 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRestoring Initial Noise Sensitivity in Text-to-Image Distillation via Geometric Alignment
Jun 01, 2026Generative distillation significantly accelerates text-to-image (T2I) generation by compressing multi-step trajectories into few-step student models while preserving perceptual quality. However, existing methods primarily optimize efficiency and output fidelity, often neglecting critical properties of the original trajectory. In this work, we identify a key missing property: sensitivity to initial noise, whose degradation impairs downstream control methods relying on noise-based optimization and manipulation. We trace this issue to standard distillation objectives that enforce pointwise output alignment, inadvertently flattening the input-output landscape and suppressing the teacher's local geometric structure. To address this, we propose Geometry-Aware Distillation (GAD), a sensitivity-preserving framework that aligns the local functional behavior of teacher and student models. Specifically, GAD matches Jacobian-vector products with respect to input noise, enabling the student to reproduce the teacher's differential response to perturbations. Extensive experiments across multiple T2I paradigms and noise-driven control tasks demonstrate that GAD significantly restores sensitivity and improves diversity while maintaining high visual fidelity. Code is available at https://github.com/Hannah1102/GAD.
Personalized Generative Models for Contextual Debiasing
May 25, 2026Different visual patterns appear with different frequencies in the world: e.g., beach balls appear on sand more often than they do on a road. These statistics are reflected in vision datasets, and as a result trained models more easily recognize objects in common scenarios. However, recognizing a beach ball on a road may arguably be even more important than recognizing it on sand. We study how to mitigate this discrepancy. Since collecting uncommon images in the real world may be difficult, we explore whether generating images with less frequent contexts can serve as effective training augmentation. A key challenge is guiding generations to remain close to the original dataset distribution while creating diverse images with uncommon contexts. We introduce Decoupling Contextual Patterns with Generations (DecoupleGen), a method that personalizes text-to-image diffusion models to facilitate coherent synthesis of images with rare contexts while preserving original visual details. The generated images contain semantically meaningful content and remain visually aligned with the original datasets. We further apply verification constraints to ensure relevance of the augmented data. We evaluate our approach on object classification and recognition tasks on complex scene datasets. Our experiments demonstrate consistent improvements over previous approaches, and our analyses identify factors underlying these improvements.
GASS: Geometry-Aware Spherical Sampling for Disentangled Diversity Enhancement in Text-to-Image Generation
Feb 19, 2026Despite high semantic alignment, modern text-to-image (T2I) generative models still struggle to synthesize diverse images from a given prompt. This lack of diversity not only restricts user choice, but also risks amplifying societal biases. In this work, we enhance the T2I diversity through a geometric lens. Unlike most existing methods that rely primarily on entropy-based guidance to increase sample dissimilarity, we introduce Geometry-Aware Spherical Sampling (GASS) to enhance diversity by explicitly controlling both prompt-dependent and prompt-independent sources of variation. Specifically, we decompose the diversity measure in CLIP embeddings using two orthogonal directions: the text embedding, which captures semantic variation related to the prompt, and an identified orthogonal direction that captures prompt-independent variation (e.g., backgrounds). Based on this decomposition, GASS increases the geometric projection spread of generated image embeddings along both axes and guides the T2I sampling process via expanded predictions along the generation trajectory. Our experiments on different frozen T2I backbones (U-Net and DiT, diffusion and flow) and benchmarks demonstrate the effectiveness of disentangled diversity enhancement with minimal impact on image fidelity and semantic alignment.
PEAR: Pixel-aligned Expressive humAn mesh Recovery
Jan 30, 2026Reconstructing detailed 3D human meshes from a single in-the-wild image remains a fundamental challenge in computer vision. Existing SMPLX-based methods often suffer from slow inference, produce only coarse body poses, and exhibit misalignments or unnatural artifacts in fine-grained regions such as the face and hands. These issues make current approaches difficult to apply to downstream tasks. To address these challenges, we propose PEAR-a fast and robust framework for pixel-aligned expressive human mesh recovery. PEAR explicitly tackles three major limitations of existing methods: slow inference, inaccurate localization of fine-grained human pose details, and insufficient facial expression capture. Specifically, to enable real-time SMPLX parameter inference, we depart from prior designs that rely on high resolution inputs or multi-branch architectures. Instead, we adopt a clean and unified ViT-based model capable of recovering coarse 3D human geometry. To compensate for the loss of fine-grained details caused by this simplified architecture, we introduce pixel-level supervision to optimize the geometry, significantly improving the reconstruction accuracy of fine-grained human details. To make this approach practical, we further propose a modular data annotation strategy that enriches the training data and enhances the robustness of the model. Overall, PEAR is a preprocessing-free framework that can simultaneously infer EHM-s (SMPLX and scaled-FLAME) parameters at over 100 FPS. Extensive experiments on multiple benchmark datasets demonstrate that our method achieves substantial improvements in pose estimation accuracy compared to previous SMPLX-based approaches. Project page: https://wujh2001.github.io/PEAR
Mass Distribution versus Density Distribution in the Context of Clustering
Jan 14, 2026This paper investigates two fundamental descriptors of data, i.e., density distribution versus mass distribution, in the context of clustering. Density distribution has been the de facto descriptor of data distribution since the introduction of statistics. We show that density distribution has its fundamental limitation -- high-density bias, irrespective of the algorithms used to perform clustering. Existing density-based clustering algorithms have employed different algorithmic means to counter the effect of the high-density bias with some success, but the fundamental limitation of using density distribution remains an obstacle to discovering clusters of arbitrary shapes, sizes and densities. Using the mass distribution as a better foundation, we propose a new algorithm which maximizes the total mass of all clusters, called mass-maximization clustering (MMC). The algorithm can be easily changed to maximize the total density of all clusters in order to examine the fundamental limitation of using density distribution versus mass distribution. The key advantage of the MMC over the density-maximization clustering is that the maximization is conducted without a bias towards dense clusters.
MANGO:Natural Multi-speaker 3D Talking Head Generation via 2D-Lifted Enhancement
Jan 05, 2026Current audio-driven 3D head generation methods mainly focus on single-speaker scenarios, lacking natural, bidirectional listen-and-speak interaction. Achieving seamless conversational behavior, where speaking and listening states transition fluidly remains a key challenge. Existing 3D conversational avatar approaches rely on error-prone pseudo-3D labels that fail to capture fine-grained facial dynamics. To address these limitations, we introduce a novel two-stage framework MANGO, which leveraging pure image-level supervision by alternately training to mitigate the noise introduced by pseudo-3D labels, thereby achieving better alignment with real-world conversational behaviors. Specifically, in the first stage, a diffusion-based transformer with a dual-audio interaction module models natural 3D motion from multi-speaker audio. In the second stage, we use a fast 3D Gaussian Renderer to generate high-fidelity images and provide 2D-level photometric supervision for the 3D motions through alternate training. Additionally, we introduce MANGO-Dialog, a high-quality dataset with over 50 hours of aligned 2D-3D conversational data across 500+ identities. Extensive experiments demonstrate that our method achieves exceptional accuracy and realism in modeling two-person 3D dialogue motion, significantly advancing the fidelity and controllability of audio-driven talking heads.
LEMAS: Large A 150K-Hour Large-scale Extensible Multilingual Audio Suite with Generative Speech Models
Jan 04, 2026We present the LEMAS-Dataset, which, to our knowledge, is currently the largest open-source multilingual speech corpus with word-level timestamps. Covering over 150,000 hours across 10 major languages, LEMAS-Dataset is constructed via a efficient data processing pipeline that ensures high-quality data and annotations. To validate the effectiveness of LEMAS-Dataset across diverse generative paradigms, we train two benchmark models with distinct architectures and task specializations on this dataset. LEMAS-TTS, built upon a non-autoregressive flow-matching framework, leverages the dataset's massive scale and linguistic diversity to achieve robust zero-shot multilingual synthesis. Our proposed accent-adversarial training and CTC loss mitigate cross-lingual accent issues, enhancing synthesis stability. Complementarily, LEMAS-Edit employs an autoregressive decoder-only architecture that formulates speech editing as a masked token infilling task. By exploiting precise word-level alignments to construct training masks and adopting adaptive decoding strategies, it achieves seamless, smooth-boundary speech editing with natural transitions. Experimental results demonstrate that models trained on LEMAS-Dataset deliver high-quality synthesis and editing performance, confirming the dataset's quality. We envision that this richly timestamp-annotated, fine-grained multilingual corpus will drive future advances in prompt-based speech generation systems.
D2D: Detector-to-Differentiable Critic for Improved Numeracy in Text-to-Image Generation
Oct 22, 2025
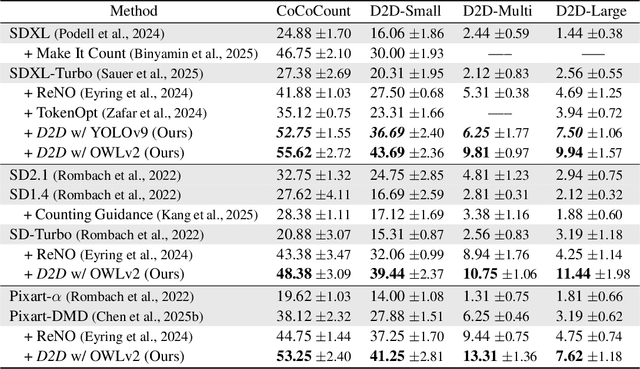
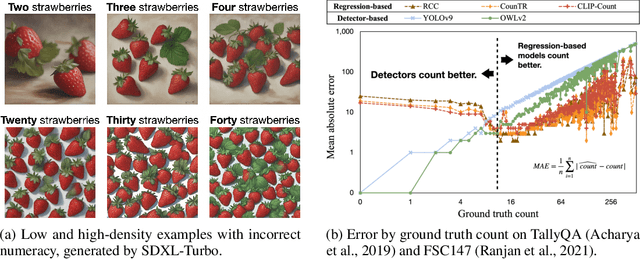
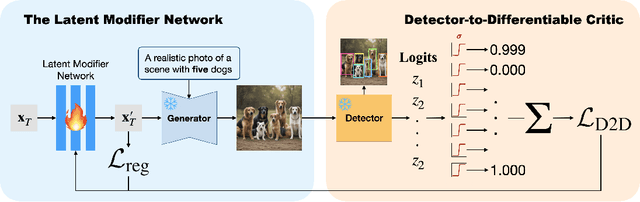
Text-to-image (T2I) diffusion models have achieved strong performance in semantic alignment, yet they still struggle with generating the correct number of objects specified in prompts. Existing approaches typically incorporate auxiliary counting networks as external critics to enhance numeracy. However, since these critics must provide gradient guidance during generation, they are restricted to regression-based models that are inherently differentiable, thus excluding detector-based models with superior counting ability, whose count-via-enumeration nature is non-differentiable. To overcome this limitation, we propose Detector-to-Differentiable (D2D), a novel framework that transforms non-differentiable detection models into differentiable critics, thereby leveraging their superior counting ability to guide numeracy generation. Specifically, we design custom activation functions to convert detector logits into soft binary indicators, which are then used to optimize the noise prior at inference time with pre-trained T2I models. Our extensive experiments on SDXL-Turbo, SD-Turbo, and Pixart-DMD across four benchmarks of varying complexity (low-density, high-density, and multi-object scenarios) demonstrate consistent and substantial improvements in object counting accuracy (e.g., boosting up to 13.7% on D2D-Small, a 400-prompt, low-density benchmark), with minimal degradation in overall image quality and computational overhead.
MelCap: A Unified Single-Codebook Neural Codec for High-Fidelity Audio Compression
Oct 02, 2025Neural audio codecs have recently emerged as powerful tools for high-quality and low-bitrate audio compression, leveraging deep generative models to learn latent representations of audio signals. However, existing approaches either rely on a single quantizer that only processes speech domain, or on multiple quantizers that are not well suited for downstream tasks. To address this issue, we propose MelCap, a unified "one-codebook-for-all" neural codec that effectively handles speech, music, and general sound. By decomposing audio reconstruction into two stages, our method preserves more acoustic details than previous single-codebook approaches, while achieving performance comparable to mainstream multi-codebook methods. In the first stage, audio is transformed into mel-spectrograms, which are compressed and quantized into compact single tokens using a 2D tokenizer. A perceptual loss is further applied to mitigate the over-smoothing artifacts observed in spectrogram reconstruction. In the second stage, a Vocoder recovers waveforms from the mel discrete tokens in a single forward pass, enabling real-time decoding. Both objective and subjective evaluations demonstrate that MelCap achieves quality on comparable to state-of-the-art multi-codebook codecs, while retaining the computational simplicity of a single-codebook design, thereby providing an effective representation for downstream tasks.
CanonSwap: High-Fidelity and Consistent Video Face Swapping via Canonical Space Modulation
Jul 03, 2025Video face swapping aims to address two primary challenges: effectively transferring the source identity to the target video and accurately preserving the dynamic attributes of the target face, such as head poses, facial expressions, lip-sync, \etc. Existing methods mainly focus on achieving high-quality identity transfer but often fall short in maintaining the dynamic attributes of the target face, leading to inconsistent results. We attribute this issue to the inherent coupling of facial appearance and motion in videos. To address this, we propose CanonSwap, a novel video face-swapping framework that decouples motion information from appearance information. Specifically, CanonSwap first eliminates motion-related information, enabling identity modification within a unified canonical space. Subsequently, the swapped feature is reintegrated into the original video space, ensuring the preservation of the target face's dynamic attributes. To further achieve precise identity transfer with minimal artifacts and enhanced realism, we design a Partial Identity Modulation module that adaptively integrates source identity features using a spatial mask to restrict modifications to facial regions. Additionally, we introduce several fine-grained synchronization metrics to comprehensively evaluate the performance of video face swapping methods. Extensive experiments demonstrate that our method significantly outperforms existing approaches in terms of visual quality, temporal consistency, and identity preservation. Our project page are publicly available at https://luoxyhappy.github.io/CanonSwap/.