 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Retrieval-Augmented LLM for Conversational Recommendation Systems
Mar 09, 2025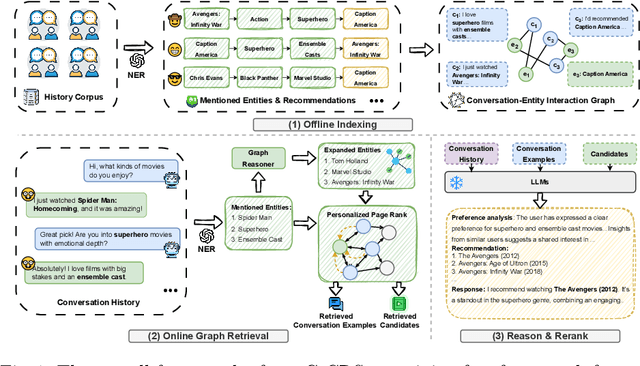
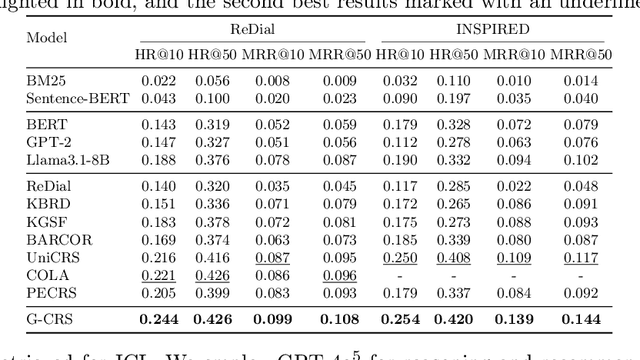
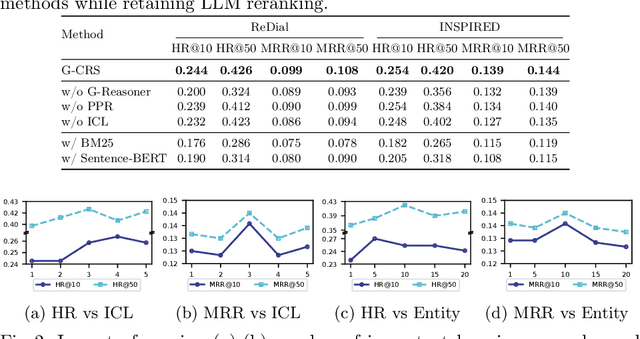
Conversational Recommender Systems (CRSs) have emerged as a transformative paradigm for offering personalized recommendations through natural language dialogue. However, they face challenges with knowledge sparsity, as users often provide brief, incomplete preference statements. While recent methods have integrated external knowledge sources to mitigate this, they still struggle with semantic understanding and complex preference reasoning. Recent Large Language Models (LLMs) demonstrate promising capabilities in natural language understanding and reasoning, showing significant potential for CRSs. Nevertheless, due to the lack of domain knowledge, existing LLM-based CRSs either produce hallucinated recommendations or demand expensive domain-specific training, which largely limits their applicability. In this work, we present G-CRS (Graph Retrieval-Augmented Large Language Model for Conversational Recommender Systems), a novel training-free framework that combines graph retrieval-augmented generation and in-context learning to enhance LLMs' recommendation capabilities. Specifically, G-CRS employs a two-stage retrieve-and-recommend architecture, where a GNN-based graph reasoner first identifies candidate items, followed by Personalized PageRank exploration to jointly discover potential items and similar user interactions. These retrieved contexts are then transformed into structured prompts for LLM reasoning, enabling contextually grounded recommendations without task-specific training. Extensive experiments on two public datasets show that G-CRS achieves superior recommendation performance compared to existing methods without requiring task-specific training.
Unveiling User Preferences: A Knowledge Graph and LLM-Driven Approach for Conversational Recommendation
Nov 16, 2024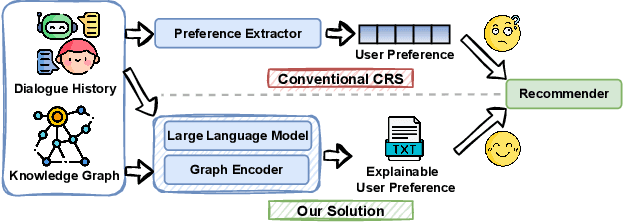
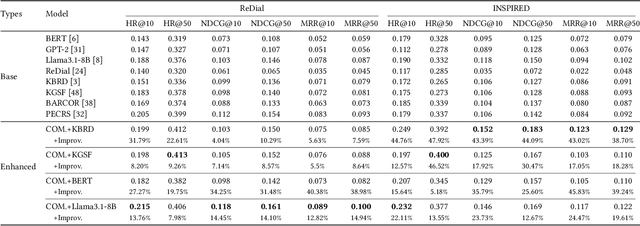
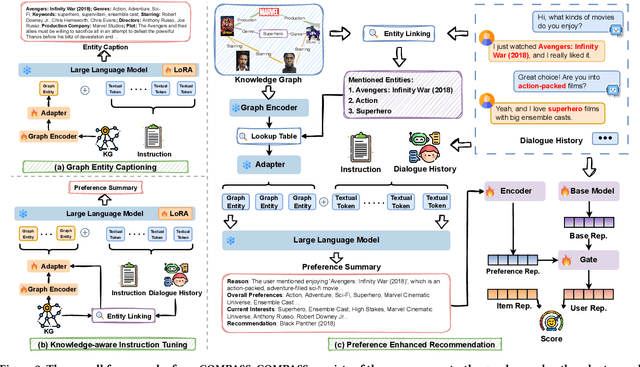
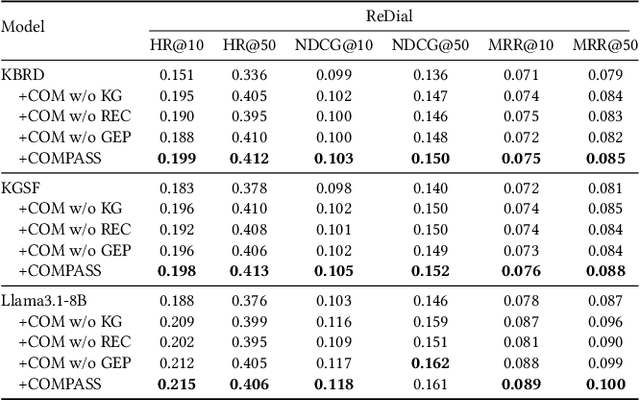
Conversational Recommender Systems (CRSs) aim to provide personalized recommendations through dynamically capturing user preferences in interactive conversations. Conventional CRSs often extract user preferences as hidden representations, which are criticized for their lack of interpretability. This diminishes the transparency and trustworthiness of the recommendation process. Recent works have explored combining the impressive capabilities of Large Language Models (LLMs) with the domain-specific knowledge of Knowledge Graphs (KGs) to generate human-understandable recommendation explanations. Despite these efforts, the integration of LLMs and KGs for CRSs remains challenging due to the modality gap between unstructured dialogues and structured KGs. Moreover, LLMs pre-trained on large-scale corpora may not be well-suited for analyzing user preferences, which require domain-specific knowledge. In this paper, we propose COMPASS, a plug-and-play framework that synergizes LLMs and KGs to unveil user preferences, enhancing the performance and explainability of existing CRSs. To address integration challenges, COMPASS employs a two-stage training approach: first, it bridges the gap between the structured KG and natural language through an innovative graph entity captioning pre-training mechanism. This enables the LLM to transform KG entities into concise natural language descriptions, allowing them to comprehend domain-specific knowledge. Following, COMPASS optimizes user preference modeling via knowledge-aware instruction fine-tuning, where the LLM learns to reason and summarize user preferences from both dialogue histories and KG-augmented context. This enables COMPASS to perform knowledge-aware reasoning and generate comprehensive and interpretable user preferences that can seamlessly integrate with existing CRS models for improving recommendation performance and explainability.
Knowledge Graphs and Pre-trained Language Models enhanced Representation Learning for Conversational Recommender Systems
Dec 27, 2023



Conversational recommender systems (CRS) utilize natural language interactions and dialogue history to infer user preferences and provide accurate recommendations. Due to the limited conversation context and background knowledge, existing CRSs rely on external sources such as knowledge graphs to enrich the context and model entities based on their inter-relations. However, these methods ignore the rich intrinsic information within entities. To address this, we introduce the Knowledge-Enhanced Entity Representation Learning (KERL) framework, which leverages both the knowledge graph and a pre-trained language model to improve the semantic understanding of entities for CRS. In our KERL framework, entity textual descriptions are encoded via a pre-trained language model, while a knowledge graph helps reinforce the representation of these entities. We also employ positional encoding to effectively capture the temporal information of entities in a conversation. The enhanced entity representation is then used to develop a recommender component that fuses both entity and contextual representations for more informed recommendations, as well as a dialogue component that generates informative entity-related information in the response text. A high-quality knowledge graph with aligned entity descriptions is constructed to facilitate our study, namely the Wiki Movie Knowledge Graph (WikiMKG). The experimental results show that KERL achieves state-of-the-art results in both recommendation and response generation tasks.