 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Method with Encoder-Decoder for Cross-Sensor Adaptation in Surface Shape Sensing with Sparse Strain Sensors
Jun 04, 2026Performance variations in sensor arrays, caused by intrinsic differences or installation conditions, can lead to inconsistent results during shape sensing. To obtain accurate results, a large amount of data is usually required, and a separate model must be retrained for each sensor array, thereby increasing the cost and time of data acquisition, transmission, and computation. To address this issue, this work proposes an encoder-decoder architecture for surface shape sensing based on sparse strain sensors and further incorporates meta-learning and few-shot adaptation strategies to enable adaptation across different groups of sensor arrays. Experimental results demonstrate that, after the cross-sensor adaptation, a newly deployed sensor array achieves a sensing error of approximately 4.0 mm relying on less than 5.0% newly labeled data and requiring an adaptation time of under 1 second, which represents a substantial improvement from 23.0 mm error without adaptation and 20-minute data collection time required to train a new model. Moreover, the number of points with errors below 5.0 mm increased by more than 65.0%. These results indicate that the proposed method can substantially reduce the cost and training burden of surface shape sensing, and it has broad potential applications in soft robotics and wearable devices.
Joint Angle Estimation with Customized Wristband Based on Online Incremental Learning
May 28, 2026Intelligent wearable technology plays an increasingly important role in human-computer interaction, motion, and health monitoring. To ensure comfort and practicality of use, one common form for motion monitoring is to utilize soft wearable sensors. However, many research applications regarding wearable sensors are simplistic and difficult to adapt to different situations. This study proposes a system for estimating the angle of the wrist joint using a customized wristband based on an online incremental learning approach. It is a two-stage estimation method: the first stage updates the model based on the wearer's wrist movement characteristics using online learning, integrating real-time data from an IMU as ground truth. The second stage utilizes the updated model for estimation of wrist joint angle solely with the wristband. In other words, model training is completed during data acquisition, allowing the trained model to be used for subsequent angle estimation. This method offers advantages in adapting to data drift caused by variations in different testing configurations, such as the left and right wrists of the same subject, deviations in the wearing position on the same wrist, and even differences among various subjects. The results indicate that the sensors exhibit good performance under strain variations, and the wrist joint trajectory estimation of the proposed system has an approximate error of 15 degree in different scenarios.
Object-Attribute-Relation Model Driven Adaptive Hierarchical Transmission for Multimodal Semantic Communication
Apr 09, 2026Traditional video coding (VVC, HEVC) prioritizes human visual perception, transmitting substantial texture redundancy that severely hinders machine decision-making under constrained bandwidths. In dynamic channels, this redundancy causes severe ``cliff effects'' and prohibitive latency. To address this, we propose a robust multimodal semantic communication framework based on an adaptive Object-Attribute-Relation (O-A-R) hierarchy. Bypassing pixel-level reconstruction entirely, our framework directly fuses visual, textual, and audio streams to construct a decision-oriented topological graph. A bandwidth-adaptive strategy dynamically allocates resources by semantic priority, while a cross-modal mechanism leverages text and audio priors to compensate for severe visual degradation. Experimental results demonstrate that under extreme low bandwidths (1-3 kbps), our method achieves over a 90% bandwidth saving (an approximately 10-fold reduction) compared to state-of-the-art digital schemes, maintaining superior scene-graph accuracy. In deep fading channels (SNR <= 4 dB), it completely eliminates the cliff effect, ensuring graceful degradation by strictly preserving foundational object anchors even when traditional codecs suffer 100% decoding failure. Coupled with an 89\% reduction in end-to-end latency, our framework comprehensively fulfills the real-time survival requirements of embodied agents.
Efficient Equivariant High-Order Crystal Tensor Prediction via Cartesian Local-Environment Many-Body Coupling
Feb 04, 2026End-to-end prediction of high-order crystal tensor properties from atomic structures remains challenging: while spherical-harmonic equivariant models are expressive, their Clebsch-Gordan tensor products incur substantial compute and memory costs for higher-order targets. We propose the Cartesian Environment Interaction Tensor Network (CEITNet), an approach that constructs a multi-channel Cartesian local environment tensor for each atom and performs flexible many-body mixing via a learnable channel-space interaction. By performing learning in channel space and using Cartesian tensor bases to assemble equivariant outputs, CEITNet enables efficient construction of high-order tensor. Across benchmark datasets for order-2 dielectric, order-3 piezoelectric, and order-4 elastic tensor prediction, CEITNet surpasses prior high-order prediction methods on key accuracy criteria while offering high computational efficiency.
Assisted Refinement Network Based on Channel Information Interaction for Camouflaged and Salient Object Detection
Dec 12, 2025Camouflaged Object Detection (COD) stands as a significant challenge in computer vision, dedicated to identifying and segmenting objects visually highly integrated with their backgrounds. Current mainstream methods have made progress in cross-layer feature fusion, but two critical issues persist during the decoding stage. The first is insufficient cross-channel information interaction within the same-layer features, limiting feature expressiveness. The second is the inability to effectively co-model boundary and region information, making it difficult to accurately reconstruct complete regions and sharp boundaries of objects. To address the first issue, we propose the Channel Information Interaction Module (CIIM), which introduces a horizontal-vertical integration mechanism in the channel dimension. This module performs feature reorganization and interaction across channels to effectively capture complementary cross-channel information. To address the second issue, we construct a collaborative decoding architecture guided by prior knowledge. This architecture generates boundary priors and object localization maps through Boundary Extraction (BE) and Region Extraction (RE) modules, then employs hybrid attention to collaboratively calibrate decoded features, effectively overcoming semantic ambiguity and imprecise boundaries. Additionally, the Multi-scale Enhancement (MSE) module enriches contextual feature representations. Extensive experiments on four COD benchmark datasets validate the effectiveness and state-of-the-art performance of the proposed model. We further transferred our model to the Salient Object Detection (SOD) task and demonstrated its adaptability across downstream tasks, including polyp segmentation, transparent object detection, and industrial and road defect detection. Code and experimental results are publicly available at: https://github.com/akuan1234/ARNet-v2.
Joint Semantic-Channel Coding and Modulation for Token Communications
Nov 19, 2025In recent years, the Transformer architecture has achieved outstanding performance across a wide range of tasks and modalities. Token is the unified input and output representation in Transformer-based models, which has become a fundamental information unit. In this work, we consider the problem of token communication, studying how to transmit tokens efficiently and reliably. Point cloud, a prevailing three-dimensional format which exhibits a more complex spatial structure compared to image or video, is chosen to be the information source. We utilize the set abstraction method to obtain point tokens. Subsequently, to get a more informative and transmission-friendly representation based on tokens, we propose a joint semantic-channel and modulation (JSCCM) scheme for the token encoder, mapping point tokens to standard digital constellation points (modulated tokens). Specifically, the JSCCM consists of two parallel Point Transformer-based encoders and a differential modulator which combines the Gumel-softmax and soft quantization methods. Besides, the rate allocator and channel adapter are developed, facilitating adaptive generation of high-quality modulated tokens conditioned on both semantic information and channel conditions. Extensive simulations demonstrate that the proposed method outperforms both joint semantic-channel coding and traditional separate coding, achieving over 1dB gain in reconstruction and more than 6x compression ratio in modulated symbols.
Magnitude-Modulated Equivariant Adapter for Parameter-Efficient Fine-Tuning of Equivariant Graph Neural Networks
Nov 10, 2025Pretrained equivariant graph neural networks based on spherical harmonics offer efficient and accurate alternatives to computationally expensive ab-initio methods, yet adapting them to new tasks and chemical environments still requires fine-tuning. Conventional parameter-efficient fine-tuning (PEFT) techniques, such as Adapters and LoRA, typically break symmetry, making them incompatible with those equivariant architectures. ELoRA, recently proposed, is the first equivariant PEFT method. It achieves improved parameter efficiency and performance on many benchmarks. However, the relatively high degrees of freedom it retains within each tensor order can still perturb pretrained feature distributions and ultimately degrade performance. To address this, we present Magnitude-Modulated Equivariant Adapter (MMEA), a novel equivariant fine-tuning method which employs lightweight scalar gating to modulate feature magnitudes on a per-order and per-multiplicity basis. We demonstrate that MMEA preserves strict equivariance and, across multiple benchmarks, consistently improves energy and force predictions to state-of-the-art levels while training fewer parameters than competing approaches. These results suggest that, in many practical scenarios, modulating channel magnitudes is sufficient to adapt equivariant models to new chemical environments without breaking symmetry, pointing toward a new paradigm for equivariant PEFT design.
Few-shot Semantic Encoding and Decoding for Video Surveillance
May 12, 2025With the continuous increase in the number and resolution of video surveillance cameras, the burden of transmitting and storing surveillance video is growing. Traditional communication methods based on Shannon's theory are facing optimization bottlenecks. Semantic communication, as an emerging communication method, is expected to break through this bottleneck and reduce the storage and transmission consumption of video. Existing semantic decoding methods often require many samples to train the neural network for each scene, which is time-consuming and labor-intensive. In this study, a semantic encoding and decoding method for surveillance video is proposed. First, the sketch was extracted as semantic information, and a sketch compression method was proposed to reduce the bit rate of semantic information. Then, an image translation network was proposed to translate the sketch into a video frame with a reference frame. Finally, a few-shot sketch decoding network was proposed to reconstruct video from sketch. Experimental results showed that the proposed method achieved significantly better video reconstruction performance than baseline methods. The sketch compression method could effectively reduce the storage and transmission consumption of semantic information with little compromise on video quality. The proposed method provides a novel semantic encoding and decoding method that only needs a few training samples for each surveillance scene, thus improving the practicality of the semantic communication system.
Multi-Task Semantic Communications via Large Models
Mar 28, 2025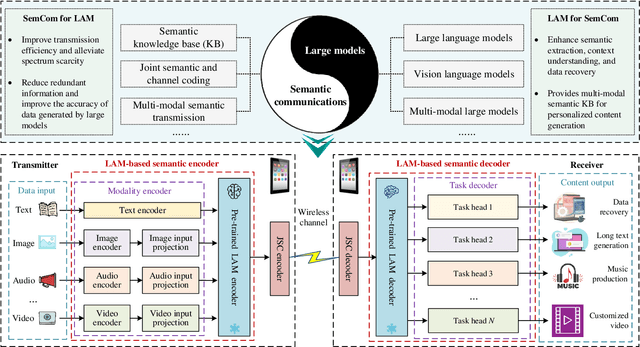
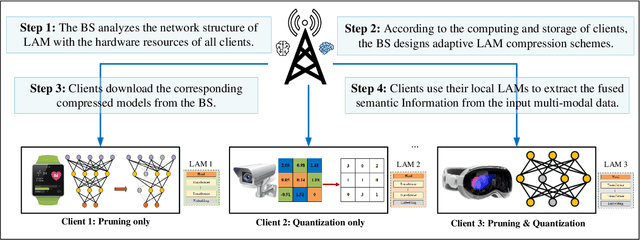
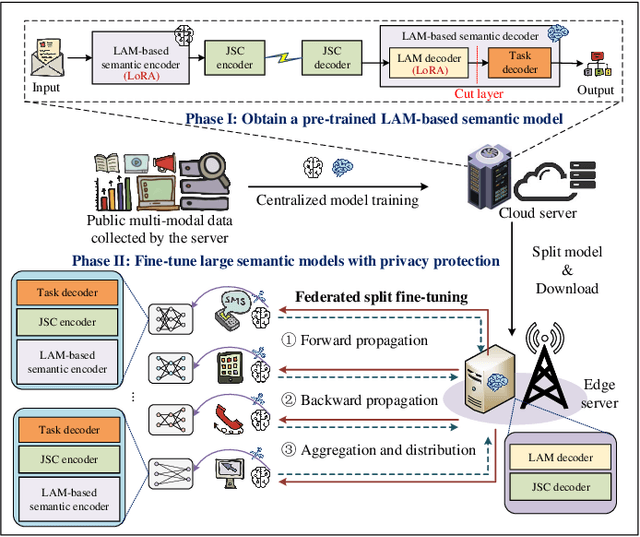
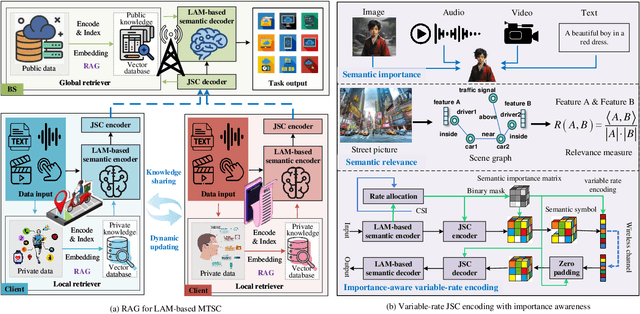
Artificial intelligence (AI) promises to revolutionize the design, optimization and management of next-generation communication systems. In this article, we explore the integration of large AI models (LAMs) into semantic communications (SemCom) by leveraging their multi-modal data processing and generation capabilities. Although LAMs bring unprecedented abilities to extract semantics from raw data, this integration entails multifaceted challenges including high resource demands, model complexity, and the need for adaptability across diverse modalities and tasks. To overcome these challenges, we propose a LAM-based multi-task SemCom (MTSC) architecture, which includes an adaptive model compression strategy and a federated split fine-tuning approach to facilitate the efficient deployment of LAM-based semantic models in resource-limited networks. Furthermore, a retrieval-augmented generation scheme is implemented to synthesize the most recent local and global knowledge bases to enhance the accuracy of semantic extraction and content generation, thereby improving the inference performance. Finally, simulation results demonstrate the efficacy of the proposed LAM-based MTSC architecture, highlighting the performance enhancements across various downstream tasks under varying channel conditions.
Corrections to "Computer Vision Aided mmWave Beam Alignment in V2X Communications"
Oct 08, 2024



In this document, we revise the results of [1] based on more reasonable assumptions regarding data shuffling and parameter setup of deep neural networks (DNNs). Thus, the simulation results can now more reasonably demonstrate the performance of both the proposed and compared beam alignment methods. We revise the simulation steps and make moderate modifications to the design of the vehicle distribution feature (VDF) for the proposed vision based beam alignment when the MS location is available (VBALA). Specifically, we replace the 2D grids of the VDF with 3D grids and utilize the vehicle locations to expand the dimensions of the VDF. Then, we revise the simulation results of Fig. 11, Fig. 12, Fig. 13, Fig. 14, and Fig. 15 in [1] to reaffirm the validity of the conclusions.