 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkywork-R1V3 Technical Report
Jul 09, 2025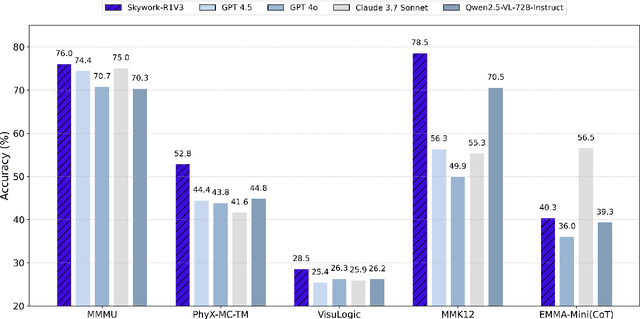
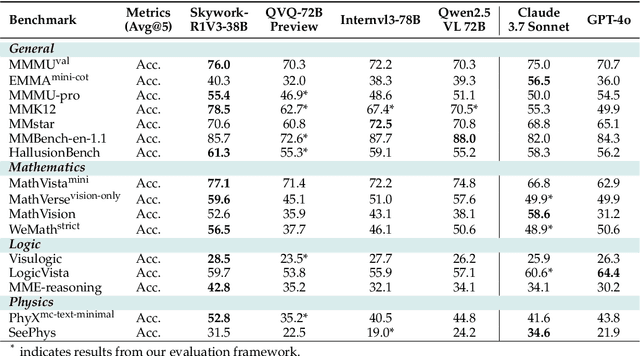
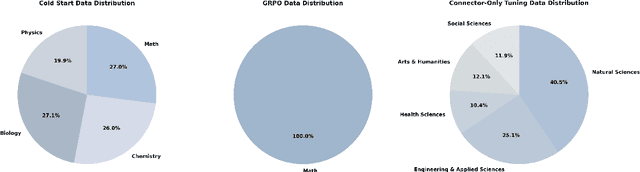

We introduce Skywork-R1V3, an advanced, open-source vision-language model (VLM) that pioneers a new approach to visual reasoning. Its key innovation lies in effectively transferring reasoning skills from text-only Large Language Models (LLMs) to visual tasks. The strong performance of Skywork-R1V3 primarily stems from our elaborate post-training RL framework, which effectively activates and enhances the model's reasoning ability, without the need for additional continue pre-training. Through this framework, we further uncover the fundamental role of the connector module in achieving robust cross-modal alignment for multimodal reasoning models. In addition, we introduce a unique indicator of reasoning capability, the entropy of critical reasoning tokens, which has proven highly effective for checkpoint selection during RL training. Skywork-R1V3 achieves state-of-the-art results on MMMU, significantly improving from 64.3% to 76.0%. This performance matches entry-level human capabilities. Remarkably, our RL-powered post-training approach enables even the 38B parameter model to rival top closed-source VLMs. The implementation successfully transfers mathematical reasoning to other subject-related reasoning tasks. We also include an analysis of curriculum learning and reinforcement finetuning strategies, along with a broader discussion on multimodal reasoning. Skywork-R1V3 represents a significant leap in multimodal reasoning, showcasing RL as a powerful engine for advancing open-source VLM capabilities.
Multi-Task Semantic Communications via Large Models
Mar 28, 2025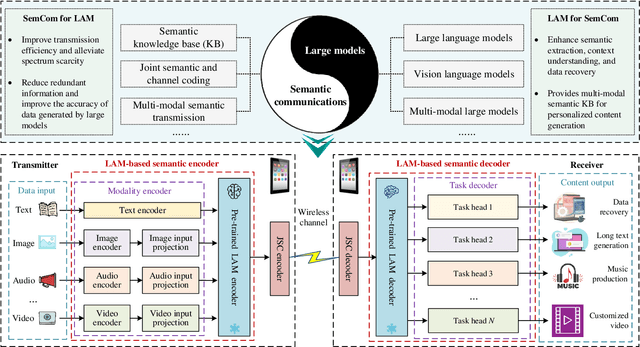
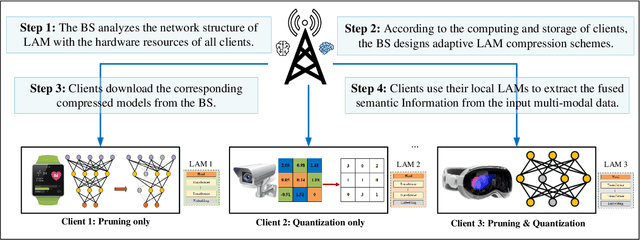
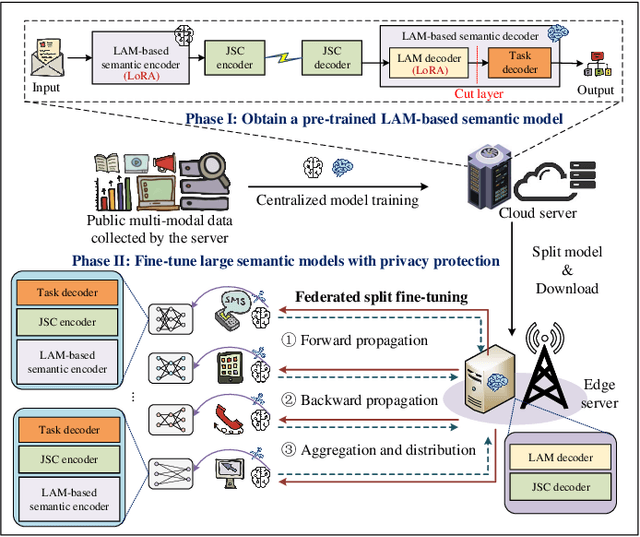
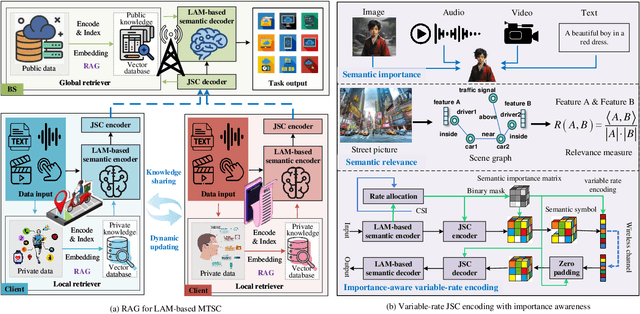
Artificial intelligence (AI) promises to revolutionize the design, optimization and management of next-generation communication systems. In this article, we explore the integration of large AI models (LAMs) into semantic communications (SemCom) by leveraging their multi-modal data processing and generation capabilities. Although LAMs bring unprecedented abilities to extract semantics from raw data, this integration entails multifaceted challenges including high resource demands, model complexity, and the need for adaptability across diverse modalities and tasks. To overcome these challenges, we propose a LAM-based multi-task SemCom (MTSC) architecture, which includes an adaptive model compression strategy and a federated split fine-tuning approach to facilitate the efficient deployment of LAM-based semantic models in resource-limited networks. Furthermore, a retrieval-augmented generation scheme is implemented to synthesize the most recent local and global knowledge bases to enhance the accuracy of semantic extraction and content generation, thereby improving the inference performance. Finally, simulation results demonstrate the efficacy of the proposed LAM-based MTSC architecture, highlighting the performance enhancements across various downstream tasks under varying channel conditions.
Federated Intelligence: When Large AI Models Meet Federated Fine-Tuning and Collaborative Reasoning at the Network Edge
Mar 27, 2025Large artificial intelligence (AI) models exhibit remarkable capabilities in various application scenarios, but deploying them at the network edge poses significant challenges due to issues such as data privacy, computational resources, and latency. In this paper, we explore federated fine-tuning and collaborative reasoning techniques to facilitate the implementation of large AI models in resource-constrained wireless networks. Firstly, promising applications of large AI models within specific domains are discussed. Subsequently, federated fine-tuning methods are proposed to adapt large AI models to specific tasks or environments at the network edge, effectively addressing the challenges associated with communication overhead and enhancing communication efficiency. These methodologies follow clustered, hierarchical, and asynchronous paradigms to effectively tackle privacy issues and eliminate data silos. Furthermore, to enhance operational efficiency and reduce latency, efficient frameworks for model collaborative reasoning are developed, which include decentralized horizontal collaboration, cloud-edge-end vertical collaboration, and multi-access collaboration. Next, simulation results demonstrate the effectiveness of our proposed methods in reducing the fine-tuning loss of large AI models across various downstream tasks. Finally, several open challenges and research opportunities are outlined.
* 8 pages, 6 figures