 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning-Augmented LLM Agents for Collaborative Decision Making and Performance Optimization
Dec 31, 2025Large Language Models (LLMs) perform well in language tasks but often lack collaborative awareness and struggle to optimize global performance in multi-agent settings. We present a reinforcement learning-augmented LLM agent framework that formulates cooperation as a decentralized partially observable Markov decision process (Dec-POMDP) and adopts centralized training with decentralized execution (CTDE). We introduce Group Relative Policy Optimization (GRPO) to jointly optimize agent policies with access to global signals during training, together with a simplified joint reward that balances task quality, speed, and coordination cost. On collaborative writing and coding benchmarks, our framework delivers a 3x increase in task processing speed over single-agent baselines, 98.7% structural/style consistency in writing, and a 74.6% test pass rate in coding. The approach consistently outperforms strong multi-agent LLM baselines and provides a practical path toward reliable collaboration in complex workflows.
Dynamic Diffusion Schrödinger Bridge in Astrophysical Observational Inversions
Jun 11, 2025We study Diffusion Schr\"odinger Bridge (DSB) models in the context of dynamical astrophysical systems, specifically tackling observational inverse prediction tasks within Giant Molecular Clouds (GMCs) for star formation. We introduce the Astro-DSB model, a variant of DSB with the pairwise domain assumption tailored for astrophysical dynamics. By investigating its learning process and prediction performance in both physically simulated data and in real observations (the Taurus B213 data), we present two main takeaways. First, from the astrophysical perspective, our proposed paired DSB method improves interpretability, learning efficiency, and prediction performance over conventional astrostatistical and other machine learning methods. Second, from the generative modeling perspective, probabilistic generative modeling reveals improvements over discriminative pixel-to-pixel modeling in Out-Of-Distribution (OOD) testing cases of physical simulations with unseen initial conditions and different dominant physical processes. Our study expands research into diffusion models beyond the traditional visual synthesis application and provides evidence of the models' learning abilities beyond pure data statistics, paving a path for future physics-aware generative models which can align dynamics between machine learning and real (astro)physical systems.
ImplicitCell: Resolution Cell Modeling of Joint Implicit Volume Reconstruction and Pose Refinement in Freehand 3D Ultrasound
Mar 09, 2025Freehand 3D ultrasound enables volumetric imaging by tracking a conventional ultrasound probe during freehand scanning, offering enriched spatial information that improves clinical diagnosis. However, the quality of reconstructed volumes is often compromised by tracking system noise and irregular probe movements, leading to artifacts in the final reconstruction. To address these challenges, we propose ImplicitCell, a novel framework that integrates Implicit Neural Representation (INR) with an ultrasound resolution cell model for joint optimization of volume reconstruction and pose refinement. Three distinct datasets are used for comprehensive validation, including phantom, common carotid artery, and carotid atherosclerosis. Experimental results demonstrate that ImplicitCell significantly reduces reconstruction artifacts and improves volume quality compared to existing methods, particularly in challenging scenarios with noisy tracking data. These improvements enhance the clinical utility of freehand 3D ultrasound by providing more reliable and precise diagnostic information.
Learning Hidden Subgoals under Temporal Ordering Constraints in Reinforcement Learning
Nov 03, 2024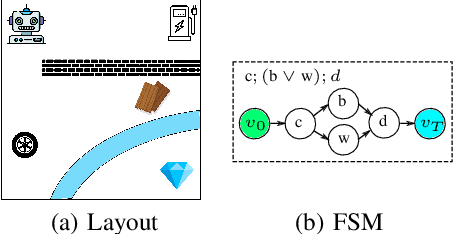

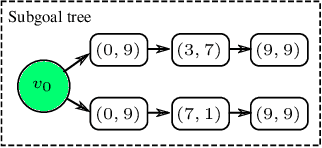
In real-world applications, the success of completing a task is often determined by multiple key steps which are distant in time steps and have to be achieved in a fixed time order. For example, the key steps listed on the cooking recipe should be achieved one-by-one in the right time order. These key steps can be regarded as subgoals of the task and their time orderings are described as temporal ordering constraints. However, in many real-world problems, subgoals or key states are often hidden in the state space and their temporal ordering constraints are also unknown, which make it challenging for previous RL algorithms to solve this kind of tasks. In order to address this issue, in this work we propose a novel RL algorithm for {\bf l}earning hidden {\bf s}ubgoals under {\bf t}emporal {\bf o}rdering {\bf c}onstraints (LSTOC). We propose a new contrastive learning objective which can effectively learn hidden subgoals (key states) and their temporal orderings at the same time, based on first-occupancy representation and temporal geometric sampling. In addition, we propose a sample-efficient learning strategy to discover subgoals one-by-one following their temporal order constraints by building a subgoal tree to represent discovered subgoals and their temporal ordering relationships. Specifically, this tree can be used to improve the sample efficiency of trajectory collection, fasten the task solving and generalize to unseen tasks. The LSTOC framework is evaluated on several environments with image-based observations, showing its significant improvement over baseline methods.
Generalization of Compositional Tasks with Logical Specification via Implicit Planning
Oct 13, 2024



In this work, we study the problem of learning generalizable policies for compositional tasks given by a logic specification. These tasks are composed by temporally extended subgoals. Due to dependencies of subgoals and long task horizon, previous reinforcement learning (RL) algorithms, e.g., task-conditioned and goal-conditioned policies, still suffer from slow convergence and sub-optimality when solving the generalization problem of compositional tasks. In order to tackle these issues, this paper proposes a new hierarchical RL framework for the efficient and optimal generalization of compositional tasks. In the high level, we propose a new implicit planner designed specifically for generalizing compositional tasks. Specifically, the planner produces the selection of next sub-task and estimates the multi-step return of completing the rest of task from current state. It learns a latent transition model and conducts planning in the latent space based on a graph neural network (GNN). Then, the next sub-task selected by the high level guides the low-level agent efficiently to solve long-horizon tasks and the multi-step return makes the low-level policy consider dependencies of future sub-tasks. We conduct comprehensive experiments to show the advantage of proposed framework over previous methods in terms of optimality and efficiency.
LLM-Augmented Symbolic Reinforcement Learning with Landmark-Based Task Decomposition
Oct 02, 2024


One of the fundamental challenges in reinforcement learning (RL) is to take a complex task and be able to decompose it to subtasks that are simpler for the RL agent to learn. In this paper, we report on our work that would identify subtasks by using some given positive and negative trajectories for solving the complex task. We assume that the states are represented by first-order predicate logic using which we devise a novel algorithm to identify the subtasks. Then we employ a Large Language Model (LLM) to generate first-order logic rule templates for achieving each subtask. Such rules were then further fined tuned to a rule-based policy via an Inductive Logic Programming (ILP)-based RL agent. Through experiments, we verify the accuracy of our algorithm in detecting subtasks which successfully detect all of the subtasks correctly. We also investigated the quality of the common-sense rules produced by the language model to achieve the subtasks. Our experiments show that our LLM-guided rule template generation can produce rules that are necessary for solving a subtask, which leads to solving complex tasks with fewer assumptions about predefined first-order logic predicates of the environment.
CityLLaVA: Efficient Fine-Tuning for VLMs in City Scenario
May 06, 2024



In the vast and dynamic landscape of urban settings, Traffic Safety Description and Analysis plays a pivotal role in applications ranging from insurance inspection to accident prevention. This paper introduces CityLLaVA, a novel fine-tuning framework for Visual Language Models (VLMs) designed for urban scenarios. CityLLaVA enhances model comprehension and prediction accuracy through (1) employing bounding boxes for optimal visual data preprocessing, including video best-view selection and visual prompt engineering during both training and testing phases; (2) constructing concise Question-Answer sequences and designing textual prompts to refine instruction comprehension; (3) implementing block expansion to fine-tune large VLMs efficiently; and (4) advancing prediction accuracy via a unique sequential questioning-based prediction augmentation. Demonstrating top-tier performance, our method achieved a benchmark score of 33.4308, securing the leading position on the leaderboard. The code can be found: https://github.com/alibaba/AICITY2024_Track2_AliOpenTrek_CityLLaVA
An Order-Complexity Aesthetic Assessment Model for Aesthetic-aware Music Recommendation
Feb 13, 2024



Computational aesthetic evaluation has made remarkable contribution to visual art works, but its application to music is still rare. Currently, subjective evaluation is still the most effective form of evaluating artistic works. However, subjective evaluation of artistic works will consume a lot of human and material resources. The popular AI generated content (AIGC) tasks nowadays have flooded all industries, and music is no exception. While compared to music produced by humans, AI generated music still sounds mechanical, monotonous, and lacks aesthetic appeal. Due to the lack of music datasets with rating annotations, we have to choose traditional aesthetic equations to objectively measure the beauty of music. In order to improve the quality of AI music generation and further guide computer music production, synthesis, recommendation and other tasks, we use Birkhoff's aesthetic measure to design a aesthetic model, objectively measuring the aesthetic beauty of music, and form a recommendation list according to the aesthetic feeling of music. Experiments show that our objective aesthetic model and recommendation method are effective.
MusicAOG: an Energy-Based Model for Learning and Sampling a Hierarchical Representation of Symbolic Music
Jan 05, 2024In addressing the challenge of interpretability and generalizability of artificial music intelligence, this paper introduces a novel symbolic representation that amalgamates both explicit and implicit musical information across diverse traditions and granularities. Utilizing a hierarchical and-or graph representation, the model employs nodes and edges to encapsulate a broad spectrum of musical elements, including structures, textures, rhythms, and harmonies. This hierarchical approach expands the representability across various scales of music. This representation serves as the foundation for an energy-based model, uniquely tailored to learn musical concepts through a flexible algorithm framework relying on the minimax entropy principle. Utilizing an adapted Metropolis-Hastings sampling technique, the model enables fine-grained control over music generation. A comprehensive empirical evaluation, contrasting this novel approach with existing methodologies, manifests considerable advancements in interpretability and controllability. This study marks a substantial contribution to the fields of music analysis, composition, and computational musicology.
Predicting the Radiation Field of Molecular Clouds using Denoising Diffusion Probabilistic Models
Sep 11, 2023Accurately quantifying the impact of radiation feedback in star formation is challenging. To address this complex problem, we employ deep learning techniques, denoising diffusion probabilistic models (DDPMs), to predict the interstellar radiation field (ISRF) strength based on three-band dust emission at 4.5 \um, 24 \um, and 250 \um. We adopt magnetohydrodynamic simulations from the STARFORGE (STAR FORmation in Gaseous Environments) project that model star formation and giant molecular cloud (GMC) evolution. We generate synthetic dust emission maps matching observed spectral energy distributions in the Monoceros R2 (MonR2) GMC. We train DDPMs to estimate the ISRF using synthetic three-band dust emission. The dispersion between the predictions and true values is within a factor of 0.1 for the test set. We extended our assessment of the diffusion model to include new simulations with varying physical parameters. While there is a consistent offset observed in these out-of-distribution simulations, the model effectively constrains the relative intensity to within a factor of 2. Meanwhile, our analysis reveals weak correlation between the ISRF solely derived from dust temperature and the actual ISRF. We apply our trained model to predict the ISRF in MonR2, revealing a correspondence between intense ISRF, bright sources, and high dust emission, confirming the model's ability to capture ISRF variations. Our model robustly predicts radiation feedback distribution, even in complex, poorly constrained ISRF environments like those influenced by nearby star clusters. However, precise ISRF predictions require an accurate training dataset mirroring the target molecular cloud's unique physical conditions.