 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDART: Diffusion-Inspired Speculative Decoding for Fast LLM Inference
Jan 27, 2026Speculative decoding is an effective and lossless approach for accelerating LLM inference. However, existing widely adopted model-based draft designs, such as EAGLE3, improve accuracy at the cost of multi-step autoregressive inference, resulting in high drafting latency and ultimately rendering the drafting stage itself a performance bottleneck. Inspired by diffusion-based large language models (dLLMs), we propose DART, which leverages parallel generation to reduce drafting latency. DART predicts logits for multiple future masked positions in parallel within a single forward pass based on hidden states of the target model, thereby eliminating autoregressive rollouts in the draft model while preserving a lightweight design. Based on these parallel logit predictions, we further introduce an efficient tree pruning algorithm that constructs high-quality draft token trees with N-gram-enforced semantic continuity. DART substantially reduces draft-stage overhead while preserving high draft accuracy, leading to significantly improved end-to-end decoding speed. Experimental results demonstrate that DART achieves a 2.03x--3.44x wall-clock time speedup across multiple datasets, surpassing EAGLE3 by 30% on average and offering a practical speculative decoding framework. Code is released at https://github.com/fvliang/DART.
Reward-Driven Interaction: Enhancing Proactive Dialogue Agents through User Satisfaction Prediction
May 24, 2025Reward-driven proactive dialogue agents require precise estimation of user satisfaction as an intrinsic reward signal to determine optimal interaction strategies. Specifically, this framework triggers clarification questions when detecting potential user dissatisfaction during interactions in the industrial dialogue system. Traditional works typically rely on training a neural network model based on weak labels which are generated by a simple model trained on user actions after current turn. However, existing methods suffer from two critical limitations in real-world scenarios: (1) Noisy Reward Supervision, dependence on weak labels derived from post-hoc user actions introduces bias, particularly failing to capture satisfaction signals in ASR-error-induced utterances; (2) Long-Tail Feedback Sparsity, the power-law distribution of user queries causes reward prediction accuracy to drop in low-frequency domains. The noise in the weak labels and a power-law distribution of user utterances results in that the model is hard to learn good representation of user utterances and sessions. To address these limitations, we propose two auxiliary tasks to improve the representation learning of user utterances and sessions that enhance user satisfaction prediction. The first one is a contrastive self-supervised learning task, which helps the model learn the representation of rare user utterances and identify ASR errors. The second one is a domain-intent classification task, which aids the model in learning the representation of user sessions from long-tailed domains and improving the model's performance on such domains. The proposed method is evaluated on DuerOS, demonstrating significant improvements in the accuracy of error recognition on rare user utterances and long-tailed domains.
DapperFL: Domain Adaptive Federated Learning with Model Fusion Pruning for Edge Devices
Dec 08, 2024Federated learning (FL) has emerged as a prominent machine learning paradigm in edge computing environments, enabling edge devices to collaboratively optimize a global model without sharing their private data. However, existing FL frameworks suffer from efficacy deterioration due to the system heterogeneity inherent in edge computing, especially in the presence of domain shifts across local data. In this paper, we propose a heterogeneous FL framework DapperFL, to enhance model performance across multiple domains. In DapperFL, we introduce a dedicated Model Fusion Pruning (MFP) module to produce personalized compact local models for clients to address the system heterogeneity challenges. The MFP module prunes local models with fused knowledge obtained from both local and remaining domains, ensuring robustness to domain shifts. Additionally, we design a Domain Adaptive Regularization (DAR) module to further improve the overall performance of DapperFL. The DAR module employs regularization generated by the pruned model, aiming to learn robust representations across domains. Furthermore, we introduce a specific aggregation algorithm for aggregating heterogeneous local models with tailored architectures and weights. We implement DapperFL on a realworld FL platform with heterogeneous clients. Experimental results on benchmark datasets with multiple domains demonstrate that DapperFL outperforms several state-of-the-art FL frameworks by up to 2.28%, while significantly achieving model volume reductions ranging from 20% to 80%. Our code is available at: https://github.com/jyzgh/DapperFL.
FedLPS: Heterogeneous Federated Learning for Multiple Tasks with Local Parameter Sharing
Feb 13, 2024Federated Learning (FL) has emerged as a promising solution in Edge Computing (EC) environments to process the proliferation of data generated by edge devices. By collaboratively optimizing the global machine learning models on distributed edge devices, FL circumvents the need for transmitting raw data and enhances user privacy. Despite practical successes, FL still confronts significant challenges including constrained edge device resources, multiple tasks deployment, and data heterogeneity. However, existing studies focus on mitigating the FL training costs of each single task whereas neglecting the resource consumption across multiple tasks in heterogeneous FL scenarios. In this paper, we propose Heterogeneous Federated Learning with Local Parameter Sharing (FedLPS) to fill this gap. FedLPS leverages principles from transfer learning to facilitate the deployment of multiple tasks on a single device by dividing the local model into a shareable encoder and task-specific encoders. To further reduce resource consumption, a channel-wise model pruning algorithm that shrinks the footprint of local models while accounting for both data and system heterogeneity is employed in FedLPS. Additionally, a novel heterogeneous model aggregation algorithm is proposed to aggregate the heterogeneous predictors in FedLPS. We implemented the proposed FedLPS on a real FL platform and compared it with state-of-the-art (SOTA) FL frameworks. The experimental results on five popular datasets and two modern DNN models illustrate that the proposed FedLPS significantly outperforms the SOTA FL frameworks by up to 4.88% and reduces the computational resource consumption by 21.3%. Our code is available at:https://github.com/jyzgh/FedLPS.
OptIForest: Optimal Isolation Forest for Anomaly Detection
Jun 23, 2023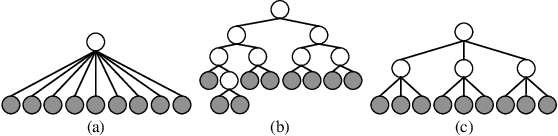
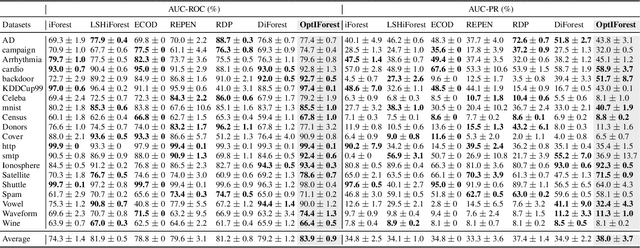
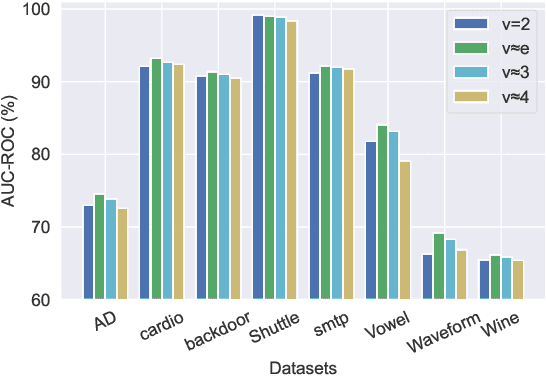
Anomaly detection plays an increasingly important role in various fields for critical tasks such as intrusion detection in cybersecurity, financial risk detection, and human health monitoring. A variety of anomaly detection methods have been proposed, and a category based on the isolation forest mechanism stands out due to its simplicity, effectiveness, and efficiency, e.g., iForest is often employed as a state-of-the-art detector for real deployment. While the majority of isolation forests use the binary structure, a framework LSHiForest has demonstrated that the multi-fork isolation tree structure can lead to better detection performance. However, there is no theoretical work answering the fundamentally and practically important question on the optimal tree structure for an isolation forest with respect to the branching factor. In this paper, we establish a theory on isolation efficiency to answer the question and determine the optimal branching factor for an isolation tree. Based on the theoretical underpinning, we design a practical optimal isolation forest OptIForest incorporating clustering based learning to hash which enables more information to be learned from data for better isolation quality. The rationale of our approach relies on a better bias-variance trade-off achieved by bias reduction in OptIForest. Extensive experiments on a series of benchmarking datasets for comparative and ablation studies demonstrate that our approach can efficiently and robustly achieve better detection performance in general than the state-of-the-arts including the deep learning based methods.
Inductive Matrix Completion Using Graph Autoencoder
Aug 25, 2021
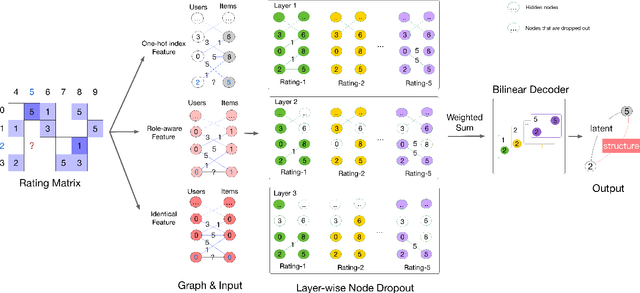

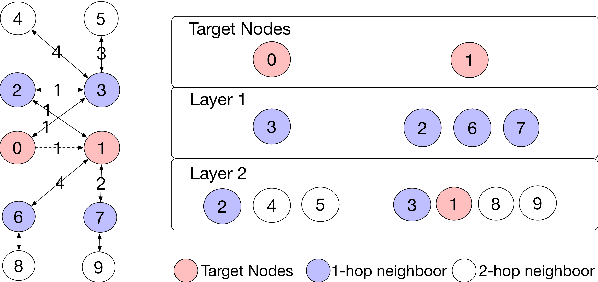
Recently, the graph neural network (GNN) has shown great power in matrix completion by formulating a rating matrix as a bipartite graph and then predicting the link between the corresponding user and item nodes. The majority of GNN-based matrix completion methods are based on Graph Autoencoder (GAE), which considers the one-hot index as input, maps a user (or item) index to a learnable embedding, applies a GNN to learn the node-specific representations based on these learnable embeddings and finally aggregates the representations of the target users and its corresponding item nodes to predict missing links. However, without node content (i.e., side information) for training, the user (or item) specific representation can not be learned in the inductive setting, that is, a model trained on one group of users (or items) cannot adapt to new users (or items). To this end, we propose an inductive matrix completion method using GAE (IMC-GAE), which utilizes the GAE to learn both the user-specific (or item-specific) representation for personalized recommendation and local graph patterns for inductive matrix completion. Specifically, we design two informative node features and employ a layer-wise node dropout scheme in GAE to learn local graph patterns which can be generalized to unseen data. The main contribution of our paper is the capability to efficiently learn local graph patterns in GAE, with good scalability and superior expressiveness compared to previous GNN-based matrix completion methods. Furthermore, extensive experiments demonstrate that our model achieves state-of-the-art performance on several matrix completion benchmarks. Our official code is publicly available.
Auxiliary-task Based Deep Reinforcement Learning for Participant Selection Problem in Mobile Crowdsourcing
Aug 26, 2020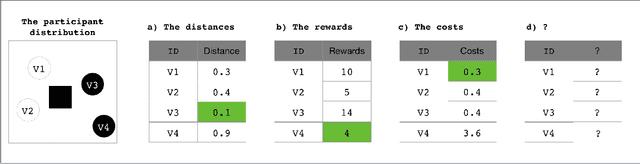

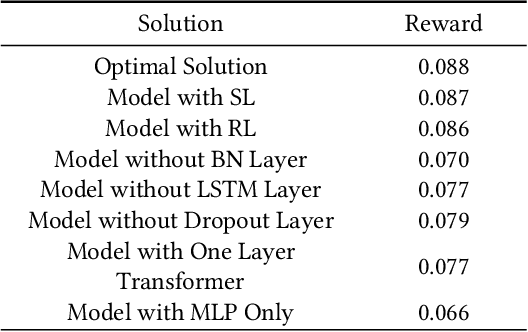
In mobile crowdsourcing (MCS), the platform selects participants to complete location-aware tasks from the recruiters aiming to achieve multiple goals (e.g., profit maximization, energy efficiency, and fairness). However, different MCS systems have different goals and there are possibly conflicting goals even in one MCS system. Therefore, it is crucial to design a participant selection algorithm that applies to different MCS systems to achieve multiple goals. To deal with this issue, we formulate the participant selection problem as a reinforcement learning problem and propose to solve it with a novel method, which we call auxiliary-task based deep reinforcement learning (ADRL). We use transformers to extract representations from the context of the MCS system and a pointer network to deal with the combinatorial optimization problem. To improve the sample efficiency, we adopt an auxiliary-task training process that trains the network to predict the imminent tasks from the recruiters, which facilitates the embedding learning of the deep learning model. Additionally, we release a simulated environment on a specific MCS task, the ride-sharing task, and conduct extensive performance evaluations in this environment. The experimental results demonstrate that ADRL outperforms and improves sample efficiency over other well-recognized baselines in various settings.