 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnsemble Knowledge Distillation for Machine Learning Interatomic Potentials
Mar 19, 2025Machine learning interatomic potentials (MLIPs) are a promising tool to accelerate atomistic simulations and molecular property prediction. The quality of MLIPs strongly depends on the quantity of available training data as well as the quantum chemistry (QC) level of theory used to generate that data. Datasets generated with high-fidelity QC methods, such as coupled cluster, are typically restricted to small molecules and may be missing energy gradients. With this limited quantity of data, it is often difficult to train good MLIP models. We present an ensemble knowledge distillation (EKD) method to improve MLIP accuracy when trained to energy-only datasets. In our EKD approach, first, multiple teacher models are trained to QC energies and then used to generate atomic forces for all configurations in the dataset. Next, a student MLIP is trained to both QC energies and to ensemble-averaged forces generated by the teacher models. We apply this workflow on the ANI-1ccx dataset which consists of organic molecules with configuration energies computed at the coupled cluster level of theory. The resulting student MLIPs achieve new state-of-the-art accuracy on the out-of-sample COMP6 benchmark and improved stability for molecular dynamics simulations. The EKD approach for MLIP is broadly applicable for chemical, biomolecular and materials science simulations.
Teacher-student training improves accuracy and efficiency of machine learning inter-atomic potentials
Feb 07, 2025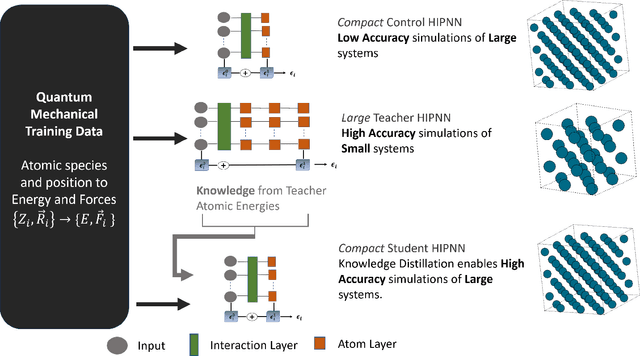

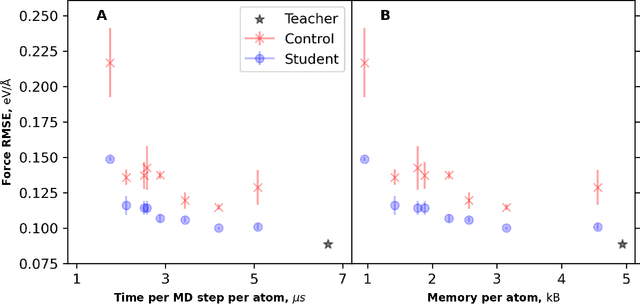
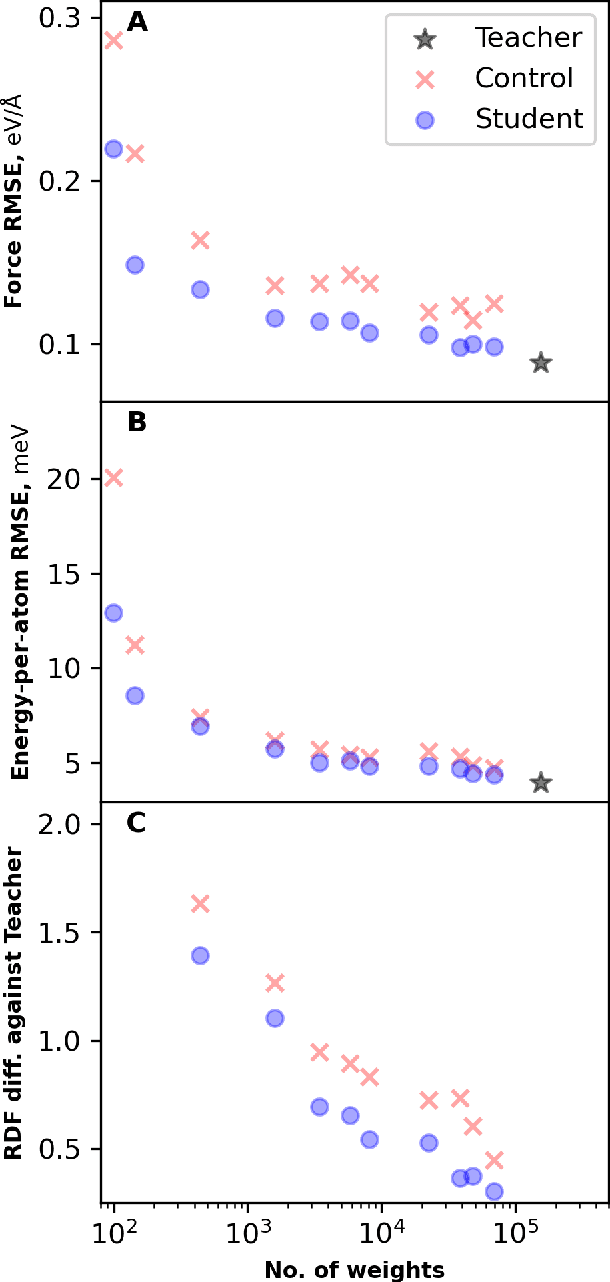
Machine learning inter-atomic potentials (MLIPs) are revolutionizing the field of molecular dynamics (MD) simulations. Recent MLIPs have tended towards more complex architectures trained on larger datasets. The resulting increase in computational and memory costs may prohibit the application of these MLIPs to perform large-scale MD simulations. Here, we present a teacher-student training framework in which the latent knowledge from the teacher (atomic energies) is used to augment the students' training. We show that the light-weight student MLIPs have faster MD speeds at a fraction of the memory footprint compared to the teacher models. Remarkably, the student models can even surpass the accuracy of the teachers, even though both are trained on the same quantum chemistry dataset. Our work highlights a practical method for MLIPs to reduce the resources required for large-scale MD simulations.
Model-diff: A Tool for Comparative Study of Language Models in the Input Space
Dec 13, 2024



Comparing two (large) language models (LMs) side-by-side and pinpointing their prediction similarities and differences on the same set of inputs are crucial in many real-world scenarios, e.g., one can test if a licensed model was potentially plagiarized by another. Traditional analysis compares the LMs' outputs on some benchmark datasets, which only cover a limited number of inputs of designed perspectives for the intended applications. The benchmark datasets cannot prepare data to cover the test cases from unforeseen perspectives which can help us understand differences between models unbiasedly. In this paper, we propose a new model comparative analysis setting that considers a large input space where brute-force enumeration would be infeasible. The input space can be simply defined as all token sequences that a LM would produce low perplexity on -- we follow this definition in the paper as it would produce the most human-understandable inputs. We propose a novel framework \our that uses text generation by sampling and deweights the histogram of sampling statistics to estimate prediction differences between two LMs in this input space efficiently and unbiasedly. Our method achieves this by drawing and counting the inputs at each prediction difference value in negative log-likelihood. Experiments reveal for the first time the quantitative prediction differences between LMs in a large input space, potentially facilitating the model analysis for applications such as model plagiarism.
OMNIINPUT: A Model-centric Evaluation Framework through Output Distribution
Dec 06, 2023



We propose a novel model-centric evaluation framework, OmniInput, to evaluate the quality of an AI/ML model's predictions on all possible inputs (including human-unrecognizable ones), which is crucial for AI safety and reliability. Unlike traditional data-centric evaluation based on pre-defined test sets, the test set in OmniInput is self-constructed by the model itself and the model quality is evaluated by investigating its output distribution. We employ an efficient sampler to obtain representative inputs and the output distribution of the trained model, which, after selective annotation, can be used to estimate the model's precision and recall at different output values and a comprehensive precision-recall curve. Our experiments demonstrate that OmniInput enables a more fine-grained comparison between models, especially when their performance is almost the same on pre-defined datasets, leading to new findings and insights for how to train more robust, generalizable models.
A greedy constructive algorithm for the optimization of neural network architectures
Sep 07, 2019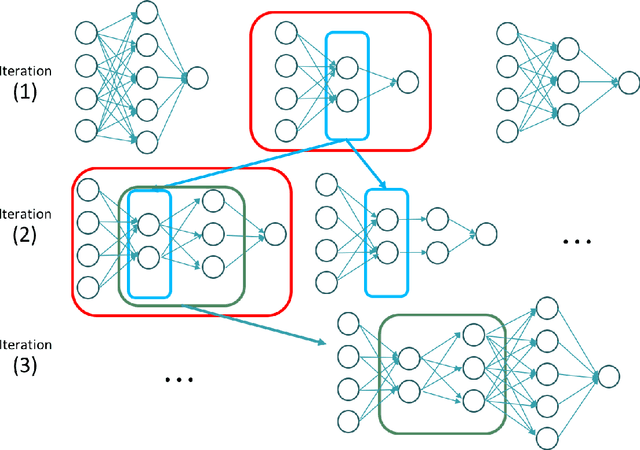

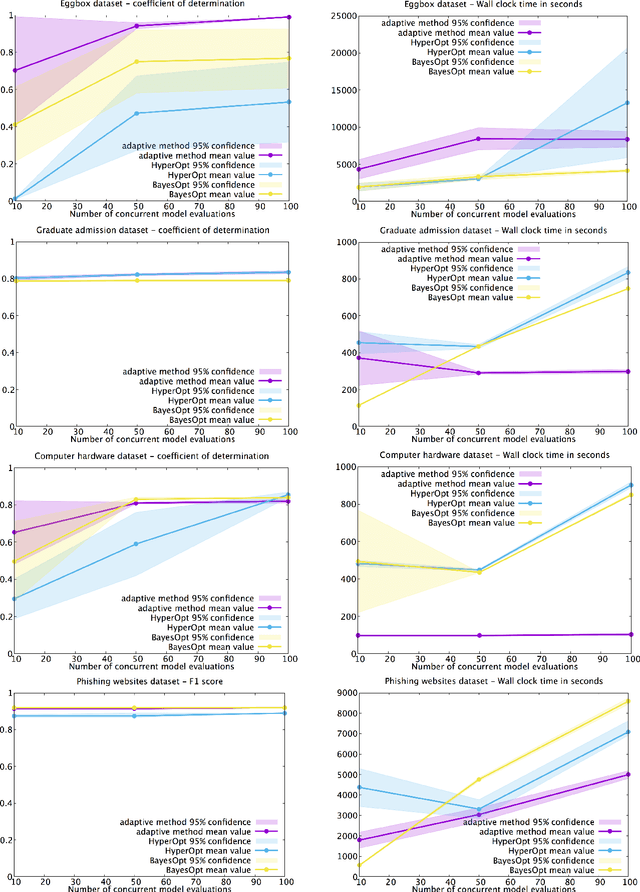
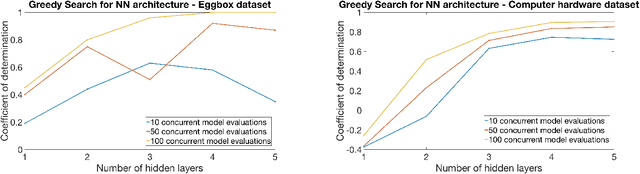
In this work we propose a new method to optimize the architecture of an artificial neural network. The algorithm proposed, called Greedy Search for Neural Network Architecture, aims to minimize the complexity of the architecture search and the complexity of the final model selected without compromising the predictive performance. The reduction of the computational cost makes this approach appealing for two reasons. Firstly, there is a need from domain scientists to easily interpret predictions returned by a deep learning model and this tends to be cumbersome when neural networks have complex structures. Secondly, the use of neural networks is challenging in situations with compute/memory limitations. Promising numerical results show that our method is competitive against other hyperparameter optimization algorithms for attainable performance and computational cost. We also generalize the definition of adjusted score from linear regression models to neural networks. Numerical experiments are presented to show that the adjusted score can boost the greedy search to favor smaller architectures over larger ones without compromising the predictive performance.