 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Graph Learning via Distributional Invariance of Cause-Effect Relationship
Feb 03, 2026This paper introduces a new framework for recovering causal graphs from observational data, leveraging the observation that the distribution of an effect, conditioned on its causes, remains invariant to changes in the prior distribution of those causes. This insight enables a direct test for potential causal relationships by checking the variance of their corresponding effect-cause conditional distributions across multiple downsampled subsets of the data. These subsets are selected to reflect different prior cause distributions, while preserving the effect-cause conditional relationships. Using this invariance test and exploiting an (empirical) sparsity of most causal graphs, we develop an algorithm that efficiently uncovers causal relationships with quadratic complexity in the number of observational variables, reducing the processing time by up to 25x compared to state-of-the-art methods. Our empirical experiments on a varied benchmark of large-scale datasets show superior or equivalent performance compared to existing works, while achieving enhanced scalability.
Rethinking Cross-Modal Fine-Tuning: Optimizing the Interaction between Feature Alignment and Target Fitting
Jan 26, 2026Adapting pre-trained models to unseen feature modalities has become increasingly important due to the growing need for cross-disciplinary knowledge integration.~A key challenge here is how to align the representation of new modalities with the most relevant parts of the pre-trained model's representation space to enable accurate knowledge transfer.~This requires combining feature alignment with target fine-tuning, but uncalibrated combinations can exacerbate misalignment between the source and target feature-label structures and reduce target generalization.~Existing work however lacks a theoretical understanding of this critical interaction between feature alignment and target fitting.~To bridge this gap, we develop a principled framework that establishes a provable generalization bound on the target error, which explains the interaction between feature alignment and target fitting through a novel concept of feature-label distortion.~This bound offers actionable insights into how this interaction should be optimized for practical algorithm design. The resulting approach achieves significantly improved performance over state-of-the-art methods across a wide range of benchmark datasets.
PADM: A Physics-aware Diffusion Model for Attenuation Correction
Nov 10, 2025Attenuation artifacts remain a significant challenge in cardiac Myocardial Perfusion Imaging (MPI) using Single-Photon Emission Computed Tomography (SPECT), often compromising diagnostic accuracy and reducing clinical interpretability. While hybrid SPECT/CT systems mitigate these artifacts through CT-derived attenuation maps, their high cost, limited accessibility, and added radiation exposure hinder widespread clinical adoption. In this study, we propose a novel CT-free solution to attenuation correction in cardiac SPECT. Specifically, we introduce Physics-aware Attenuation Correction Diffusion Model (PADM), a diffusion-based generative method that incorporates explicit physics priors via a teacher--student distillation mechanism. This approach enables attenuation artifact correction using only Non-Attenuation-Corrected (NAC) input, while still benefiting from physics-informed supervision during training. To support this work, we also introduce CardiAC, a comprehensive dataset comprising 424 patient studies with paired NAC and Attenuation-Corrected (AC) reconstructions, alongside high-resolution CT-based attenuation maps. Extensive experiments demonstrate that PADM outperforms state-of-the-art generative models, delivering superior reconstruction fidelity across both quantitative metrics and visual assessment.
Learning Reconfigurable Representations for Multimodal Federated Learning with Missing Data
Oct 27, 2025



Multimodal federated learning in real-world settings often encounters incomplete and heterogeneous data across clients. This results in misaligned local feature representations that limit the effectiveness of model aggregation. Unlike prior work that assumes either differing modality sets without missing input features or a shared modality set with missing features across clients, we consider a more general and realistic setting where each client observes a different subset of modalities and might also have missing input features within each modality. To address the resulting misalignment in learned representations, we propose a new federated learning framework featuring locally adaptive representations based on learnable client-side embedding controls that encode each client's data-missing patterns. These embeddings serve as reconfiguration signals that align the globally aggregated representation with each client's local context, enabling more effective use of shared information. Furthermore, the embedding controls can be algorithmically aggregated across clients with similar data-missing patterns to enhance the robustness of reconfiguration signals in adapting the global representation. Empirical results on multiple federated multimodal benchmarks with diverse data-missing patterns across clients demonstrate the efficacy of the proposed method, achieving up to 36.45\% performance improvement under severe data incompleteness. The method is also supported by a theoretical analysis with an explicit performance bound that matches our empirical observations. Our source codes are provided at https://github.com/nmduonggg/PEPSY
Expressive and Scalable Quantum Fusion for Multimodal Learning
Oct 08, 2025The aim of this paper is to introduce a quantum fusion mechanism for multimodal learning and to establish its theoretical and empirical potential. The proposed method, called the Quantum Fusion Layer (QFL), replaces classical fusion schemes with a hybrid quantum-classical procedure that uses parameterized quantum circuits to learn entangled feature interactions without requiring exponential parameter growth. Supported by quantum signal processing principles, the quantum component efficiently represents high-order polynomial interactions across modalities with linear parameter scaling, and we provide a separation example between QFL and low-rank tensor-based methods that highlights potential quantum query advantages. In simulation, QFL consistently outperforms strong classical baselines on small but diverse multimodal tasks, with particularly marked improvements in high-modality regimes. These results suggest that QFL offers a fundamentally new and scalable approach to multimodal fusion that merits deeper exploration on larger systems.
Seeing the Trees for the Forest: Rethinking Weakly-Supervised Medical Visual Grounding
May 21, 2025Visual grounding (VG) is the capability to identify the specific regions in an image associated with a particular text description. In medical imaging, VG enhances interpretability by highlighting relevant pathological features corresponding to textual descriptions, improving model transparency and trustworthiness for wider adoption of deep learning models in clinical practice. Current models struggle to associate textual descriptions with disease regions due to inefficient attention mechanisms and a lack of fine-grained token representations. In this paper, we empirically demonstrate two key observations. First, current VLMs assign high norms to background tokens, diverting the model's attention from regions of disease. Second, the global tokens used for cross-modal learning are not representative of local disease tokens. This hampers identifying correlations between the text and disease tokens. To address this, we introduce simple, yet effective Disease-Aware Prompting (DAP) process, which uses the explainability map of a VLM to identify the appropriate image features. This simple strategy amplifies disease-relevant regions while suppressing background interference. Without any additional pixel-level annotations, DAP improves visual grounding accuracy by 20.74% compared to state-of-the-art methods across three major chest X-ray datasets.
Localizing Before Answering: A Hallucination Evaluation Benchmark for Grounded Medical Multimodal LLMs
May 05, 2025Medical Large Multi-modal Models (LMMs) have demonstrated remarkable capabilities in medical data interpretation. However, these models frequently generate hallucinations contradicting source evidence, particularly due to inadequate localization reasoning. This work reveals a critical limitation in current medical LMMs: instead of analyzing relevant pathological regions, they often rely on linguistic patterns or attend to irrelevant image areas when responding to disease-related queries. To address this, we introduce HEAL-MedVQA (Hallucination Evaluation via Localization MedVQA), a comprehensive benchmark designed to evaluate LMMs' localization abilities and hallucination robustness. HEAL-MedVQA features (i) two innovative evaluation protocols to assess visual and textual shortcut learning, and (ii) a dataset of 67K VQA pairs, with doctor-annotated anatomical segmentation masks for pathological regions. To improve visual reasoning, we propose the Localize-before-Answer (LobA) framework, which trains LMMs to localize target regions of interest and self-prompt to emphasize segmented pathological areas, generating grounded and reliable answers. Experimental results demonstrate that our approach significantly outperforms state-of-the-art biomedical LMMs on the challenging HEAL-MedVQA benchmark, advancing robustness in medical VQA.
Boosting Offline Optimizers with Surrogate Sensitivity
Mar 06, 2025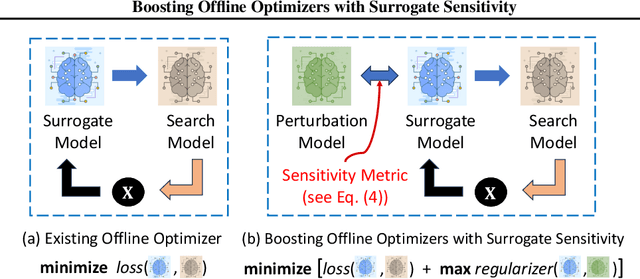


Offline optimization is an important task in numerous material engineering domains where online experimentation to collect data is too expensive and needs to be replaced by an in silico maximization of a surrogate of the black-box function. Although such a surrogate can be learned from offline data, its prediction might not be reliable outside the offline data regime, which happens when the surrogate has narrow prediction margin and is (therefore) sensitive to small perturbations of its parameterization. This raises the following questions: (1) how to regulate the sensitivity of a surrogate model; and (2) whether conditioning an offline optimizer with such less sensitive surrogate will lead to better optimization performance. To address these questions, we develop an optimizable sensitivity measurement for the surrogate model, which then inspires a sensitivity-informed regularizer that is applicable to a wide range of offline optimizers. This development is both orthogonal and synergistic to prior research on offline optimization, which is demonstrated in our extensive experiment benchmark.
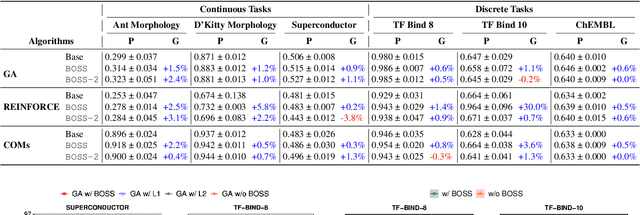
Incorporating Surrogate Gradient Norm to Improve Offline Optimization Techniques
Mar 06, 2025Offline optimization has recently emerged as an increasingly popular approach to mitigate the prohibitively expensive cost of online experimentation. The key idea is to learn a surrogate of the black-box function that underlines the target experiment using a static (offline) dataset of its previous input-output queries. Such an approach is, however, fraught with an out-of-distribution issue where the learned surrogate becomes inaccurate outside the offline data regimes. To mitigate this, existing offline optimizers have proposed numerous conditioning techniques to prevent the learned surrogate from being too erratic. Nonetheless, such conditioning strategies are often specific to particular surrogate or search models, which might not generalize to a different model choice. This motivates us to develop a model-agnostic approach instead, which incorporates a notion of model sharpness into the training loss of the surrogate as a regularizer. Our approach is supported by a new theoretical analysis demonstrating that reducing surrogate sharpness on the offline dataset provably reduces its generalized sharpness on unseen data. Our analysis extends existing theories from bounding generalized prediction loss (on unseen data) with loss sharpness to bounding the worst-case generalized surrogate sharpness with its empirical estimate on training data, providing a new perspective on sharpness regularization. Our extensive experimentation on a diverse range of optimization tasks also shows that reducing surrogate sharpness often leads to significant improvement, marking (up to) a noticeable 9.6% performance boost. Our code is publicly available at https://github.com/cuong-dm/IGNITE
NeurFlow: Interpreting Neural Networks through Neuron Groups and Functional Interactions
Feb 22, 2025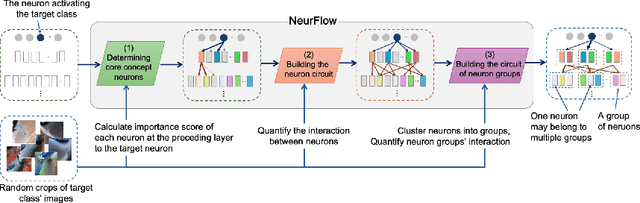

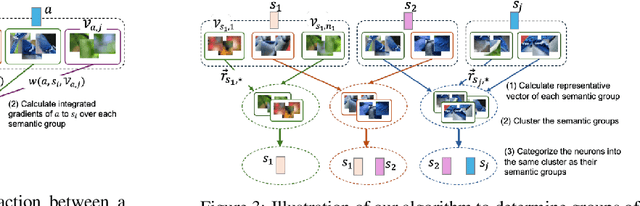
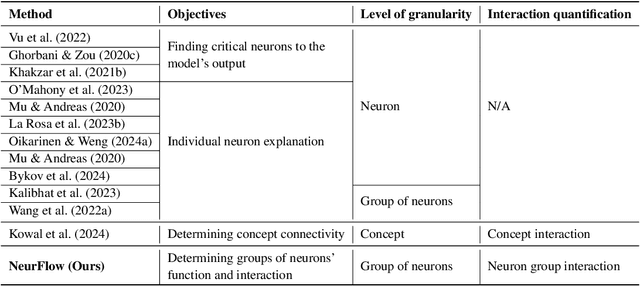
Understanding the inner workings of neural networks is essential for enhancing model performance and interpretability. Current research predominantly focuses on examining the connection between individual neurons and the model's final predictions. Which suffers from challenges in interpreting the internal workings of the model, particularly when neurons encode multiple unrelated features. In this paper, we propose a novel framework that transitions the focus from analyzing individual neurons to investigating groups of neurons, shifting the emphasis from neuron-output relationships to functional interaction between neurons. Our automated framework, NeurFlow, first identifies core neurons and clusters them into groups based on shared functional relationships, enabling a more coherent and interpretable view of the network's internal processes. This approach facilitates the construction of a hierarchical circuit representing neuron interactions across layers, thus improving interpretability while reducing computational costs. Our extensive empirical studies validate the fidelity of our proposed NeurFlow. Additionally, we showcase its utility in practical applications such as image debugging and automatic concept labeling, thereby highlighting its potential to advance the field of neural network explainability.