pill names and visual representations of pill images. We conducted extensive experiments and demonstrated that PIMA outperforms baseline models on a real-world dataset of pill and prescription images that we constructed. Specifically, PIMA improves the accuracy from 19.09% to 46.95% compared to other baselines. We believe our work can open up new opportunities to build new clinical applications and improve medication safety and patient care.
Image-based Contextual Pill Recognition with Medical Knowledge Graph Assistance
Aug 09, 2022

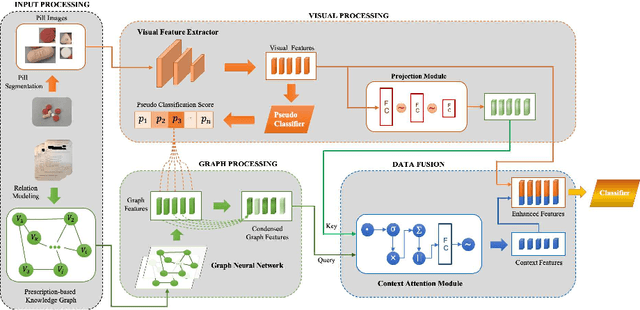
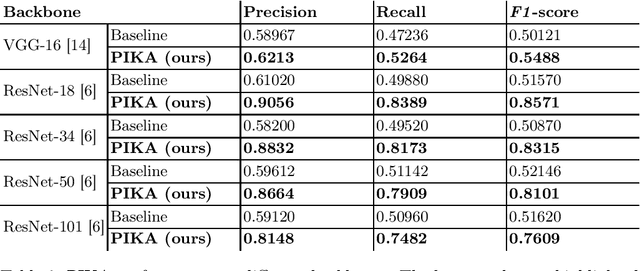
Identifying pills given their captured images under various conditions and backgrounds has been becoming more and more essential. Several efforts have been devoted to utilizing the deep learning-based approach to tackle the pill recognition problem in the literature. However, due to the high similarity between pills' appearance, misrecognition often occurs, leaving pill recognition a challenge. To this end, in this paper, we introduce a novel approach named PIKA that leverages external knowledge to enhance pill recognition accuracy. Specifically, we address a practical scenario (which we call contextual pill recognition), aiming to identify pills in a picture of a patient's pill intake. Firstly, we propose a novel method for modeling the implicit association between pills in the presence of an external data source, in this case, prescriptions. Secondly, we present a walk-based graph embedding model that transforms from the graph space to vector space and extracts condensed relational features of the pills. Thirdly, a final framework is provided that leverages both image-based visual and graph-based relational features to accomplish the pill identification task. Within this framework, the visual representation of each pill is mapped to the graph embedding space, which is then used to execute attention over the graph representation, resulting in a semantically-rich context vector that aids in the final classification. To our knowledge, this is the first study to use external prescription data to establish associations between medicines and to classify them using this aiding information. The architecture of PIKA is lightweight and has the flexibility to incorporate into any recognition backbones. The experimental results show that by leveraging the external knowledge graph, PIKA can improve the recognition accuracy from 4.8% to 34.1% in terms of F1-score, compared to baselines.
SAFL: A Self-Attention Scene Text Recognizer with Focal Loss
Jan 01, 2022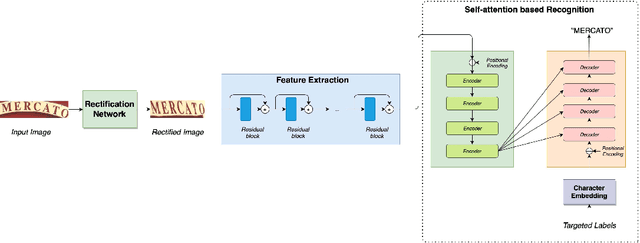
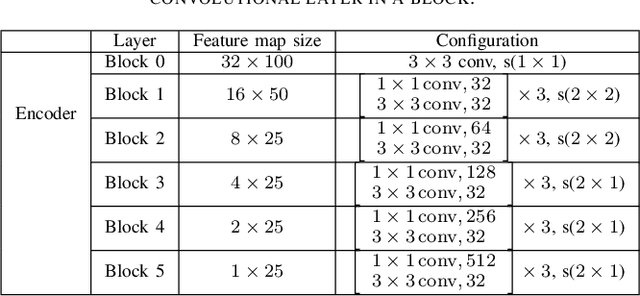

In the last decades, scene text recognition has gained worldwide attention from both the academic community and actual users due to its importance in a wide range of applications. Despite achievements in optical character recognition, scene text recognition remains challenging due to inherent problems such as distortions or irregular layout. Most of the existing approaches mainly leverage recurrence or convolution-based neural networks. However, while recurrent neural networks (RNNs) usually suffer from slow training speed due to sequential computation and encounter problems as vanishing gradient or bottleneck, CNN endures a trade-off between complexity and performance. In this paper, we introduce SAFL, a self-attention-based neural network model with the focal loss for scene text recognition, to overcome the limitation of the existing approaches. The use of focal loss instead of negative log-likelihood helps the model focus more on low-frequency samples training. Moreover, to deal with the distortions and irregular texts, we exploit Spatial TransformerNetwork (STN) to rectify text before passing to the recognition network. We perform experiments to compare the performance of the proposed model with seven benchmarks. The numerical results show that our model achieves the best performance.
* Accepted to ICMLA 2020