 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Deep Learning with Temporal Data Augmentation for Accurate Remaining Useful Life Prediction of Lithium-Ion Batteries
Mar 28, 2026Accurate prediction of lithium-ion battery remaining useful life (RUL) is essential for reliable health monitoring and data-driven analysis of battery degradation. However, the robustness and generalization capabilities of existing RUL prediction models are significantly challenged by complex operating conditions and limited data availability. To address these limitations, this study proposes a hybrid deep learning model, CDFormer, which integrates convolutional neural networks, deep residual shrinkage networks, and Transformer encoders extract multiscale temporal features from battery measurement signals, including voltage, current, and capacity. This architecture enables the joint modeling of local and global degradation dynamics, effectively improving the accuracy of RUL prediction.To enhance predictive reliability, a composite temporal data augmentation strategy is proposed, incorporating Gaussian noise, time warping, and time resampling, explicitly accounting for measurement noise and variability. CDFormer is evaluated on two real-world datasets, with experimental results demonstrating its consistent superiority over conventional recurrent neural network-based and Transformer-based baselines across key metrics. By improving the reliability and predictive performance of RUL prediction from measurement data, CDFormer provides accurate and reliable forecasts, supporting effective battery health monitoring and data-driven maintenance strategies.
Synchronous Multi-modal Semantic CommunicationSystem with Packet-level Coding
Aug 08, 2024



Although the semantic communication with joint semantic-channel coding design has shown promising performance in transmitting data of different modalities over physical layer channels, the synchronization and packet-level forward error correction of multimodal semantics have not been well studied. Due to the independent design of semantic encoders, synchronizing multimodal features in both the semantic and time domains is a challenging problem. In this paper, we take the facial video and speech transmission as an example and propose a Synchronous Multimodal Semantic Communication System (SyncSC) with Packet-Level Coding. To achieve semantic and time synchronization, 3D Morphable Mode (3DMM) coefficients and text are transmitted as semantics, and we propose a semantic codec that achieves similar quality of reconstruction and synchronization with lower bandwidth, compared to traditional methods. To protect semantic packets under the erasure channel, we propose a packet-Level Forward Error Correction (FEC) method, called PacSC, that maintains a certain visual quality performance even at high packet loss rates. Particularly, for text packets, a text packet loss concealment module, called TextPC, based on Bidirectional Encoder Representations from Transformers (BERT) is proposed, which significantly improves the performance of traditional FEC methods. The simulation results show that our proposed SyncSC reduce transmission overhead and achieve high-quality synchronous transmission of video and speech over the packet loss network.
Inductive Matrix Completion Using Graph Autoencoder
Aug 25, 2021
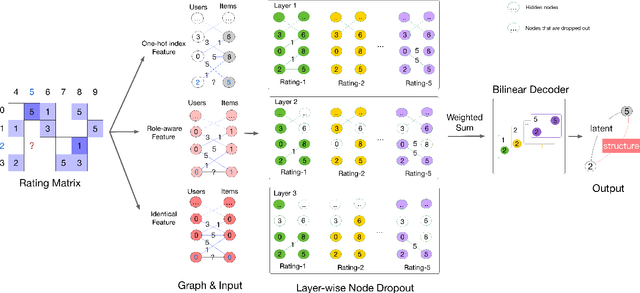

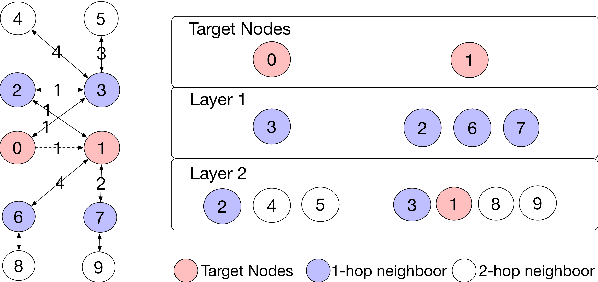
Recently, the graph neural network (GNN) has shown great power in matrix completion by formulating a rating matrix as a bipartite graph and then predicting the link between the corresponding user and item nodes. The majority of GNN-based matrix completion methods are based on Graph Autoencoder (GAE), which considers the one-hot index as input, maps a user (or item) index to a learnable embedding, applies a GNN to learn the node-specific representations based on these learnable embeddings and finally aggregates the representations of the target users and its corresponding item nodes to predict missing links. However, without node content (i.e., side information) for training, the user (or item) specific representation can not be learned in the inductive setting, that is, a model trained on one group of users (or items) cannot adapt to new users (or items). To this end, we propose an inductive matrix completion method using GAE (IMC-GAE), which utilizes the GAE to learn both the user-specific (or item-specific) representation for personalized recommendation and local graph patterns for inductive matrix completion. Specifically, we design two informative node features and employ a layer-wise node dropout scheme in GAE to learn local graph patterns which can be generalized to unseen data. The main contribution of our paper is the capability to efficiently learn local graph patterns in GAE, with good scalability and superior expressiveness compared to previous GNN-based matrix completion methods. Furthermore, extensive experiments demonstrate that our model achieves state-of-the-art performance on several matrix completion benchmarks. Our official code is publicly available.