 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedCert: Federated Accuracy Certification
Oct 04, 2024



Federated Learning (FL) has emerged as a powerful paradigm for training machine learning models in a decentralized manner, preserving data privacy by keeping local data on clients. However, evaluating the robustness of these models against data perturbations on clients remains a significant challenge. Previous studies have assessed the effectiveness of models in centralized training based on certified accuracy, which guarantees that a certain percentage of the model's predictions will remain correct even if the input data is perturbed. However, the challenge of extending these evaluations to FL remains unresolved due to the unknown client's local data. To tackle this challenge, this study proposed a method named FedCert to take the first step toward evaluating the robustness of FL systems. The proposed method is designed to approximate the certified accuracy of a global model based on the certified accuracy and class distribution of each client. Additionally, considering the Non-Independent and Identically Distributed (Non-IID) nature of data in real-world scenarios, we introduce the client grouping algorithm to ensure reliable certified accuracy during the aggregation step of the approximation algorithm. Through theoretical analysis, we demonstrate the effectiveness of FedCert in assessing the robustness and reliability of FL systems. Moreover, experimental results on the CIFAR-10 and CIFAR-100 datasets under various scenarios show that FedCert consistently reduces the estimation error compared to baseline methods. This study offers a solution for evaluating the robustness of FL systems and lays the groundwork for future research to enhance the dependability of decentralized learning. The source code is available at https://github.com/thanhhff/FedCert/.
KAKURENBO: Adaptively Hiding Samples in Deep Neural Network Training
Oct 16, 2023



This paper proposes a method for hiding the least-important samples during the training of deep neural networks to increase efficiency, i.e., to reduce the cost of training. Using information about the loss and prediction confidence during training, we adaptively find samples to exclude in a given epoch based on their contribution to the overall learning process, without significantly degrading accuracy. We explore the converge properties when accounting for the reduction in the number of SGD updates. Empirical results on various large-scale datasets and models used directly in image classification and segmentation show that while the with-replacement importance sampling algorithm performs poorly on large datasets, our method can reduce total training time by up to 22% impacting accuracy only by 0.4% compared to the baseline. Code available at https://github.com/TruongThaoNguyen/kakurenbo
FedGrad: Mitigating Backdoor Attacks in Federated Learning Through Local Ultimate Gradients Inspection
Apr 29, 2023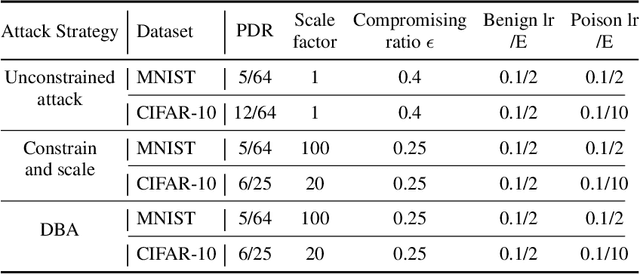
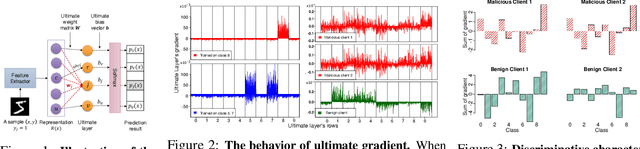
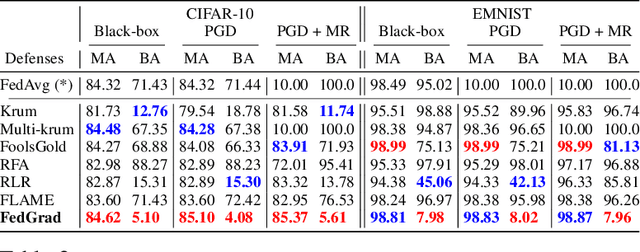
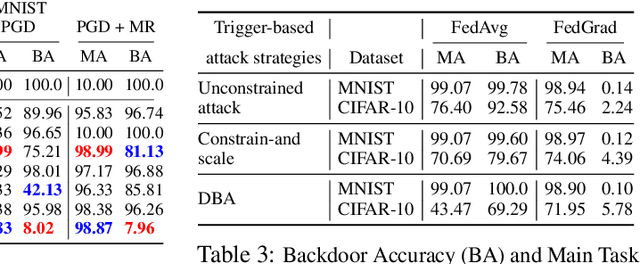
Federated learning (FL) enables multiple clients to train a model without compromising sensitive data. The decentralized nature of FL makes it susceptible to adversarial attacks, especially backdoor insertion during training. Recently, the edge-case backdoor attack employing the tail of the data distribution has been proposed as a powerful one, raising questions about the shortfall in current defenses' robustness guarantees. Specifically, most existing defenses cannot eliminate edge-case backdoor attacks or suffer from a trade-off between backdoor-defending effectiveness and overall performance on the primary task. To tackle this challenge, we propose FedGrad, a novel backdoor-resistant defense for FL that is resistant to cutting-edge backdoor attacks, including the edge-case attack, and performs effectively under heterogeneous client data and a large number of compromised clients. FedGrad is designed as a two-layer filtering mechanism that thoroughly analyzes the ultimate layer's gradient to identify suspicious local updates and remove them from the aggregation process. We evaluate FedGrad under different attack scenarios and show that it significantly outperforms state-of-the-art defense mechanisms. Notably, FedGrad can almost 100% correctly detect the malicious participants, thus providing a significant reduction in the backdoor effect (e.g., backdoor accuracy is less than 8%) while not reducing the main accuracy on the primary task.
CADIS: Handling Cluster-skewed Non-IID Data in Federated Learning with Clustered Aggregation and Knowledge DIStilled Regularization
Feb 21, 2023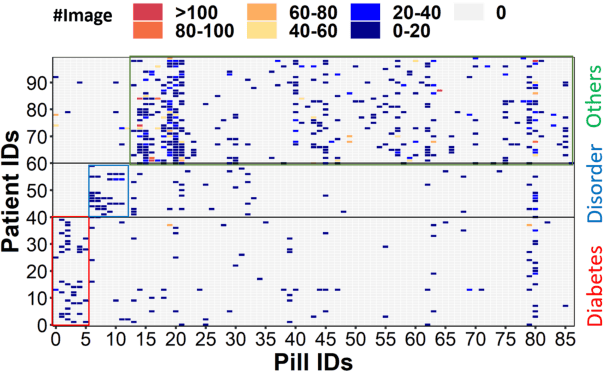

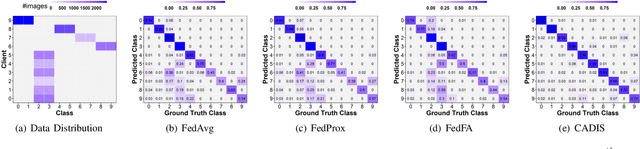
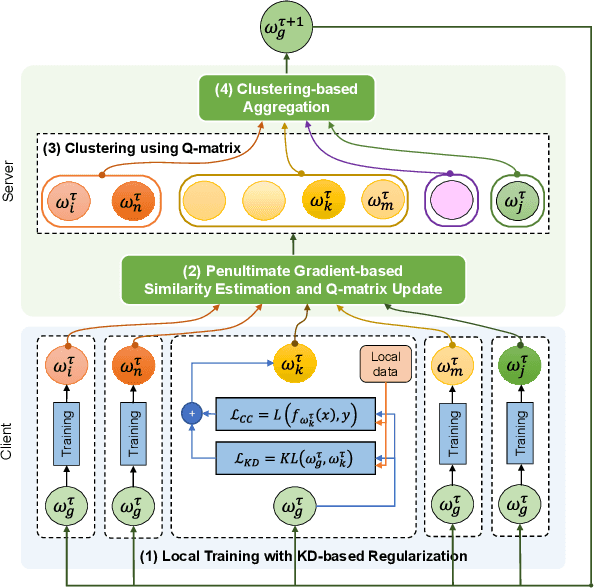
Federated learning enables edge devices to train a global model collaboratively without exposing their data. Despite achieving outstanding advantages in computing efficiency and privacy protection, federated learning faces a significant challenge when dealing with non-IID data, i.e., data generated by clients that are typically not independent and identically distributed. In this paper, we tackle a new type of Non-IID data, called cluster-skewed non-IID, discovered in actual data sets. The cluster-skewed non-IID is a phenomenon in which clients can be grouped into clusters with similar data distributions. By performing an in-depth analysis of the behavior of a classification model's penultimate layer, we introduce a metric that quantifies the similarity between two clients' data distributions without violating their privacy. We then propose an aggregation scheme that guarantees equality between clusters. In addition, we offer a novel local training regularization based on the knowledge-distillation technique that reduces the overfitting problem at clients and dramatically boosts the training scheme's performance. We theoretically prove the superiority of the proposed aggregation over the benchmark FedAvg. Extensive experimental results on both standard public datasets and our in-house real-world dataset demonstrate that the proposed approach improves accuracy by up to 16% compared to the FedAvg algorithm.
FedDCT: Federated Learning of Large Convolutional Neural Networks on Resource Constrained Devices using Divide and Co-Training
Nov 20, 2022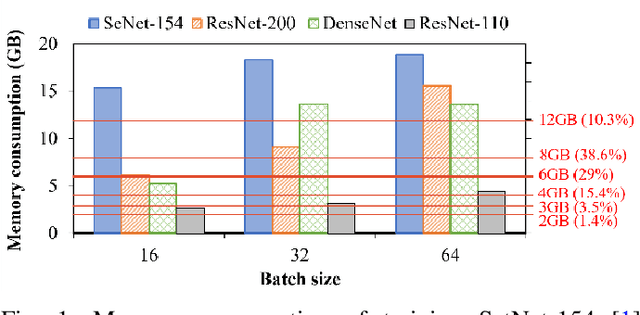

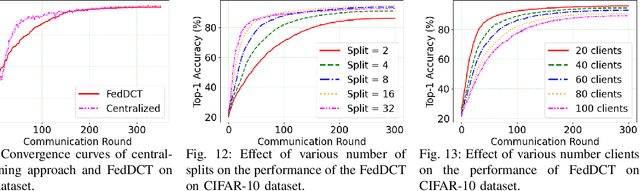

We introduce FedDCT, a novel distributed learning paradigm that enables the usage of large, high-performance CNNs on resource-limited edge devices. As opposed to traditional FL approaches, which require each client to train the full-size neural network independently during each training round, the proposed FedDCT allows a cluster of several clients to collaboratively train a large deep learning model by dividing it into an ensemble of several small sub-models and train them on multiple devices in parallel while maintaining privacy. In this co-training process, clients from the same cluster can also learn from each other, further improving their ensemble performance. In the aggregation stage, the server takes a weighted average of all the ensemble models trained by all the clusters. FedDCT reduces the memory requirements and allows low-end devices to participate in FL. We empirically conduct extensive experiments on standardized datasets, including CIFAR-10, CIFAR-100, and two real-world medical datasets HAM10000 and VAIPE. Experimental results show that FedDCT outperforms a set of current SOTA FL methods with interesting convergence behaviors. Furthermore, compared to other existing approaches, FedDCT achieves higher accuracy and substantially reduces the number of communication rounds (with $4-8$ times fewer memory requirements) to achieve the desired accuracy on the testing dataset without incurring any extra training cost on the server side.
FedDRL: Deep Reinforcement Learning-based Adaptive Aggregation for Non-IID Data in Federated Learning
Aug 04, 2022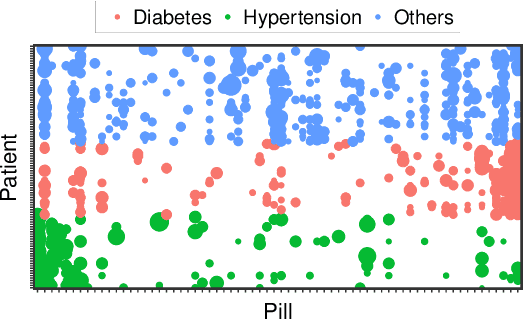

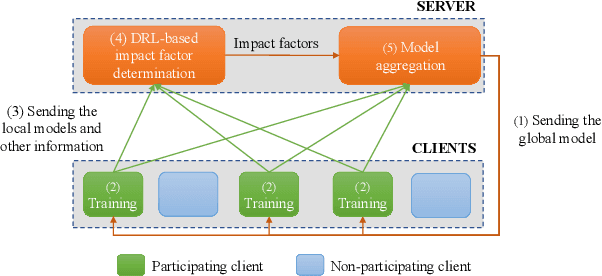
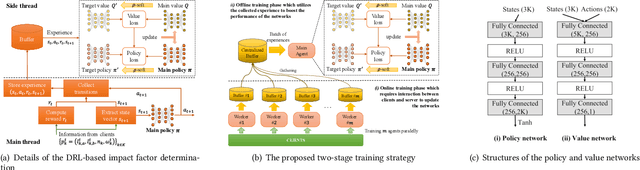
The uneven distribution of local data across different edge devices (clients) results in slow model training and accuracy reduction in federated learning. Naive federated learning (FL) strategy and most alternative solutions attempted to achieve more fairness by weighted aggregating deep learning models across clients. This work introduces a novel non-IID type encountered in real-world datasets, namely cluster-skew, in which groups of clients have local data with similar distributions, causing the global model to converge to an over-fitted solution. To deal with non-IID data, particularly the cluster-skewed data, we propose FedDRL, a novel FL model that employs deep reinforcement learning to adaptively determine each client's impact factor (which will be used as the weights in the aggregation process). Extensive experiments on a suite of federated datasets confirm that the proposed FedDRL improves favorably against FedAvg and FedProx methods, e.g., up to 4.05% and 2.17% on average for the CIFAR-100 dataset, respectively.
An Oracle for Guiding Large-Scale Model/Hybrid Parallel Training of Convolutional Neural Networks
Apr 19, 2021


Deep Neural Network (DNN) frameworks use distributed training to enable faster time to convergence and alleviate memory capacity limitations when training large models and/or using high dimension inputs. With the steady increase in datasets and model sizes, model/hybrid parallelism is deemed to have an important role in the future of distributed training of DNNs. We analyze the compute, communication, and memory requirements of Convolutional Neural Networks (CNNs) to understand the trade-offs between different parallelism approaches on performance and scalability. We leverage our model-driven analysis to be the basis for an oracle utility which can help in detecting the limitations and bottlenecks of different parallelism approaches at scale. We evaluate the oracle on six parallelization strategies, with four CNN models and multiple datasets (2D and 3D), on up to 1024 GPUs. The results demonstrate that the oracle has an average accuracy of about 86.74% when compared to empirical results, and as high as 97.57% for data parallelism.
Scaling Distributed Deep Learning Workloads beyond the Memory Capacity with KARMA
Aug 26, 2020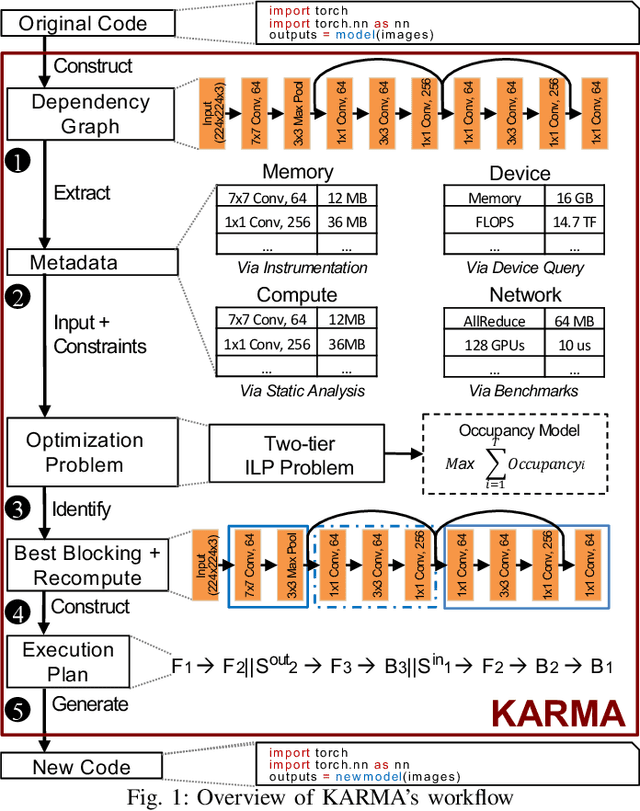
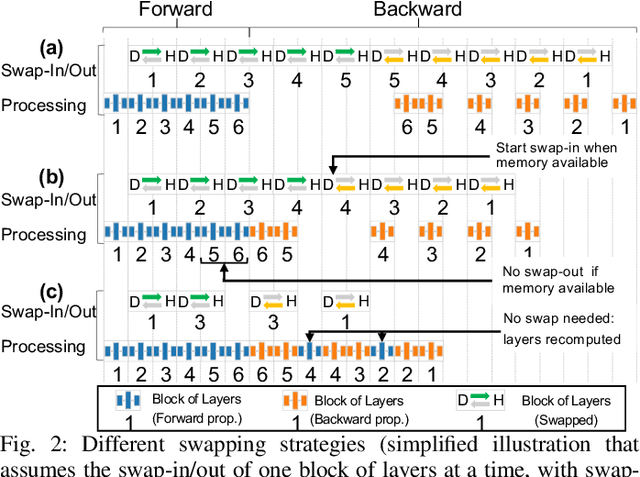
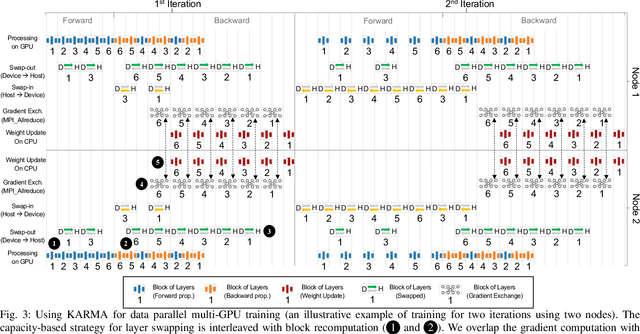

The dedicated memory of hardware accelerators can be insufficient to store all weights and/or intermediate states of large deep learning models. Although model parallelism is a viable approach to reduce the memory pressure issue, significant modification of the source code and considerations for algorithms are required. An alternative solution is to use out-of-core methods instead of, or in addition to, data parallelism. We propose a performance model based on the concurrency analysis of out-of-core training behavior, and derive a strategy that combines layer swapping and redundant recomputing. We achieve an average of 1.52x speedup in six different models over the state-of-the-art out-of-core methods. We also introduce the first method to solve the challenging problem of out-of-core multi-node training by carefully pipelining gradient exchanges and performing the parameter updates on the host. Our data parallel out-of-core solution can outperform complex hybrid model parallelism in training large models, e.g. Megatron-LM and Turning-NLG.