 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey of Machine Unlearning
Paper and Code
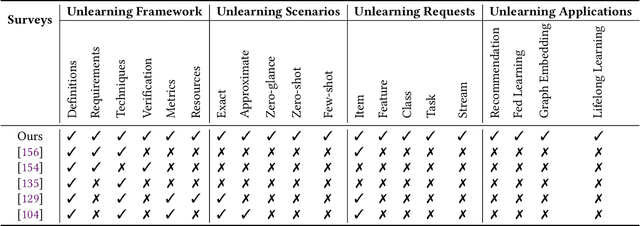



Computer systems hold a large amount of personal data over decades. On the one hand, such data abundance allows breakthroughs in artificial intelligence (AI), especially machine learning (ML) models. On the other hand, it can threaten the privacy of users and weaken the trust between humans and AI. Recent regulations require that private information about a user can be removed from computer systems in general and from ML models in particular upon request (e.g. the "right to be forgotten"). While removing data from back-end databases should be straightforward, it is not sufficient in the AI context as ML models often "remember" the old data. Existing adversarial attacks proved that we can learn private membership or attributes of the training data from the trained models. This phenomenon calls for a new paradigm, namely machine unlearning, to make ML models forget about particular data. It turns out that recent works on machine unlearning have not been able to solve the problem completely due to the lack of common frameworks and resources. In this survey paper, we seek to provide a thorough investigation of machine unlearning in its definitions, scenarios, mechanisms, and applications. Specifically, as a categorical collection of state-of-the-art research, we hope to provide a broad reference for those seeking a primer on machine unlearning and its various formulations, design requirements, removal requests, algorithms, and uses in a variety of ML applications. Furthermore, we hope to outline key findings and trends in the paradigm as well as highlight new areas of research that have yet to see the application of machine unlearning, but could nonetheless benefit immensely. We hope this survey provides a valuable reference for ML researchers as well as those seeking to innovate privacy technologies. Our resources are at https://github.com/tamlhp/awesome-machine-unlearning.