 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable AI-assisted Workflow Management for Detector Design Optimization Using Distributed Computing
Mar 31, 2026The Production and Distributed Analysis (PanDA) system, originally developed for the ATLAS experiment at the CERN Large Hadron Collider (LHC), has evolved into a robust platform for orchestrating large-scale workflows across distributed computing resources. Coupled with its intelligent Distributed Dispatch and Scheduling (iDDS) component, PanDA supports AI/ML-driven workflows through a scalable and flexible workflow engine. We present an AI-assisted framework for detector design optimization that integrates multi-objective Bayesian optimization with the PanDA--iDDS workflow engine to coordinate iterative simulations across heterogeneous resources. The framework addresses the challenge of exploring high-dimensional parameter spaces inherent in modern detector design. We demonstrate the framework using benchmark problems and realistic studies of the ePIC and dRICH detectors for the Electron-Ion Collider (EIC). Results show improved automation, scalability, and efficiency in multi-objective optimization. This work establishes a flexible and extensible paradigm for AI-driven detector design and other computationally intensive scientific applications.
Not All Steps are Informative: On the Linearity of LLMs' RLVR Training
Jan 08, 2026Reinforcement learning with verifiable rewards (RLVR) has become a central component of large language model (LLM) post-training. Unlike supervised fine-tuning (SFT), RLVR lets an LLM generate multiple candidate solutions and reinforces those that lead to a verifiably correct final answer. However, in practice, RLVR often requires thousands of training steps to reach strong performance, incurring substantial computation largely attributed to prolonged exploration. In this work, we make a surprising observation: during RLVR, LLMs evolve in a strongly linear manner. Specifically, both model weights and model output log-probabilities exhibit strong linear correlations with RL training steps. This suggests that RLVR predominantly amplifies trends that emerge early in training, rather than continuously discovering new behaviors throughout the entire optimization trajectory. Motivated by this linearity, we investigate whether future model states can be predicted from intermediate checkpoints via extrapolation, avoiding continued expensive training. We show that Weight Extrapolation produces models with performance comparable to standard RL training while requiring significantly less computation. Moreover, Logits Extrapolation consistently outperforms continued RL training on all four benchmarks by extrapolating beyond the step range where RL training remains stable.
Anyprefer: An Agentic Framework for Preference Data Synthesis
Apr 27, 2025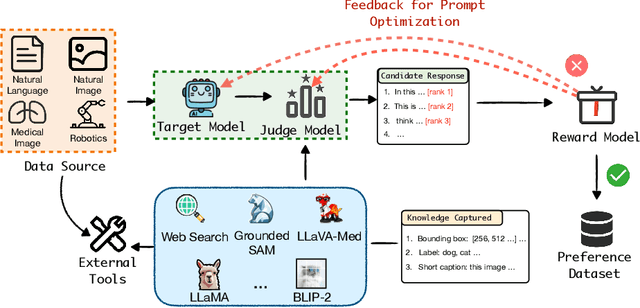
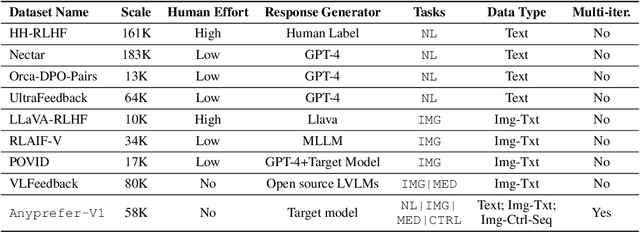
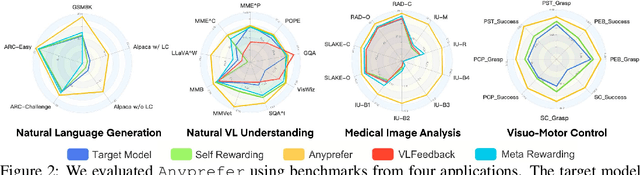
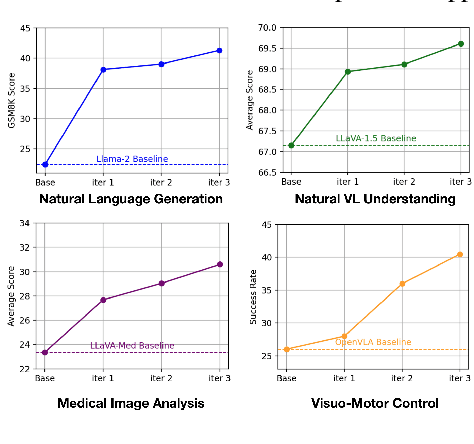
High-quality preference data is essential for aligning foundation models with human values through preference learning. However, manual annotation of such data is often time-consuming and costly. Recent methods often adopt a self-rewarding approach, where the target model generates and annotates its own preference data, but this can lead to inaccuracies since the reward model shares weights with the target model, thereby amplifying inherent biases. To address these issues, we propose Anyprefer, a framework designed to synthesize high-quality preference data for aligning the target model. Anyprefer frames the data synthesis process as a cooperative two-player Markov Game, where the target model and the judge model collaborate together. Here, a series of external tools are introduced to assist the judge model in accurately rewarding the target model's responses, mitigating biases in the rewarding process. In addition, a feedback mechanism is introduced to optimize prompts for both models, enhancing collaboration and improving data quality. The synthesized data is compiled into a new preference dataset, Anyprefer-V1, consisting of 58K high-quality preference pairs. Extensive experiments show that Anyprefer significantly improves model alignment performance across four main applications, covering 21 datasets, achieving average improvements of 18.55% in five natural language generation datasets, 3.66% in nine vision-language understanding datasets, 30.05% in three medical image analysis datasets, and 16.00% in four visuo-motor control tasks.
Scalable Runtime Architecture for Data-driven, Hybrid HPC and ML Workflow Applications
Mar 17, 2025Hybrid workflows combining traditional HPC and novel ML methodologies are transforming scientific computing. This paper presents the architecture and implementation of a scalable runtime system that extends RADICAL-Pilot with service-based execution to support AI-out-HPC workflows. Our runtime system enables distributed ML capabilities, efficient resource management, and seamless HPC/ML coupling across local and remote platforms. Preliminary experimental results show that our approach manages concurrent execution of ML models across local and remote HPC/cloud resources with minimal architectural overheads. This lays the foundation for prototyping three representative data-driven workflow applications and executing them at scale on leadership-class HPC platforms.
Uncertainty-Aware Adaptation of Large Language Models for Protein-Protein Interaction Analysis
Feb 10, 2025



Identification of protein-protein interactions (PPIs) helps derive cellular mechanistic understanding, particularly in the context of complex conditions such as neurodegenerative disorders, metabolic syndromes, and cancer. Large Language Models (LLMs) have demonstrated remarkable potential in predicting protein structures and interactions via automated mining of vast biomedical literature; yet their inherent uncertainty remains a key challenge for deriving reproducible findings, critical for biomedical applications. In this study, we present an uncertainty-aware adaptation of LLMs for PPI analysis, leveraging fine-tuned LLaMA-3 and BioMedGPT models. To enhance prediction reliability, we integrate LoRA ensembles and Bayesian LoRA models for uncertainty quantification (UQ), ensuring confidence-calibrated insights into protein behavior. Our approach achieves competitive performance in PPI identification across diverse disease contexts while addressing model uncertainty, thereby enhancing trustworthiness and reproducibility in computational biology. These findings underscore the potential of uncertainty-aware LLM adaptation for advancing precision medicine and biomedical research.
Open-SQL Framework: Enhancing Text-to-SQL on Open-source Large Language Models
May 04, 2024



Despite the success of large language models (LLMs) in Text-to-SQL tasks, open-source LLMs encounter challenges in contextual understanding and response coherence. To tackle these issues, we present \ours, a systematic methodology tailored for Text-to-SQL with open-source LLMs. Our contributions include a comprehensive evaluation of open-source LLMs in Text-to-SQL tasks, the \openprompt strategy for effective question representation, and novel strategies for supervised fine-tuning. We explore the benefits of Chain-of-Thought in step-by-step inference and propose the \openexample method for enhanced few-shot learning. Additionally, we introduce token-efficient techniques, such as \textbf{Variable-length Open DB Schema}, \textbf{Target Column Truncation}, and \textbf{Example Column Truncation}, addressing challenges in large-scale databases. Our findings emphasize the need for further investigation into the impact of supervised fine-tuning on contextual learning capabilities. Remarkably, our method significantly improved Llama2-7B from 2.54\% to 41.04\% and Code Llama-7B from 14.54\% to 48.24\% on the BIRD-Dev dataset. Notably, the performance of Code Llama-7B surpassed GPT-4 (46.35\%) on the BIRD-Dev dataset.
MusicAOG: an Energy-Based Model for Learning and Sampling a Hierarchical Representation of Symbolic Music
Jan 05, 2024In addressing the challenge of interpretability and generalizability of artificial music intelligence, this paper introduces a novel symbolic representation that amalgamates both explicit and implicit musical information across diverse traditions and granularities. Utilizing a hierarchical and-or graph representation, the model employs nodes and edges to encapsulate a broad spectrum of musical elements, including structures, textures, rhythms, and harmonies. This hierarchical approach expands the representability across various scales of music. This representation serves as the foundation for an energy-based model, uniquely tailored to learn musical concepts through a flexible algorithm framework relying on the minimax entropy principle. Utilizing an adapted Metropolis-Hastings sampling technique, the model enables fine-grained control over music generation. A comprehensive empirical evaluation, contrasting this novel approach with existing methodologies, manifests considerable advancements in interpretability and controllability. This study marks a substantial contribution to the fields of music analysis, composition, and computational musicology.
OMNIINPUT: A Model-centric Evaluation Framework through Output Distribution
Dec 06, 2023



We propose a novel model-centric evaluation framework, OmniInput, to evaluate the quality of an AI/ML model's predictions on all possible inputs (including human-unrecognizable ones), which is crucial for AI safety and reliability. Unlike traditional data-centric evaluation based on pre-defined test sets, the test set in OmniInput is self-constructed by the model itself and the model quality is evaluated by investigating its output distribution. We employ an efficient sampler to obtain representative inputs and the output distribution of the trained model, which, after selective annotation, can be used to estimate the model's precision and recall at different output values and a comprehensive precision-recall curve. Our experiments demonstrate that OmniInput enables a more fine-grained comparison between models, especially when their performance is almost the same on pre-defined datasets, leading to new findings and insights for how to train more robust, generalizable models.
LatticeGen: A Cooperative Framework which Hides Generated Text in a Lattice for Privacy-Aware Generation on Cloud
Oct 02, 2023



In the current user-server interaction paradigm of prompted generation with large language models (LLM) on cloud, the server fully controls the generation process, which leaves zero options for users who want to keep the generated text to themselves. We propose LatticeGen, a cooperative framework in which the server still handles most of the computation while the user controls the sampling operation. The key idea is that the true generated sequence is mixed with noise tokens by the user and hidden in a noised lattice. Considering potential attacks from a hypothetically malicious server and how the user can defend against it, we propose the repeated beam-search attack and the mixing noise scheme. In our experiments we apply LatticeGen to protect both prompt and generation. It is shown that while the noised lattice degrades generation quality, LatticeGen successfully protects the true generation to a remarkable degree under strong attacks (more than 50% of the semantic remains hidden as measured by BERTScore).
SSLRec: A Self-Supervised Learning Library for Recommendation
Aug 10, 2023



Self-supervised learning (SSL) has gained significant interest in recent years as a solution to address the challenges posed by sparse and noisy data in recommender systems. Despite the growing number of SSL algorithms designed to provide state-of-the-art performance in various recommendation scenarios (e.g., graph collaborative filtering, sequential recommendation, social recommendation, KG-enhanced recommendation), there is still a lack of unified frameworks that integrate recommendation algorithms across different domains. Such a framework could serve as the cornerstone for self-supervised recommendation algorithms, unifying the validation of existing methods and driving the design of new ones. To address this gap, we introduce SSLRec, a novel benchmark platform that provides a standardized, flexible, and comprehensive framework for evaluating various SSL-enhanced recommenders. The SSLRec library features a modular architecture that allows users to easily evaluate state-of-the-art models and a complete set of data augmentation and self-supervised toolkits to help create SSL recommendation models with specific needs. Furthermore, SSLRec simplifies the process of training and evaluating different recommendation models with consistent and fair settings. Our SSLRec platform covers a comprehensive set of state-of-the-art SSL-enhanced recommendation models across different scenarios, enabling researchers to evaluate these cutting-edge models and drive further innovation in the field. Our implemented SSLRec framework is available at the source code repository https://github.com/HKUDS/SSLRec.