 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedDCT: Federated Learning of Large Convolutional Neural Networks on Resource Constrained Devices using Divide and Co-Training
Paper and Code
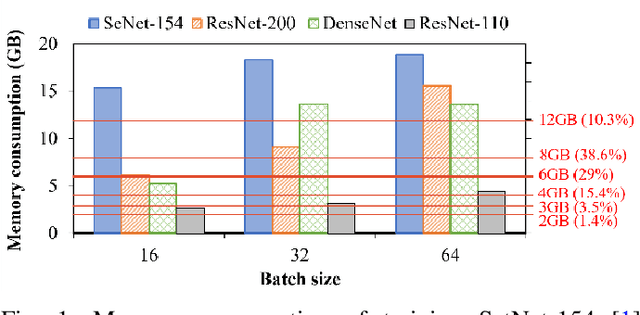

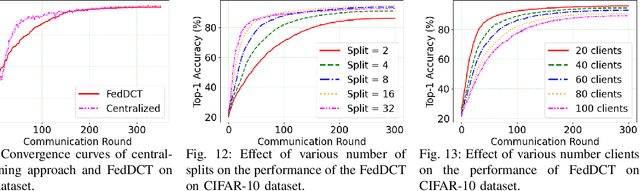

We introduce FedDCT, a novel distributed learning paradigm that enables the usage of large, high-performance CNNs on resource-limited edge devices. As opposed to traditional FL approaches, which require each client to train the full-size neural network independently during each training round, the proposed FedDCT allows a cluster of several clients to collaboratively train a large deep learning model by dividing it into an ensemble of several small sub-models and train them on multiple devices in parallel while maintaining privacy. In this co-training process, clients from the same cluster can also learn from each other, further improving their ensemble performance. In the aggregation stage, the server takes a weighted average of all the ensemble models trained by all the clusters. FedDCT reduces the memory requirements and allows low-end devices to participate in FL. We empirically conduct extensive experiments on standardized datasets, including CIFAR-10, CIFAR-100, and two real-world medical datasets HAM10000 and VAIPE. Experimental results show that FedDCT outperforms a set of current SOTA FL methods with interesting convergence behaviors. Furthermore, compared to other existing approaches, FedDCT achieves higher accuracy and substantially reduces the number of communication rounds (with $4-8$ times fewer memory requirements) to achieve the desired accuracy on the testing dataset without incurring any extra training cost on the server side.