 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentMark: Utility-Preserving Behavioral Watermarking for Agents
Jan 05, 2026LLM-based agents are increasingly deployed to autonomously solve complex tasks, raising urgent needs for IP protection and regulatory provenance. While content watermarking effectively attributes LLM-generated outputs, it fails to directly identify the high-level planning behaviors (e.g., tool and subgoal choices) that govern multi-step execution. Critically, watermarking at the planning-behavior layer faces unique challenges: minor distributional deviations in decision-making can compound during long-term agent operation, degrading utility, and many agents operate as black boxes that are difficult to intervene in directly. To bridge this gap, we propose AgentMark, a behavioral watermarking framework that embeds multi-bit identifiers into planning decisions while preserving utility. It operates by eliciting an explicit behavior distribution from the agent and applying distribution-preserving conditional sampling, enabling deployment under black-box APIs while remaining compatible with action-layer content watermarking. Experiments across embodied, tool-use, and social environments demonstrate practical multi-bit capacity, robust recovery from partial logs, and utility preservation. The code is available at https://github.com/Tooooa/AgentMark.
GGTalker: Talking Head Systhesis with Generalizable Gaussian Priors and Identity-Specific Adaptation
Jun 26, 2025Creating high-quality, generalizable speech-driven 3D talking heads remains a persistent challenge. Previous methods achieve satisfactory results for fixed viewpoints and small-scale audio variations, but they struggle with large head rotations and out-of-distribution (OOD) audio. Moreover, they are constrained by the need for time-consuming, identity-specific training. We believe the core issue lies in the lack of sufficient 3D priors, which limits the extrapolation capabilities of synthesized talking heads. To address this, we propose GGTalker, which synthesizes talking heads through a combination of generalizable priors and identity-specific adaptation. We introduce a two-stage Prior-Adaptation training strategy to learn Gaussian head priors and adapt to individual characteristics. We train Audio-Expression and Expression-Visual priors to capture the universal patterns of lip movements and the general distribution of head textures. During the Customized Adaptation, individual speaking styles and texture details are precisely modeled. Additionally, we introduce a color MLP to generate fine-grained, motion-aligned textures and a Body Inpainter to blend rendered results with the background, producing indistinguishable, photorealistic video frames. Comprehensive experiments show that GGTalker achieves state-of-the-art performance in rendering quality, 3D consistency, lip-sync accuracy, and training efficiency.
SyncTalk++: High-Fidelity and Efficient Synchronized Talking Heads Synthesis Using Gaussian Splatting
Jun 17, 2025



Achieving high synchronization in the synthesis of realistic, speech-driven talking head videos presents a significant challenge. A lifelike talking head requires synchronized coordination of subject identity, lip movements, facial expressions, and head poses. The absence of these synchronizations is a fundamental flaw, leading to unrealistic results. To address the critical issue of synchronization, identified as the ''devil'' in creating realistic talking heads, we introduce SyncTalk++, which features a Dynamic Portrait Renderer with Gaussian Splatting to ensure consistent subject identity preservation and a Face-Sync Controller that aligns lip movements with speech while innovatively using a 3D facial blendshape model to reconstruct accurate facial expressions. To ensure natural head movements, we propose a Head-Sync Stabilizer, which optimizes head poses for greater stability. Additionally, SyncTalk++ enhances robustness to out-of-distribution (OOD) audio by incorporating an Expression Generator and a Torso Restorer, which generate speech-matched facial expressions and seamless torso regions. Our approach maintains consistency and continuity in visual details across frames and significantly improves rendering speed and quality, achieving up to 101 frames per second. Extensive experiments and user studies demonstrate that SyncTalk++ outperforms state-of-the-art methods in synchronization and realism. We recommend watching the supplementary video: https://ziqiaopeng.github.io/synctalk++.
Federated Intelligence: When Large AI Models Meet Federated Fine-Tuning and Collaborative Reasoning at the Network Edge
Mar 27, 2025Large artificial intelligence (AI) models exhibit remarkable capabilities in various application scenarios, but deploying them at the network edge poses significant challenges due to issues such as data privacy, computational resources, and latency. In this paper, we explore federated fine-tuning and collaborative reasoning techniques to facilitate the implementation of large AI models in resource-constrained wireless networks. Firstly, promising applications of large AI models within specific domains are discussed. Subsequently, federated fine-tuning methods are proposed to adapt large AI models to specific tasks or environments at the network edge, effectively addressing the challenges associated with communication overhead and enhancing communication efficiency. These methodologies follow clustered, hierarchical, and asynchronous paradigms to effectively tackle privacy issues and eliminate data silos. Furthermore, to enhance operational efficiency and reduce latency, efficient frameworks for model collaborative reasoning are developed, which include decentralized horizontal collaboration, cloud-edge-end vertical collaboration, and multi-access collaboration. Next, simulation results demonstrate the effectiveness of our proposed methods in reducing the fine-tuning loss of large AI models across various downstream tasks. Finally, several open challenges and research opportunities are outlined.
* 8 pages, 6 figures
Privacy-Preserving in Medical Image Analysis: A Review of Methods and Applications
Dec 05, 2024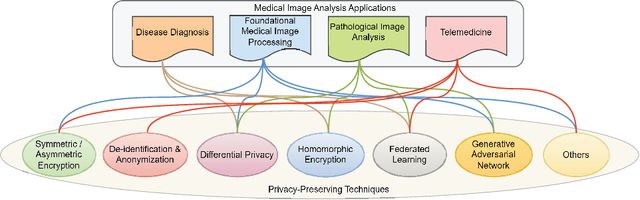
With the rapid advancement of artificial intelligence and deep learning, medical image analysis has become a critical tool in modern healthcare, significantly improving diagnostic accuracy and efficiency. However, AI-based methods also raise serious privacy concerns, as medical images often contain highly sensitive patient information. This review offers a comprehensive overview of privacy-preserving techniques in medical image analysis, including encryption, differential privacy, homomorphic encryption, federated learning, and generative adversarial networks. We explore the application of these techniques across various medical image analysis tasks, such as diagnosis, pathology, and telemedicine. Notably, we organizes the review based on specific challenges and their corresponding solutions in different medical image analysis applications, so that technical applications are directly aligned with practical issues, addressing gaps in the current research landscape. Additionally, we discuss emerging trends, such as zero-knowledge proofs and secure multi-party computation, offering insights for future research. This review serves as a valuable resource for researchers and practitioners and can help advance privacy-preserving in medical image analysis.
GROOT: Generating Robust Watermark for Diffusion-Model-Based Audio Synthesis
Jul 15, 2024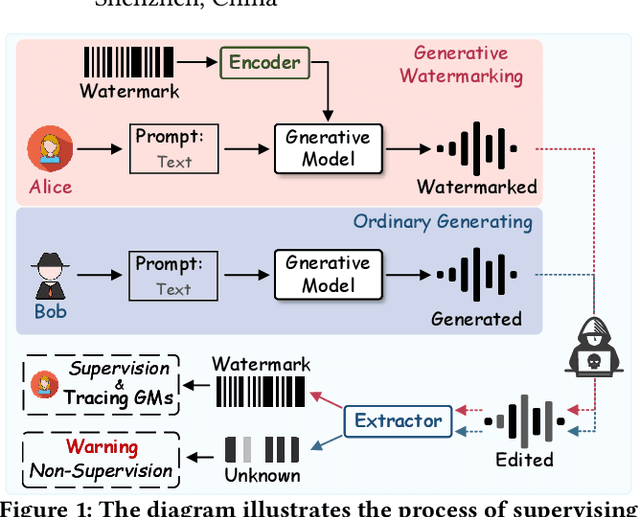
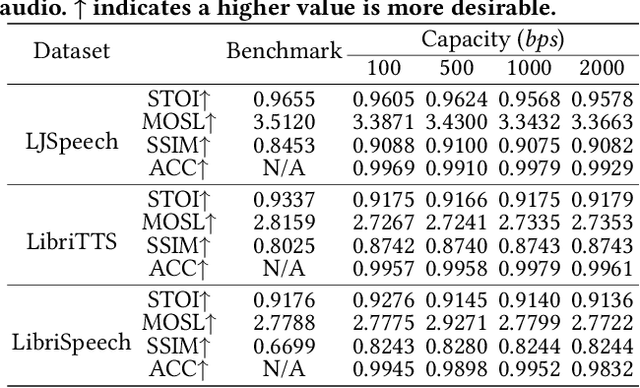
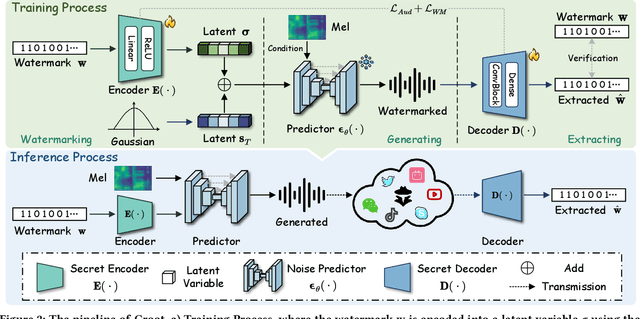
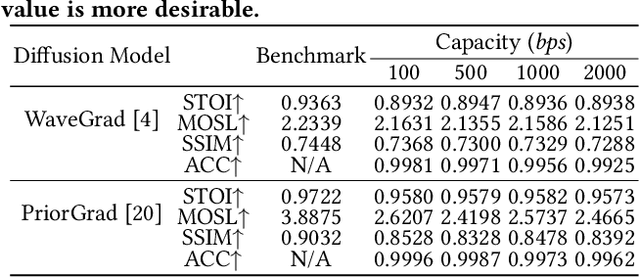
Amid the burgeoning development of generative models like diffusion models, the task of differentiating synthesized audio from its natural counterpart grows more daunting. Deepfake detection offers a viable solution to combat this challenge. Yet, this defensive measure unintentionally fuels the continued refinement of generative models. Watermarking emerges as a proactive and sustainable tactic, preemptively regulating the creation and dissemination of synthesized content. Thus, this paper, as a pioneer, proposes the generative robust audio watermarking method (Groot), presenting a paradigm for proactively supervising the synthesized audio and its source diffusion models. In this paradigm, the processes of watermark generation and audio synthesis occur simultaneously, facilitated by parameter-fixed diffusion models equipped with a dedicated encoder. The watermark embedded within the audio can subsequently be retrieved by a lightweight decoder. The experimental results highlight Groot's outstanding performance, particularly in terms of robustness, surpassing that of the leading state-of-the-art methods. Beyond its impressive resilience against individual post-processing attacks, Groot exhibits exceptional robustness when facing compound attacks, maintaining an average watermark extraction accuracy of around 95%.
LiDAR-Guided Cross-Attention Fusion for Hyperspectral Band Selection and Image Classification
Apr 15, 2024



The fusion of hyperspectral and LiDAR data has been an active research topic. Existing fusion methods have ignored the high-dimensionality and redundancy challenges in hyperspectral images, despite that band selection methods have been intensively studied for hyperspectral image (HSI) processing. This paper addresses this significant gap by introducing a cross-attention mechanism from the transformer architecture for the selection of HSI bands guided by LiDAR data. LiDAR provides high-resolution vertical structural information, which can be useful in distinguishing different types of land cover that may have similar spectral signatures but different structural profiles. In our approach, the LiDAR data are used as the "query" to search and identify the "key" from the HSI to choose the most pertinent bands for LiDAR. This method ensures that the selected HSI bands drastically reduce redundancy and computational requirements while working optimally with the LiDAR data. Extensive experiments have been undertaken on three paired HSI and LiDAR data sets: Houston 2013, Trento and MUUFL. The results highlight the superiority of the cross-attention mechanism, underlining the enhanced classification accuracy of the identified HSI bands when fused with the LiDAR features. The results also show that the use of fewer bands combined with LiDAR surpasses the performance of state-of-the-art fusion models.
* 15 pages, 13 figures
Unsupervised Band Selection Using Fused HSI and LiDAR Attention Integrating With Autoencoder
Apr 08, 2024Band selection in hyperspectral imaging (HSI) is critical for optimising data processing and enhancing analytical accuracy. Traditional approaches have predominantly concentrated on analysing spectral and pixel characteristics within individual bands independently. These approaches overlook the potential benefits of integrating multiple data sources, such as Light Detection and Ranging (LiDAR), and is further challenged by the limited availability of labeled data in HSI processing, which represents a significant obstacle. To address these challenges, this paper introduces a novel unsupervised band selection framework that incorporates attention mechanisms and an Autoencoder for reconstruction-based band selection. Our methodology distinctively integrates HSI with LiDAR data through an attention score, using a convolutional Autoencoder to process the combined feature mask. This fusion effectively captures essential spatial and spectral features and reduces redundancy in hyperspectral datasets. A comprehensive comparative analysis of our innovative fused band selection approach is performed against existing unsupervised band selection and fusion models. We used data sets such as Houston 2013, Trento, and MUUFLE for our experiments. The results demonstrate that our method achieves superior classification accuracy and significantly outperforms existing models. This enhancement in HSI band selection, facilitated by the incorporation of LiDAR features, underscores the considerable advantages of integrating features from different sources.
HSIMamba: Hyperpsectral Imaging Efficient Feature Learning with Bidirectional State Space for Classification
Mar 30, 2024Classifying hyperspectral images is a difficult task in remote sensing, due to their complex high-dimensional data. To address this challenge, we propose HSIMamba, a novel framework that uses bidirectional reversed convolutional neural network pathways to extract spectral features more efficiently. Additionally, it incorporates a specialized block for spatial analysis. Our approach combines the operational efficiency of CNNs with the dynamic feature extraction capability of attention mechanisms found in Transformers. However, it avoids the associated high computational demands. HSIMamba is designed to process data bidirectionally, significantly enhancing the extraction of spectral features and integrating them with spatial information for comprehensive analysis. This approach improves classification accuracy beyond current benchmarks and addresses computational inefficiencies encountered with advanced models like Transformers. HSIMamba were tested against three widely recognized datasets Houston 2013, Indian Pines, and Pavia University and demonstrated exceptional performance, surpassing existing state-of-the-art models in HSI classification. This method highlights the methodological innovation of HSIMamba and its practical implications, which are particularly valuable in contexts where computational resources are limited. HSIMamba redefines the standards of efficiency and accuracy in HSI classification, thereby enhancing the capabilities of remote sensing applications. Hyperspectral imaging has become a crucial tool for environmental surveillance, agriculture, and other critical areas that require detailed analysis of the Earth surface. Please see our code in HSIMamba for more details.
Surface Reconstruction from Point Clouds via Grid-based Intersection Prediction
Mar 21, 2024Surface reconstruction from point clouds is a crucial task in the fields of computer vision and computer graphics. SDF-based methods excel at reconstructing smooth meshes with minimal error and artifacts but struggle with representing open surfaces. On the other hand, UDF-based methods can effectively represent open surfaces but often introduce noise near the surface, leading to artifacts in the mesh. In this work, we propose a novel approach that directly predicts the intersection points between sampled line segments of point pairs and implicit surfaces. This method not only preserves the ability to represent open surfaces but also eliminates artifacts in the mesh. Our approach demonstrates state-of-the-art performance on three datasets: ShapeNet, MGN, and ScanNet. The code will be made available upon acceptance.