 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Classification and Segmentation in Osteosarcoma Assessment via Foundation and Discrete Diffusion Models
Jan 03, 2025
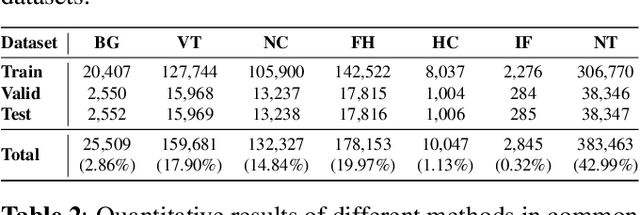
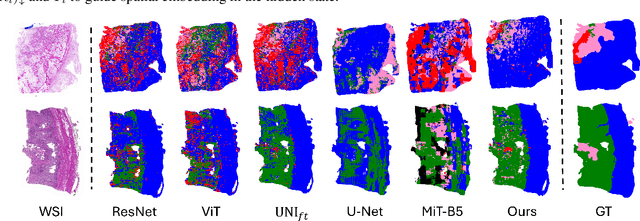
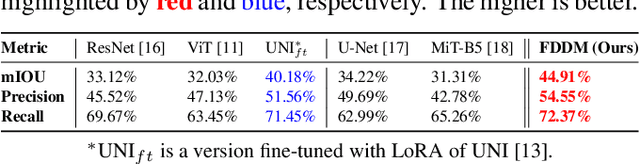
Osteosarcoma, the most common primary bone cancer, often requires accurate necrosis assessment from whole slide images (WSIs) for effective treatment planning and prognosis. However, manual assessments are subjective and prone to variability. In response, we introduce FDDM, a novel framework bridging the gap between patch classification and region-based segmentation. FDDM operates in two stages: patch-based classification, followed by region-based refinement, enabling cross-patch information intergation. Leveraging a newly curated dataset of osteosarcoma images, FDDM demonstrates superior segmentation performance, achieving up to a 10% improvement mIOU and a 32.12% enhancement in necrosis rate estimation over state-of-the-art methods. This framework sets a new benchmark in osteosarcoma assessment, highlighting the potential of foundation models and diffusion-based refinements in complex medical imaging tasks.
FedMAC: Tackling Partial-Modality Missing in Federated Learning with Cross-Modal Aggregation and Contrastive Regularization
Oct 04, 2024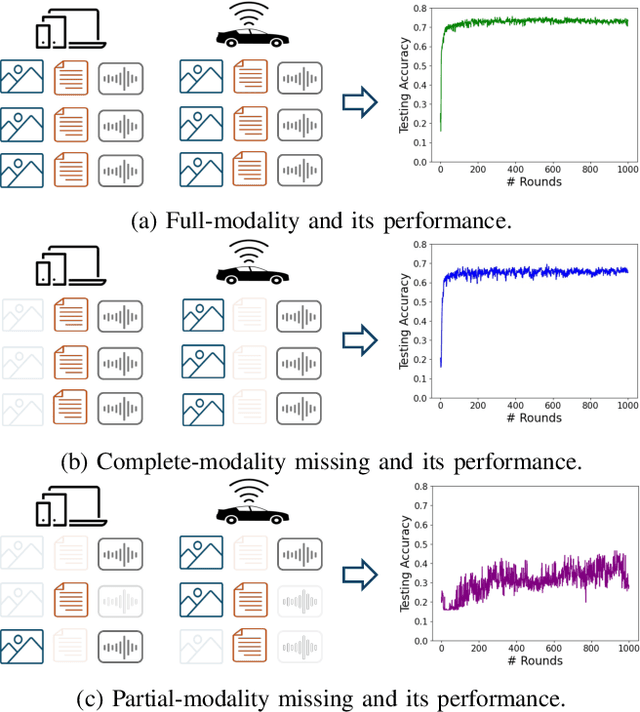
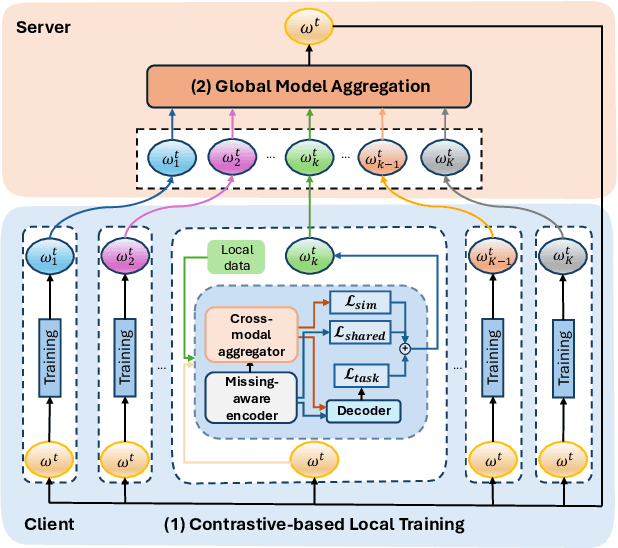
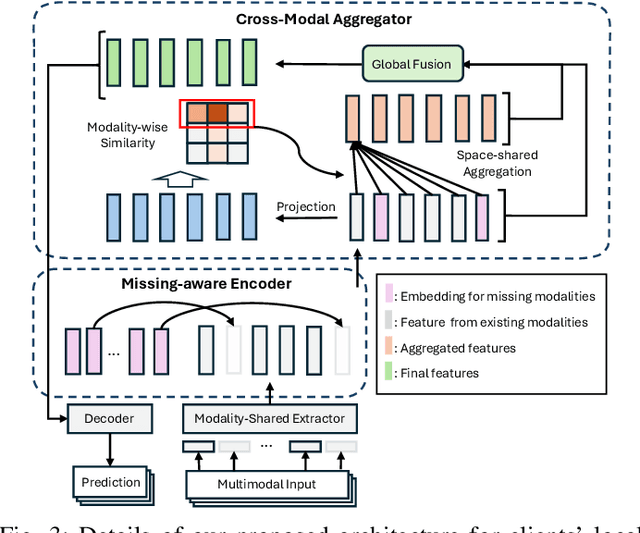
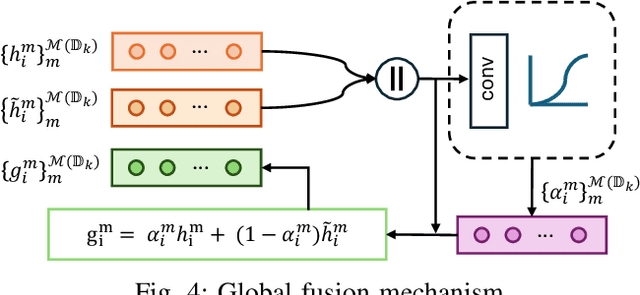
Federated Learning (FL) is a method for training machine learning models using distributed data sources. It ensures privacy by allowing clients to collaboratively learn a shared global model while storing their data locally. However, a significant challenge arises when dealing with missing modalities in clients' datasets, where certain features or modalities are unavailable or incomplete, leading to heterogeneous data distribution. While previous studies have addressed the issue of complete-modality missing, they fail to tackle partial-modality missing on account of severe heterogeneity among clients at an instance level, where the pattern of missing data can vary significantly from one sample to another. To tackle this challenge, this study proposes a novel framework named FedMAC, designed to address multi-modality missing under conditions of partial-modality missing in FL. Additionally, to avoid trivial aggregation of multi-modal features, we introduce contrastive-based regularization to impose additional constraints on the latent representation space. The experimental results demonstrate the effectiveness of FedMAC across various client configurations with statistical heterogeneity, outperforming baseline methods by up to 26% in severe missing scenarios, highlighting its potential as a solution for the challenge of partially missing modalities in federated systems.
FedCert: Federated Accuracy Certification
Oct 04, 2024



Federated Learning (FL) has emerged as a powerful paradigm for training machine learning models in a decentralized manner, preserving data privacy by keeping local data on clients. However, evaluating the robustness of these models against data perturbations on clients remains a significant challenge. Previous studies have assessed the effectiveness of models in centralized training based on certified accuracy, which guarantees that a certain percentage of the model's predictions will remain correct even if the input data is perturbed. However, the challenge of extending these evaluations to FL remains unresolved due to the unknown client's local data. To tackle this challenge, this study proposed a method named FedCert to take the first step toward evaluating the robustness of FL systems. The proposed method is designed to approximate the certified accuracy of a global model based on the certified accuracy and class distribution of each client. Additionally, considering the Non-Independent and Identically Distributed (Non-IID) nature of data in real-world scenarios, we introduce the client grouping algorithm to ensure reliable certified accuracy during the aggregation step of the approximation algorithm. Through theoretical analysis, we demonstrate the effectiveness of FedCert in assessing the robustness and reliability of FL systems. Moreover, experimental results on the CIFAR-10 and CIFAR-100 datasets under various scenarios show that FedCert consistently reduces the estimation error compared to baseline methods. This study offers a solution for evaluating the robustness of FL systems and lays the groundwork for future research to enhance the dependability of decentralized learning. The source code is available at https://github.com/thanhhff/FedCert/.