 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuiding Federated Graph Recommendation with LLM-encoded knowledge
Jun 13, 2026Graph-based recommender systems are highly effective at extracting collaborative signals from user--item interactions, and federated learning (FL) allows these models to be trained while preserving user privacy. However, aggregating graph representations across distributed, non-IID clients remains a challenge; structural embeddings learned locally often misalign, and naive averaging fails to capture meaningful cross-client relationships. Most existing federated graph methods rely exclusively on structural aggregation, neglecting the rich, global semantic context available in large language models (LLMs). In this paper, we propose a novel framework that uses LLM-encoded knowledge to guide federated graph recommendation. Specifically, clients learn structural representations from local graphs while simultaneously summarizing their typical interaction patterns into compact semantic vectors via a frozen LLM. The central server then uses these LLM-encoded semantic signals to discover related preference patterns across clients, guiding the selective aggregation of their structural representations. This enables semantically informed cross-client collaboration without exposing raw data. Extensive experiments on standard benchmarks show that guiding structural alignment with LLM-encoded knowledge consistently improves recommendation accuracy over existing federated graph baselines.
FINER-SQL: Boosting Small Language Models for Text-to-SQL
May 05, 2026Large language models have driven major advances in Text-to-SQL generation. However, they suffer from high computational cost, long latency, and data privacy concerns, which make them impractical for many real-world applications. A natural alternative is to use small language models (SLMs), which enable efficient and private on-premise deployment. Yet, SLMs often struggle with weak reasoning and poor instruction following. Conventional reinforcement learning methods based on sparse binary rewards (0/1) provide little learning signal when the generated SQLs are incorrect, leading to unstable or collapsed training. To overcome these issues, we propose FINER-SQL, a scalable and reusable reinforcement learning framework that enhances SLMs through fine-grained execution feedback. Built on group relative policy optimization, FINER-SQL replaces sparse supervision with dense and interpretable rewards that offer continuous feedback even for incorrect SQLs. It introduces two key reward functions: a memory reward, which aligns reasoning with verified traces for semantic stability, and an atomic reward, which measures operation-level overlap to grant partial credit for structurally correct but incomplete SQLs. This approach transforms discrete correctness into continuous learning, enabling stable, critic-free optimization. Experiments on the BIRD and Spider benchmarks show that FINER-SQL achieves up to 67.73\% and 85\% execution accuracy with a 3B model -- matching much larger LLMs while reducing inference latency to 5.57~s/sample. These results highlight a cost-efficient and privacy-preserving path toward high-performance Text-to-SQL generation. Our code is available at https://github.com/thanhdath/finer-sql.
Empowering Contrastive Federated Sequential Recommendation with LLMs
Feb 10, 2026Federated sequential recommendation (FedSeqRec) aims to perform next-item prediction while keeping user data decentralised, yet model quality is frequently constrained by fragmented, noisy, and homogeneous interaction logs stored on individual devices. Many existing approaches attempt to compensate through manual data augmentation or additional server-side constraints, but these strategies either introduce limited semantic diversity or increase system overhead. To overcome these challenges, we propose \textbf{LUMOS}, a parameter-isolated FedSeqRec architecture that integrates large language models (LLMs) as \emph{local semantic generators}. Instead of sharing gradients or auxiliary parameters, LUMOS privately invokes an on-device LLM to construct three complementary sequence variants from each user history: (i) \emph{future-oriented} trajectories that infer plausible behavioural continuations, (ii) \emph{semantically equivalent rephrasings} that retain user intent while diversifying interaction patterns, and (iii) \emph{preference-inconsistent counterfactuals} that serve as informative negatives. These synthesized sequences are jointly encoded within the federated backbone through a tri-view contrastive optimisation scheme, enabling richer representation learning without exposing sensitive information. Experimental results across three public benchmarks show that LUMOS achieves consistent gains over competitive centralised and federated baselines on HR@20 and NDCG@20. In addition, the use of semantically grounded positive signals and counterfactual negatives improves robustness under noisy and adversarial environments, even without dedicated server-side protection modules. Overall, this work demonstrates the potential of LLM-driven semantic generation as a new paradigm for advancing privacy-preserving federated recommendation.
Federated Prompt-Tuning with Heterogeneous and Incomplete Multimodal Client Data
Feb 06, 2026This paper introduces a generalized federated prompt-tuning framework for practical scenarios where local datasets are multi-modal and exhibit different distributional patterns of missing features at the input level. The proposed framework bridges the gap between federated learning and multi-modal prompt-tuning which have traditionally focused on either uni-modal or centralized data. A key challenge in this setting arises from the lack of semantic alignment between prompt instructions that encode similar distributional patterns of missing data across different clients. To address this, our framework introduces specialized client-tuning and server-aggregation designs that simultaneously optimize, align, and aggregate prompt-tuning instructions across clients and data modalities. This allows prompt instructions to complement one another and be combined effectively. Extensive evaluations on diverse multimodal benchmark datasets demonstrate that our work consistently outperforms state-of-the-art (SOTA) baselines.
A Multi-agent Text2SQL Framework using Small Language Models and Execution Feedback
Dec 21, 2025Text2SQL, the task of generating SQL queries from natural language text, is a critical challenge in data engineering. Recently, Large Language Models (LLMs) have demonstrated superior performance for this task due to their advanced comprehension and generation capabilities. However, privacy and cost considerations prevent companies from using Text2SQL solutions based on external LLMs offered as a service. Rather, small LLMs (SLMs) that are openly available and can hosted in-house are adopted. These SLMs, in turn, lack the generalization capabilities of larger LLMs, which impairs their effectiveness for complex tasks such as Text2SQL. To address these limitations, we propose MATS, a novel Text2SQL framework designed specifically for SLMs. MATS uses a multi-agent mechanism that assigns specialized roles to auxiliary agents, reducing individual workloads and fostering interaction. A training scheme based on reinforcement learning aligns these agents using feedback obtained during execution, thereby maintaining competitive performance despite a limited LLM size. Evaluation results using on benchmark datasets show that MATS, deployed on a single- GPU server, yields accuracy that are on-par with large-scale LLMs when using significantly fewer parameters. Our source code and data are available at https://github.com/thanhdath/mats-sql.
Scaling Text2SQL via LLM-efficient Schema Filtering with Functional Dependency Graph Rerankers
Dec 18, 2025Most modern Text2SQL systems prompt large language models (LLMs) with entire schemas -- mostly column information -- alongside the user's question. While effective on small databases, this approach fails on real-world schemas that exceed LLM context limits, even for commercial models. The recent Spider 2.0 benchmark exemplifies this with hundreds of tables and tens of thousands of columns, where existing systems often break. Current mitigations either rely on costly multi-step prompting pipelines or filter columns by ranking them against user's question independently, ignoring inter-column structure. To scale existing systems, we introduce \toolname, an open-source, LLM-efficient schema filtering framework that compacts Text2SQL prompts by (i) ranking columns with a query-aware LLM encoder enriched with values and metadata, (ii) reranking inter-connected columns via a lightweight graph transformer over functional dependencies, and (iii) selecting a connectivity-preserving sub-schema with a Steiner-tree heuristic. Experiments on real datasets show that \toolname achieves near-perfect recall and higher precision than CodeS, SchemaExP, Qwen rerankers, and embedding retrievers, while maintaining sub-second median latency and scaling to schemas with 23,000+ columns. Our source code is available at https://github.com/thanhdath/grast-sql.
Learning Reconfigurable Representations for Multimodal Federated Learning with Missing Data
Oct 27, 2025



Multimodal federated learning in real-world settings often encounters incomplete and heterogeneous data across clients. This results in misaligned local feature representations that limit the effectiveness of model aggregation. Unlike prior work that assumes either differing modality sets without missing input features or a shared modality set with missing features across clients, we consider a more general and realistic setting where each client observes a different subset of modalities and might also have missing input features within each modality. To address the resulting misalignment in learned representations, we propose a new federated learning framework featuring locally adaptive representations based on learnable client-side embedding controls that encode each client's data-missing patterns. These embeddings serve as reconfiguration signals that align the globally aggregated representation with each client's local context, enabling more effective use of shared information. Furthermore, the embedding controls can be algorithmically aggregated across clients with similar data-missing patterns to enhance the robustness of reconfiguration signals in adapting the global representation. Empirical results on multiple federated multimodal benchmarks with diverse data-missing patterns across clients demonstrate the efficacy of the proposed method, achieving up to 36.45\% performance improvement under severe data incompleteness. The method is also supported by a theoretical analysis with an explicit performance bound that matches our empirical observations. Our source codes are provided at https://github.com/nmduonggg/PEPSY
Hypergraph Diffusion for High-Order Recommender Systems
Jan 28, 2025



Recommender systems rely on Collaborative Filtering (CF) to predict user preferences by leveraging patterns in historical user-item interactions. While traditional CF methods primarily focus on learning compact vector embeddings for users and items, graph neural network (GNN)-based approaches have emerged as a powerful alternative, utilizing the structure of user-item interaction graphs to enhance recommendation accuracy. However, existing GNN-based models, such as LightGCN and UltraGCN, often struggle with two major limitations: an inability to fully account for heterophilic interactions, where users engage with diverse item categories, and the over-smoothing problem in multi-layer GNNs, which hinders their ability to model complex, high-order relationships. To address these gaps, we introduce WaveHDNN, an innovative wavelet-enhanced hypergraph diffusion framework. WaveHDNN integrates a Heterophily-aware Collaborative Encoder, designed to capture user-item interactions across diverse categories, with a Multi-scale Group-wise Structure Encoder, which leverages wavelet transforms to effectively model localized graph structures. Additionally, cross-view contrastive learning is employed to maintain robust and consistent representations. Experiments on benchmark datasets validate the efficacy of WaveHDNN, demonstrating its superior ability to capture both heterophilic and localized structural information, leading to improved recommendation performance.
FedMAC: Tackling Partial-Modality Missing in Federated Learning with Cross-Modal Aggregation and Contrastive Regularization
Oct 04, 2024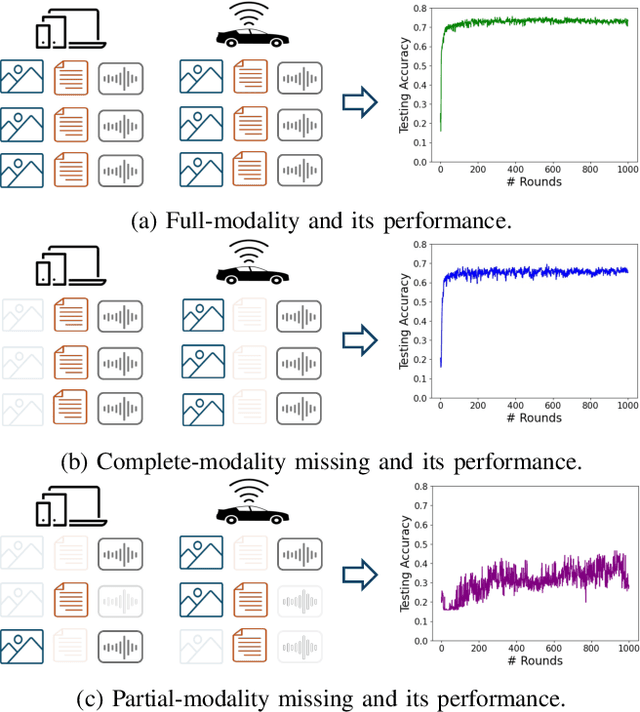
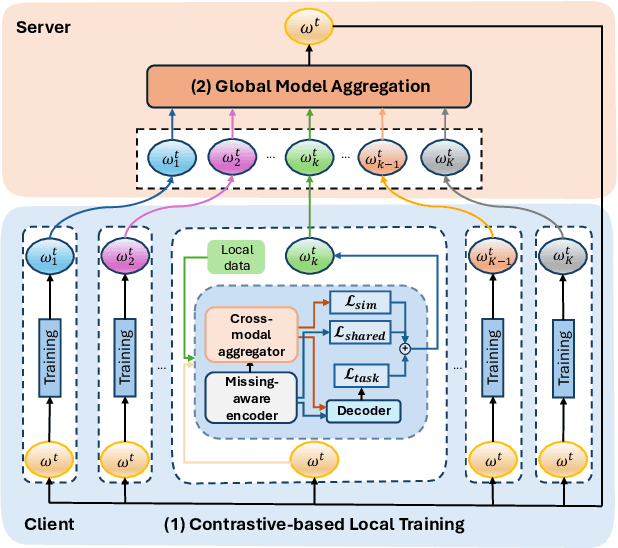
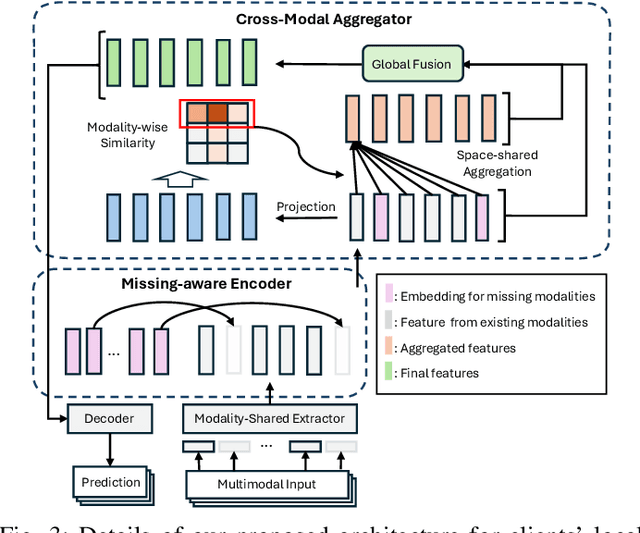
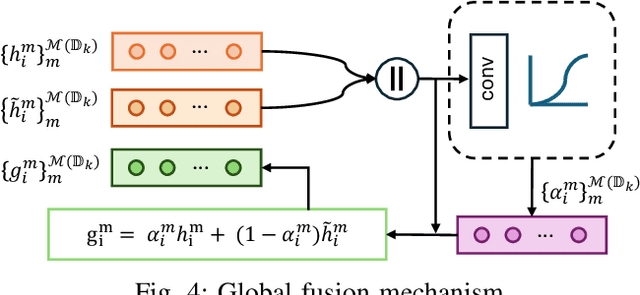
Federated Learning (FL) is a method for training machine learning models using distributed data sources. It ensures privacy by allowing clients to collaboratively learn a shared global model while storing their data locally. However, a significant challenge arises when dealing with missing modalities in clients' datasets, where certain features or modalities are unavailable or incomplete, leading to heterogeneous data distribution. While previous studies have addressed the issue of complete-modality missing, they fail to tackle partial-modality missing on account of severe heterogeneity among clients at an instance level, where the pattern of missing data can vary significantly from one sample to another. To tackle this challenge, this study proposes a novel framework named FedMAC, designed to address multi-modality missing under conditions of partial-modality missing in FL. Additionally, to avoid trivial aggregation of multi-modal features, we introduce contrastive-based regularization to impose additional constraints on the latent representation space. The experimental results demonstrate the effectiveness of FedMAC across various client configurations with statistical heterogeneity, outperforming baseline methods by up to 26% in severe missing scenarios, highlighting its potential as a solution for the challenge of partially missing modalities in federated systems.
Heterogeneous Hypergraph Embedding for Recommendation Systems
Jul 04, 2024



Recent advancements in recommender systems have focused on integrating knowledge graphs (KGs) to leverage their auxiliary information. The core idea of KG-enhanced recommenders is to incorporate rich semantic information for more accurate recommendations. However, two main challenges persist: i) Neglecting complex higher-order interactions in the KG-based user-item network, potentially leading to sub-optimal recommendations, and ii) Dealing with the heterogeneous modalities of input sources, such as user-item bipartite graphs and KGs, which may introduce noise and inaccuracies. To address these issues, we present a novel Knowledge-enhanced Heterogeneous Hypergraph Recommender System (KHGRec). KHGRec captures group-wise characteristics of both the interaction network and the KG, modeling complex connections in the KG. Using a collaborative knowledge heterogeneous hypergraph (CKHG), it employs two hypergraph encoders to model group-wise interdependencies and ensure explainability. Additionally, it fuses signals from the input graphs with cross-view self-supervised learning and attention mechanisms. Extensive experiments on four real-world datasets show our model's superiority over various state-of-the-art baselines, with an average 5.18\% relative improvement. Additional tests on noise resilience, missing data, and cold-start problems demonstrate the robustness of our KHGRec framework. Our model and evaluation datasets are publicly available at \url{https://github.com/viethungvu1998/KHGRec}.