 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNCSTR: Node-Centric Decoupled Spatio-Temporal Reasoning for Video-based Human Pose Estimation
Mar 20, 2026Video-based human pose estimation remains challenged by motion blur, occlusion, and complex spatiotemporal dynamics. Existing methods often rely on heatmaps or implicit spatio-temporal feature aggregation, which limits joint topology expressiveness and weakens cross-frame consistency. To address these problems, we propose a novel node-centric framework that explicitly integrates visual, temporal, and structural reasoning for accurate pose estimation. First, we design a visuo-temporal velocity-based joint embedding that fuses sub-pixel joint cues and inter-frame motion to build appearance- and motion-aware representations. Then, we introduce an attention-driven pose-query encoder, which applies attention over joint-wise heatmaps and frame-wise features to map the joint representations into a pose-aware node space, generating image-conditioned joint-aware node embeddings. Building upon these node embeddings, we propose a dual-branch decoupled spatio-temporal attention graph that models temporal propagation and spatial constraint reasoning in specialized local and global branches. Finally, a node-space expert fusion module is proposed to adaptively fuse the complementary outputs from both branches, integrating local and global cues for final joint predictions. Extensive experiments on three widely used video pose benchmarks demonstrate that our method outperforms state-of-the-art methods. The results highlight the value of explicit node-centric reasoning, offering a new perspective for advancing video-based human pose estimation.
Prompt-Free Lightweight SAM Adaptation for Histopathology Nuclei Segmentation with Strong Cross-Dataset Generalization
Mar 20, 2026Histopathology nuclei segmentation is crucial for quantitative tissue analysis and cancer diagnosis. Although existing segmentation methods have achieved strong performance, they are often computationally heavy and show limited generalization across datasets, which constrains their practical deployment. Recent SAM-based approaches have shown great potential in general and medical imaging, but typically rely on prompt guidance or complex decoders, making them less suitable for histopathology images with dense nuclei and heterogeneous appearances. We propose a prompt-free and lightweight SAM adaptation that leverages multi-level encoder features and residual decoding for accurate and efficient nuclei segmentation. The framework fine-tunes only LoRA modules within the frozen SAM encoder, requiring just 4.1M trainable parameters. Experiments on three benchmark datasets TNBC, MoNuSeg, and PanNuke demonstrate state-of-the-art performance and strong cross-dataset generalization, highlighting the effectiveness and practicality of the proposed framework for histopathology applications.
DCG-Net: Dual Cross-Attention with Concept-Value Graph Reasoning for Interpretable Medical Diagnosis
Mar 20, 2026Deep learning models have achieved strong performance in medical image analysis, but their internal decision processes remain difficult to interpret. Concept Bottleneck Models (CBMs) partially address this limitation by structuring predictions through human-interpretable clinical concepts. However, existing CBMs typically overlook the contextual dependencies among concepts. To address these issues, we propose an end-to-end interpretable framework \emph{DCG-Net} that integrates multimodal alignment with structured concept reasoning. DCG-Net introduces a Dual Cross-Attention module that replaces cosine similarity matching with bidirectional attention between visual tokens and canonicalized textual concept-value prototypes, enabling spatially localized evidence attribution. To capture the relational structure inherent to clinical concepts, we develop a Parametric Concept Graph initialized with Positive Pointwise Mutual Information priors and refined through sparsity-controlled message passing. This formulation models inter-concept dependencies in a manner consistent with clinical domain knowledge. Experiments on white blood cell morphology and skin lesion diagnosis demonstrate that DCG-Net achieves state-of-the-art classification performance while producing clinically interpretable diagnostic explanations.
Explainable and Fine-Grained Safeguarding of LLM Multi-Agent Systems via Bi-Level Graph Anomaly Detection
Dec 21, 2025Large language model (LLM)-based multi-agent systems (MAS) have shown strong capabilities in solving complex tasks. As MAS become increasingly autonomous in various safety-critical tasks, detecting malicious agents has become a critical security concern. Although existing graph anomaly detection (GAD)-based defenses can identify anomalous agents, they mainly rely on coarse sentence-level information and overlook fine-grained lexical cues, leading to suboptimal performance. Moreover, the lack of interpretability in these methods limits their reliability and real-world applicability. To address these limitations, we propose XG-Guard, an explainable and fine-grained safeguarding framework for detecting malicious agents in MAS. To incorporate both coarse and fine-grained textual information for anomalous agent identification, we utilize a bi-level agent encoder to jointly model the sentence- and token-level representations of each agent. A theme-based anomaly detector further captures the evolving discussion focus in MAS dialogues, while a bi-level score fusion mechanism quantifies token-level contributions for explanation. Extensive experiments across diverse MAS topologies and attack scenarios demonstrate robust detection performance and strong interpretability of XG-Guard.
Correcting False Alarms from Unseen: Adapting Graph Anomaly Detectors at Test Time
Nov 10, 2025Graph anomaly detection (GAD), which aims to detect outliers in graph-structured data, has received increasing research attention recently. However, existing GAD methods assume identical training and testing distributions, which is rarely valid in practice. In real-world scenarios, unseen but normal samples may emerge during deployment, leading to a normality shift that degrades the performance of GAD models trained on the original data. Through empirical analysis, we reveal that the degradation arises from (1) semantic confusion, where unseen normal samples are misinterpreted as anomalies due to their novel patterns, and (2) aggregation contamination, where the representations of seen normal nodes are distorted by unseen normals through message aggregation. While retraining or fine-tuning GAD models could be a potential solution to the above challenges, the high cost of model retraining and the difficulty of obtaining labeled data often render this approach impractical in real-world applications. To bridge the gap, we proposed a lightweight and plug-and-play Test-time adaptation framework for correcting Unseen Normal pattErns (TUNE) in GAD. To address semantic confusion, a graph aligner is employed to align the shifted data to the original one at the graph attribute level. Moreover, we utilize the minimization of representation-level shift as a supervision signal to train the aligner, which leverages the estimated aggregation contamination as a key indicator of normality shift. Extensive experiments on 10 real-world datasets demonstrate that TUNE significantly enhances the generalizability of pre-trained GAD models to both synthetic and real unseen normal patterns.
OASIS: Harnessing Diffusion Adversarial Network for Ocean Salinity Imputation using Sparse Drifter Trajectories
Aug 29, 2025Ocean salinity plays a vital role in circulation, climate, and marine ecosystems, yet its measurement is often sparse, irregular, and noisy, especially in drifter-based datasets. Traditional approaches, such as remote sensing and optimal interpolation, rely on linearity and stationarity, and are limited by cloud cover, sensor drift, and low satellite revisit rates. While machine learning models offer flexibility, they often fail under severe sparsity and lack principled ways to incorporate physical covariates without specialized sensors. In this paper, we introduce the OceAn Salinity Imputation System (OASIS), a novel diffusion adversarial framework designed to address these challenges.
Graph Retrieval-Augmented LLM for Conversational Recommendation Systems
Mar 09, 2025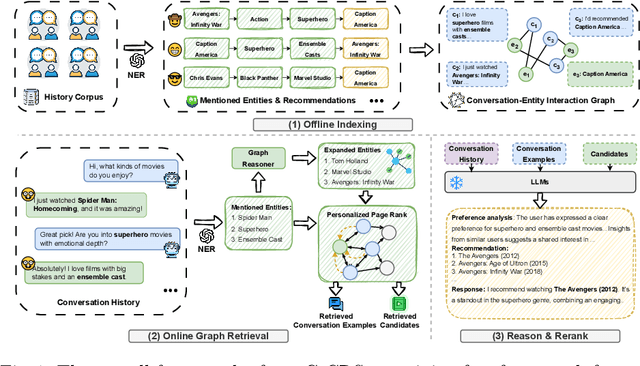
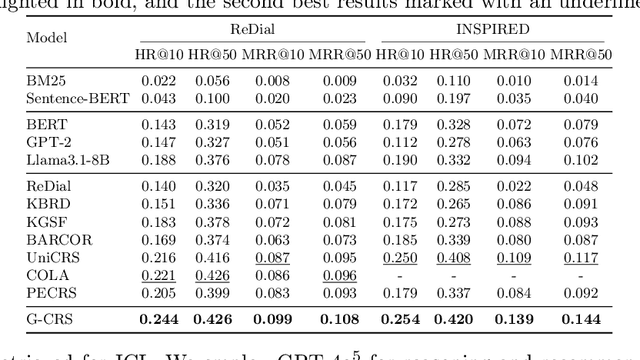
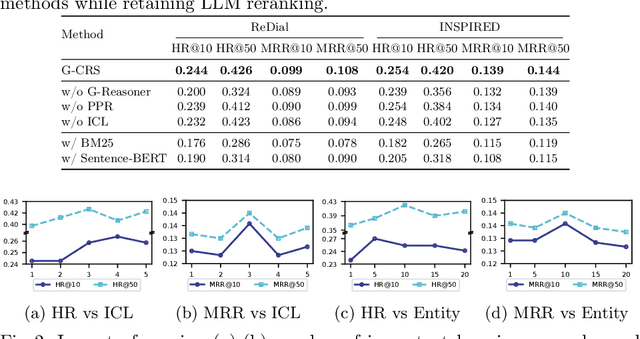
Conversational Recommender Systems (CRSs) have emerged as a transformative paradigm for offering personalized recommendations through natural language dialogue. However, they face challenges with knowledge sparsity, as users often provide brief, incomplete preference statements. While recent methods have integrated external knowledge sources to mitigate this, they still struggle with semantic understanding and complex preference reasoning. Recent Large Language Models (LLMs) demonstrate promising capabilities in natural language understanding and reasoning, showing significant potential for CRSs. Nevertheless, due to the lack of domain knowledge, existing LLM-based CRSs either produce hallucinated recommendations or demand expensive domain-specific training, which largely limits their applicability. In this work, we present G-CRS (Graph Retrieval-Augmented Large Language Model for Conversational Recommender Systems), a novel training-free framework that combines graph retrieval-augmented generation and in-context learning to enhance LLMs' recommendation capabilities. Specifically, G-CRS employs a two-stage retrieve-and-recommend architecture, where a GNN-based graph reasoner first identifies candidate items, followed by Personalized PageRank exploration to jointly discover potential items and similar user interactions. These retrieved contexts are then transformed into structured prompts for LLM reasoning, enabling contextually grounded recommendations without task-specific training. Extensive experiments on two public datasets show that G-CRS achieves superior recommendation performance compared to existing methods without requiring task-specific training.
A Label-Free Heterophily-Guided Approach for Unsupervised Graph Fraud Detection
Feb 18, 2025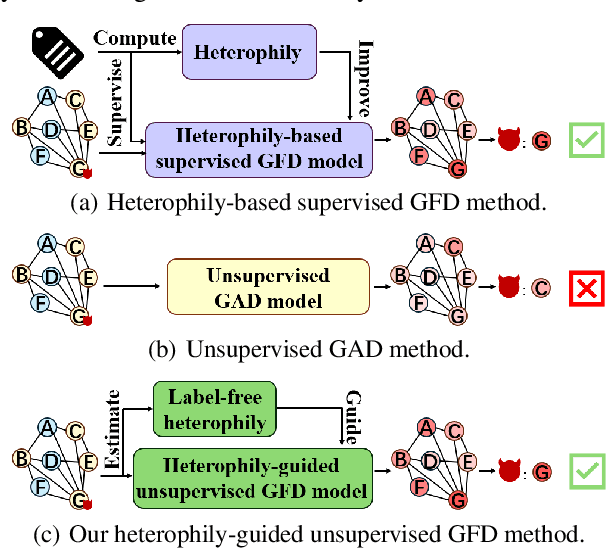

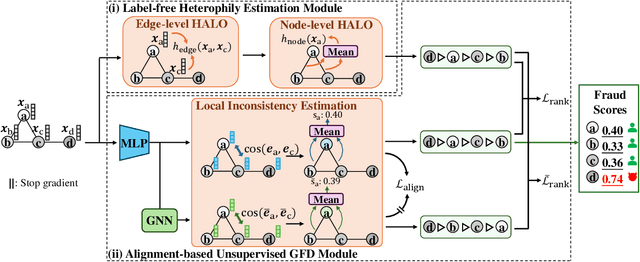
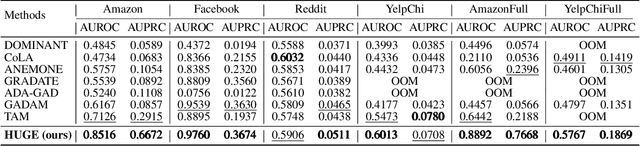
Graph fraud detection (GFD) has rapidly advanced in protecting online services by identifying malicious fraudsters. Recent supervised GFD research highlights that heterophilic connections between fraudsters and users can greatly impact detection performance, since fraudsters tend to camouflage themselves by building more connections to benign users. Despite the promising performance of supervised GFD methods, the reliance on labels limits their applications to unsupervised scenarios; Additionally, accurately capturing complex and diverse heterophily patterns without labels poses a further challenge. To fill the gap, we propose a Heterophily-guided Unsupervised Graph fraud dEtection approach (HUGE) for unsupervised GFD, which contains two essential components: a heterophily estimation module and an alignment-based fraud detection module. In the heterophily estimation module, we design a novel label-free heterophily metric called HALO, which captures the critical graph properties for GFD, enabling its outstanding ability to estimate heterophily from node attributes. In the alignment-based fraud detection module, we develop a joint MLP-GNN architecture with ranking loss and asymmetric alignment loss. The ranking loss aligns the predicted fraud score with the relative order of HALO, providing an extra robustness guarantee by comparing heterophily among non-adjacent nodes. Moreover, the asymmetric alignment loss effectively utilizes structural information while alleviating the feature-smooth effects of GNNs.Extensive experiments on 6 datasets demonstrate that HUGE significantly outperforms competitors, showcasing its effectiveness and robustness. The source code of HUGE is at https://github.com/CampanulaBells/HUGE-GAD.
Privacy-Preserving in Medical Image Analysis: A Review of Methods and Applications
Dec 05, 2024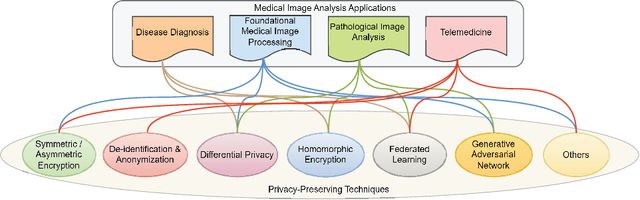
With the rapid advancement of artificial intelligence and deep learning, medical image analysis has become a critical tool in modern healthcare, significantly improving diagnostic accuracy and efficiency. However, AI-based methods also raise serious privacy concerns, as medical images often contain highly sensitive patient information. This review offers a comprehensive overview of privacy-preserving techniques in medical image analysis, including encryption, differential privacy, homomorphic encryption, federated learning, and generative adversarial networks. We explore the application of these techniques across various medical image analysis tasks, such as diagnosis, pathology, and telemedicine. Notably, we organizes the review based on specific challenges and their corresponding solutions in different medical image analysis applications, so that technical applications are directly aligned with practical issues, addressing gaps in the current research landscape. Additionally, we discuss emerging trends, such as zero-knowledge proofs and secure multi-party computation, offering insights for future research. This review serves as a valuable resource for researchers and practitioners and can help advance privacy-preserving in medical image analysis.
Unveiling User Preferences: A Knowledge Graph and LLM-Driven Approach for Conversational Recommendation
Nov 16, 2024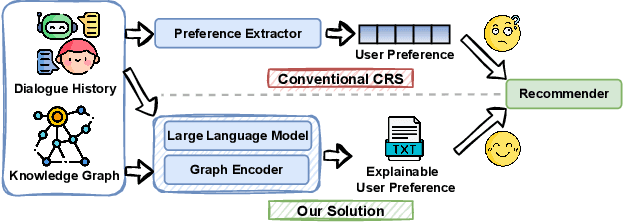
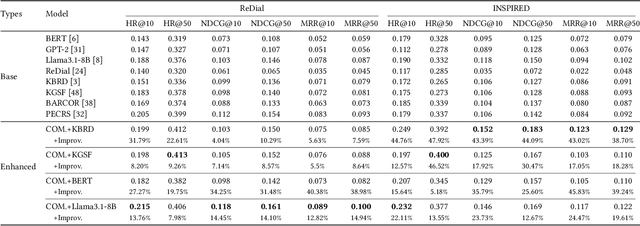
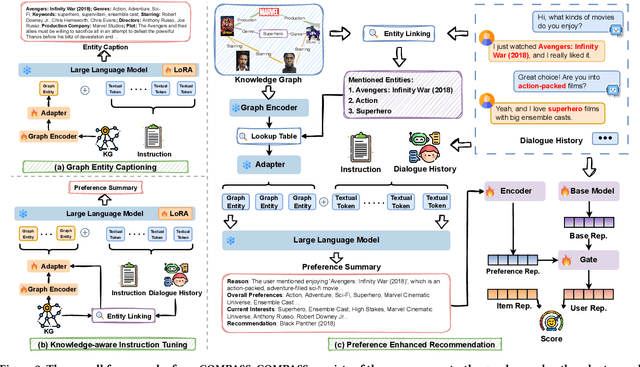
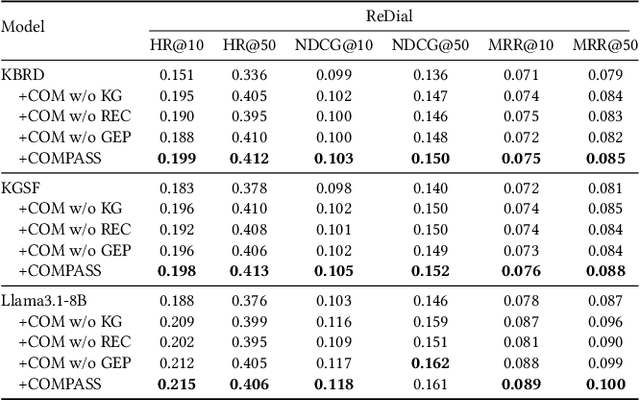
Conversational Recommender Systems (CRSs) aim to provide personalized recommendations through dynamically capturing user preferences in interactive conversations. Conventional CRSs often extract user preferences as hidden representations, which are criticized for their lack of interpretability. This diminishes the transparency and trustworthiness of the recommendation process. Recent works have explored combining the impressive capabilities of Large Language Models (LLMs) with the domain-specific knowledge of Knowledge Graphs (KGs) to generate human-understandable recommendation explanations. Despite these efforts, the integration of LLMs and KGs for CRSs remains challenging due to the modality gap between unstructured dialogues and structured KGs. Moreover, LLMs pre-trained on large-scale corpora may not be well-suited for analyzing user preferences, which require domain-specific knowledge. In this paper, we propose COMPASS, a plug-and-play framework that synergizes LLMs and KGs to unveil user preferences, enhancing the performance and explainability of existing CRSs. To address integration challenges, COMPASS employs a two-stage training approach: first, it bridges the gap between the structured KG and natural language through an innovative graph entity captioning pre-training mechanism. This enables the LLM to transform KG entities into concise natural language descriptions, allowing them to comprehend domain-specific knowledge. Following, COMPASS optimizes user preference modeling via knowledge-aware instruction fine-tuning, where the LLM learns to reason and summarize user preferences from both dialogue histories and KG-augmented context. This enables COMPASS to perform knowledge-aware reasoning and generate comprehensive and interpretable user preferences that can seamlessly integrate with existing CRS models for improving recommendation performance and explainability.