 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeacher-student training improves accuracy and efficiency of machine learning inter-atomic potentials
Feb 07, 2025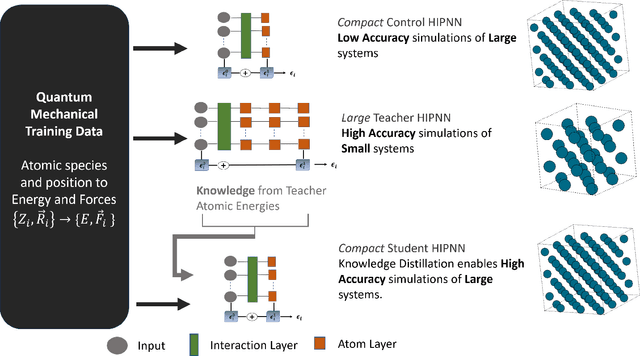

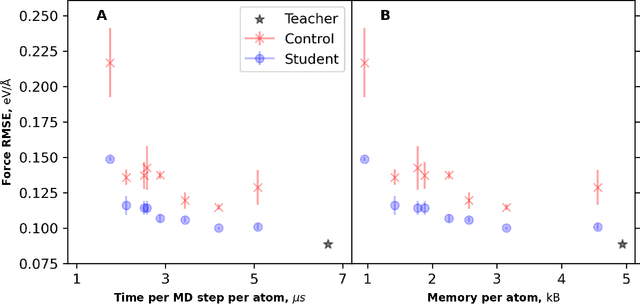
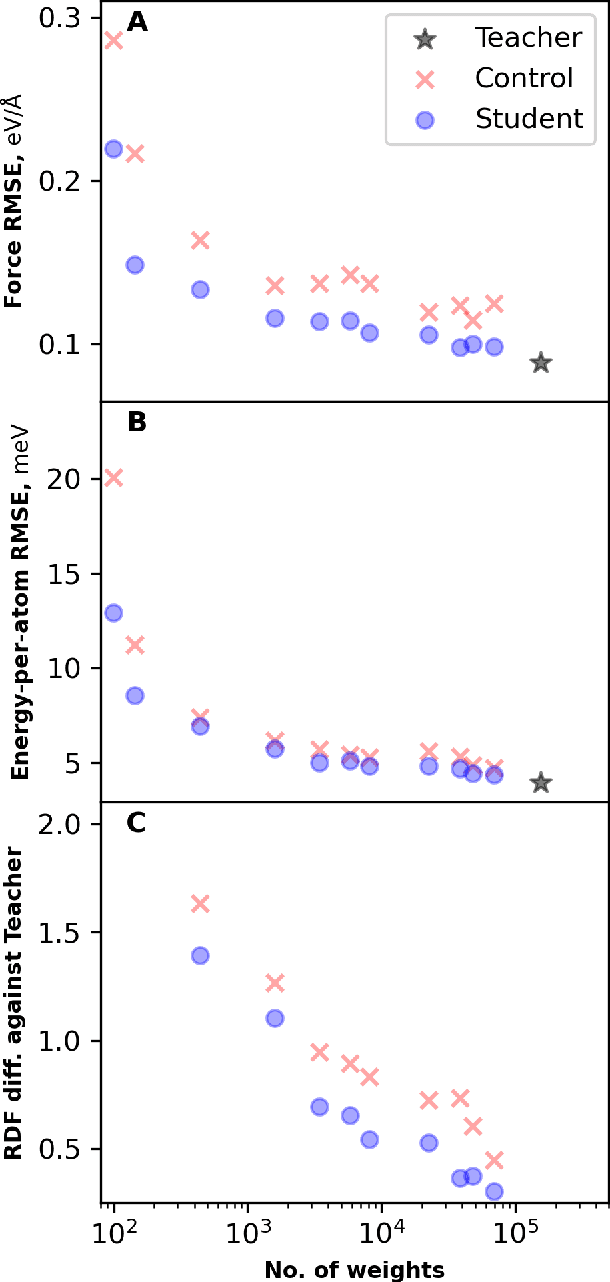
Machine learning inter-atomic potentials (MLIPs) are revolutionizing the field of molecular dynamics (MD) simulations. Recent MLIPs have tended towards more complex architectures trained on larger datasets. The resulting increase in computational and memory costs may prohibit the application of these MLIPs to perform large-scale MD simulations. Here, we present a teacher-student training framework in which the latent knowledge from the teacher (atomic energies) is used to augment the students' training. We show that the light-weight student MLIPs have faster MD speeds at a fraction of the memory footprint compared to the teacher models. Remarkably, the student models can even surpass the accuracy of the teachers, even though both are trained on the same quantum chemistry dataset. Our work highlights a practical method for MLIPs to reduce the resources required for large-scale MD simulations.
Can Language Models Employ the Socratic Method? Experiments with Code Debugging
Oct 04, 2023When employing the Socratic method of teaching, instructors guide students toward solving a problem on their own rather than providing the solution directly. While this strategy can substantially improve learning outcomes, it is usually time-consuming and cognitively demanding. Automated Socratic conversational agents can augment human instruction and provide the necessary scale, however their development is hampered by the lack of suitable data for training and evaluation. In this paper, we introduce a manually created dataset of multi-turn Socratic advice that is aimed at helping a novice programmer fix buggy solutions to simple computational problems. The dataset is then used for benchmarking the Socratic debugging abilities of a number of language models, ranging from fine-tuning the instruction-based text-to-text transformer Flan-T5 to zero-shot and chain of thought prompting of the much larger GPT-4. The code and datasets are made freely available for research at the link below. https://github.com/taisazero/socratic-debugging-benchmark