 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMTP: Exploring Multimodal Urban Traffic Profiling with Modality Augmentation and Spectrum Fusion
Nov 17, 2025With rapid urbanization in the modern era, traffic signals from various sensors have been playing a significant role in monitoring the states of cities, which provides a strong foundation in ensuring safe travel, reducing traffic congestion and optimizing urban mobility. Most existing methods for traffic signal modeling often rely on the original data modality, i.e., numerical direct readings from the sensors in cities. However, this unimodal approach overlooks the semantic information existing in multimodal heterogeneous urban data in different perspectives, which hinders a comprehensive understanding of traffic signals and limits the accurate prediction of complex traffic dynamics. To address this problem, we propose a novel Multimodal framework, MTP, for urban Traffic Profiling, which learns multimodal features through numeric, visual, and textual perspectives. The three branches drive for a multimodal perspective of urban traffic signal learning in the frequency domain, while the frequency learning strategies delicately refine the information for extraction. Specifically, we first conduct the visual augmentation for the traffic signals, which transforms the original modality into frequency images and periodicity images for visual learning. Also, we augment descriptive texts for the traffic signals based on the specific topic, background information and item description for textual learning. To complement the numeric information, we utilize frequency multilayer perceptrons for learning on the original modality. We design a hierarchical contrastive learning on the three branches to fuse the spectrum of three modalities. Finally, extensive experiments on six real-world datasets demonstrate superior performance compared with the state-of-the-art approaches.
MedGNN: Towards Multi-resolution Spatiotemporal Graph Learning for Medical Time Series Classification
Feb 06, 2025



Medical time series has been playing a vital role in real-world healthcare systems as valuable information in monitoring health conditions of patients. Accurate classification for medical time series, e.g., Electrocardiography (ECG) signals, can help for early detection and diagnosis. Traditional methods towards medical time series classification rely on handcrafted feature extraction and statistical methods; with the recent advancement of artificial intelligence, the machine learning and deep learning methods have become more popular. However, existing methods often fail to fully model the complex spatial dynamics under different scales, which ignore the dynamic multi-resolution spatial and temporal joint inter-dependencies. Moreover, they are less likely to consider the special baseline wander problem as well as the multi-view characteristics of medical time series, which largely hinders their prediction performance. To address these limitations, we propose a Multi-resolution Spatiotemporal Graph Learning framework, MedGNN, for medical time series classification. Specifically, we first propose to construct multi-resolution adaptive graph structures to learn dynamic multi-scale embeddings. Then, to address the baseline wander problem, we propose Difference Attention Networks to operate self-attention mechanisms on the finite difference for temporal modeling. Moreover, to learn the multi-view characteristics, we utilize the Frequency Convolution Networks to capture complementary information of medical time series from the frequency domain. In addition, we introduce the Multi-resolution Graph Transformer architecture to model the dynamic dependencies and fuse the information from different resolutions. Finally, we have conducted extensive experiments on multiple medical real-world datasets that demonstrate the superior performance of our method. Our Code is available.
TAD-Bench: A Comprehensive Benchmark for Embedding-Based Text Anomaly Detection
Jan 21, 2025



Text anomaly detection is crucial for identifying spam, misinformation, and offensive language in natural language processing tasks. Despite the growing adoption of embedding-based methods, their effectiveness and generalizability across diverse application scenarios remain under-explored. To address this, we present TAD-Bench, a comprehensive benchmark designed to systematically evaluate embedding-based approaches for text anomaly detection. TAD-Bench integrates multiple datasets spanning different domains, combining state-of-the-art embeddings from large language models with a variety of anomaly detection algorithms. Through extensive experiments, we analyze the interplay between embeddings and detection methods, uncovering their strengths, weaknesses, and applicability to different tasks. These findings offer new perspectives on building more robust, efficient, and generalizable anomaly detection systems for real-world applications.
Real-time and Downtime-tolerant Fault Diagnosis for Railway Turnout Machines (RTMs) Empowered with Cloud-Edge Pipeline Parallelism
Nov 04, 2024



Railway Turnout Machines (RTMs) are mission-critical components of the railway transportation infrastructure, responsible for directing trains onto desired tracks. For safety assurance applications, especially in early-warning scenarios, RTM faults are expected to be detected as early as possible on a continuous 7x24 basis. However, limited emphasis has been placed on distributed model inference frameworks that can meet the inference latency and reliability requirements of such mission critical fault diagnosis systems. In this paper, an edge-cloud collaborative early-warning system is proposed to enable real-time and downtime-tolerant fault diagnosis of RTMs, providing a new paradigm for the deployment of models in safety-critical scenarios. Firstly, a modular fault diagnosis model is designed specifically for distributed deployment, which utilizes a hierarchical architecture consisting of the prior knowledge module, subordinate classifiers, and a fusion layer for enhanced accuracy and parallelism. Then, a cloud-edge collaborative framework leveraging pipeline parallelism, namely CEC-PA, is developed to minimize the overhead resulting from distributed task execution and context exchange by strategically partitioning and offloading model components across cloud and edge. Additionally, an election consensus mechanism is implemented within CEC-PA to ensure system robustness during coordinator node downtime. Comparative experiments and ablation studies are conducted to validate the effectiveness of the proposed distributed fault diagnosis approach. Our ensemble-based fault diagnosis model achieves a remarkable 97.4% accuracy on a real-world dataset collected by Nanjing Metro in Jiangsu Province, China. Meanwhile, CEC-PA demonstrates superior recovery proficiency during node disruptions and speed-up ranging from 1.98x to 7.93x in total inference time compared to its counterparts.
Anomaly Detection Based on Isolation Mechanisms: A Survey
Mar 16, 2024Anomaly detection is a longstanding and active research area that has many applications in domains such as finance, security, and manufacturing. However, the efficiency and performance of anomaly detection algorithms are challenged by the large-scale, high-dimensional, and heterogeneous data that are prevalent in the era of big data. Isolation-based unsupervised anomaly detection is a novel and effective approach for identifying anomalies in data. It relies on the idea that anomalies are few and different from normal instances, and thus can be easily isolated by random partitioning. Isolation-based methods have several advantages over existing methods, such as low computational complexity, low memory usage, high scalability, robustness to noise and irrelevant features, and no need for prior knowledge or heavy parameter tuning. In this survey, we review the state-of-the-art isolation-based anomaly detection methods, including their data partitioning strategies, anomaly score functions, and algorithmic details. We also discuss some extensions and applications of isolation-based methods in different scenarios, such as detecting anomalies in streaming data, time series, trajectory, and image datasets. Finally, we identify some open challenges and future directions for isolation-based anomaly detection research.
OptIForest: Optimal Isolation Forest for Anomaly Detection
Jun 23, 2023
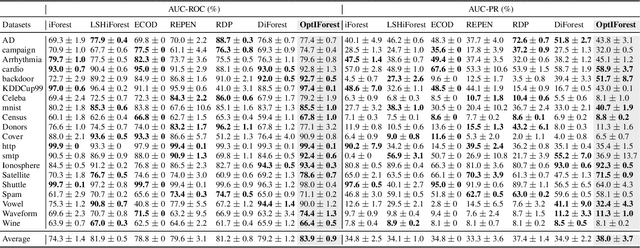
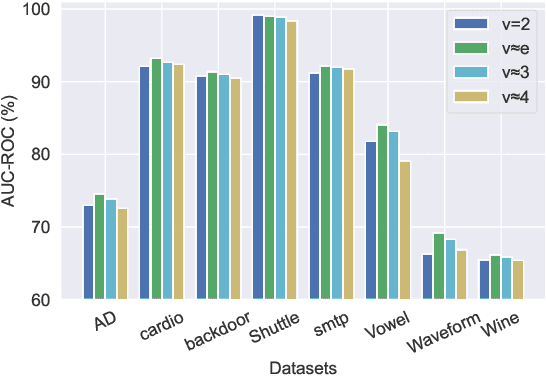
Anomaly detection plays an increasingly important role in various fields for critical tasks such as intrusion detection in cybersecurity, financial risk detection, and human health monitoring. A variety of anomaly detection methods have been proposed, and a category based on the isolation forest mechanism stands out due to its simplicity, effectiveness, and efficiency, e.g., iForest is often employed as a state-of-the-art detector for real deployment. While the majority of isolation forests use the binary structure, a framework LSHiForest has demonstrated that the multi-fork isolation tree structure can lead to better detection performance. However, there is no theoretical work answering the fundamentally and practically important question on the optimal tree structure for an isolation forest with respect to the branching factor. In this paper, we establish a theory on isolation efficiency to answer the question and determine the optimal branching factor for an isolation tree. Based on the theoretical underpinning, we design a practical optimal isolation forest OptIForest incorporating clustering based learning to hash which enables more information to be learned from data for better isolation quality. The rationale of our approach relies on a better bias-variance trade-off achieved by bias reduction in OptIForest. Extensive experiments on a series of benchmarking datasets for comparative and ablation studies demonstrate that our approach can efficiently and robustly achieve better detection performance in general than the state-of-the-arts including the deep learning based methods.