 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Classification of Pedagogical Materials against CS Curriculum Guidelines
Feb 03, 2026Professional societies often publish curriculum guidelines to help programs align their content to international standards. In Computer Science, the primary standard is published by ACM and IEEE and provide detailed guidelines for what should be and could be included in a Computer Science program. While very helpful, it remains difficult for program administrators to assess how much of the guidelines is being covered by a CS program. This is in particular due to the extensiveness of the guidelines, containing thousands of individual items. As such, it is time consuming and cognitively demanding to audit every course to confidently mark everything that is actually being covered. Our preliminary work indicated that it takes about a day of work per course. In this work, we propose using Natural Language Processing techniques to accelerate the process. We explore two kinds of techniques, the first relying on traditional tools for parsing, tagging, and embeddings, while the second leverages the power of Large Language Models. We evaluate the application of these techniques to classify a corpus of pedagogical materials and show that we can meaningfully classify documents automatically.
Engineering Serendipity through Recommendations of Items with Atypical Aspects
May 29, 2025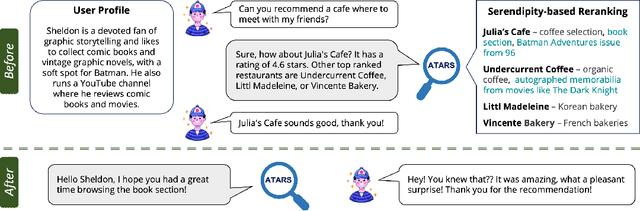
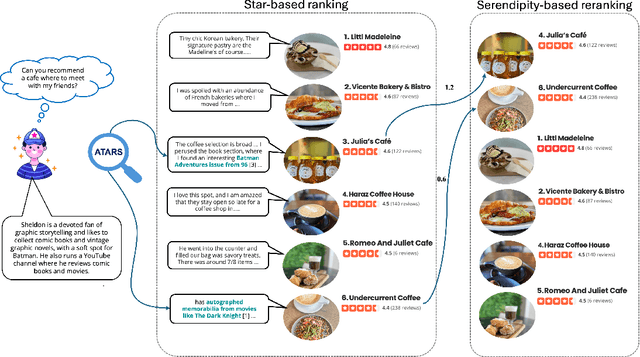

A restaurant dinner or a hotel stay may lead to memorable experiences when guests encounter unexpected aspects that also match their interests. For example, an origami-making station in the waiting area of a restaurant may be both surprising and enjoyable for a customer who is passionate about paper crafts. Similarly, an exhibit of 18th century harpsichords would be atypical for a hotel lobby and likely pique the interest of a guest who has a passion for Baroque music. Motivated by this insight, in this paper we introduce the new task of engineering serendipity through recommendations of items with atypical aspects. We describe an LLM-based system pipeline that extracts atypical aspects from item reviews, then estimates and aggregates their user-specific utility in a measure of serendipity potential that is used to rerank a list of items recommended to the user. To facilitate system development and evaluation, we introduce a dataset of Yelp reviews that are manually annotated with atypical aspects and a dataset of artificially generated user profiles, together with crowdsourced annotations of user-aspect utility values. Furthermore, we introduce a custom procedure for dynamic selection of in-context learning examples, which is shown to improve LLM-based judgments of atypicality and utility. Experimental evaluations show that serendipity-based rankings generated by the system are highly correlated with ground truth rankings for which serendipity scores are computed from manual annotations of atypical aspects and their user-dependent utility. Overall, we hope that the new recommendation task and the associated system presented in this paper catalyze further research into recommendation approaches that go beyond accuracy in their pursuit of enhanced user satisfaction. The datasets and the code are made publicly available at https://github.com/ramituncc49er/ATARS .
Leveraging Descriptions of Emotional Preferences in Recommender Systems
May 26, 2025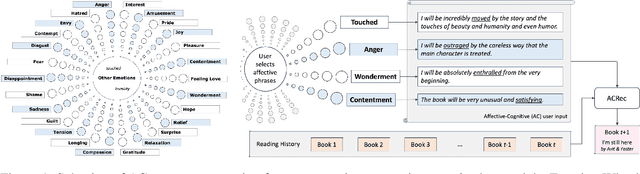
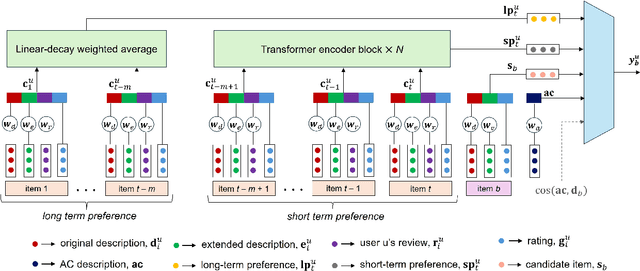

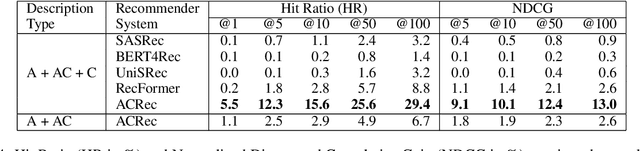
The affective attitude of liking a recommended item reflects just one category in a wide spectrum of affective phenomena that also includes emotions such as entranced or intrigued, moods such as cheerful or buoyant, as well as more fine-grained affective states, such as "pleasantly surprised by the conclusion". In this paper, we introduce a novel recommendation task that can leverage a virtually unbounded range of affective states sought explicitly by the user in order to identify items that, upon consumption, are likely to induce those affective states. Correspondingly, we create a large dataset of user preferences containing expressions of fine-grained affective states that are mined from book reviews, and propose a Transformer-based architecture that leverages such affective expressions as input. We then use the resulting dataset of affective states preferences, together with the linked users and their histories of book readings, ratings, and reviews, to train and evaluate multiple recommendation models on the task of matching recommended items with affective preferences. Experiments show that the best results are obtained by models that can utilize textual descriptions of items and user affective preferences.
Algorithmic Strategies for Sustainable Reuse of Neural Network Accelerators with Permanent Faults
Dec 17, 2024



Hardware failures are a growing challenge for machine learning accelerators, many of which are based on systolic arrays. When a permanent hardware failure occurs in a systolic array, existing solutions include localizing and isolating the faulty processing element (PE), using a redundant PE for re-execution, or in some extreme cases decommissioning the entire accelerator for further investigation. In this paper, we propose novel algorithmic approaches that mitigate permanent hardware faults in neural network (NN) accelerators by uniquely integrating the behavior of the faulty component instead of bypassing it. In doing so, we aim for a more sustainable use of the accelerator where faulty hardware is neither bypassed nor discarded, instead being given a second life. We first introduce a CUDA-accelerated systolic array simulator in PyTorch, which enabled us to quantify the impact of permanent faults appearing on links connecting two PEs or in weight registers, where one bit is stuck at 0 or 1 in the float32, float16, or bfloat16 representation. We then propose several algorithmic mitigation techniques for a subset of stuck-at faults, such as Invertible Scaling or Shifting of activations and weights, or fine tuning with the faulty behavior. Notably, the proposed techniques do not require any hardware modification, instead relying on existing components of widely used systolic array based accelerators, such as normalization, activation, and storage units. Extensive experimental evaluations using fully connected and convolutional NNs trained on MNIST, CIFAR-10 and ImageNet show that the proposed fault-tolerant approach matches or gets very close to the original fault-free accuracy.
Extraction of Atypical Aspects from Customer Reviews: Datasets and Experiments with Language Models
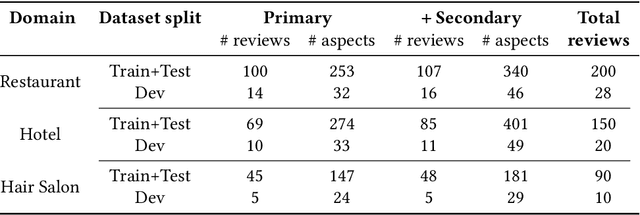
Nov 05, 2023A restaurant dinner may become a memorable experience due to an unexpected aspect enjoyed by the customer, such as an origami-making station in the waiting area. If aspects that are atypical for a restaurant experience were known in advance, they could be leveraged to make recommendations that have the potential to engender serendipitous experiences, further increasing user satisfaction. Although relatively rare, whenever encountered, atypical aspects often end up being mentioned in reviews due to their memorable quality. Correspondingly, in this paper we introduce the task of detecting atypical aspects in customer reviews. To facilitate the development of extraction models, we manually annotate benchmark datasets of reviews in three domains - restaurants, hotels, and hair salons, which we use to evaluate a number of language models, ranging from fine-tuning the instruction-based text-to-text transformer Flan-T5 to zero-shot and few-shot prompting of GPT-3.5.
Can Language Models Employ the Socratic Method? Experiments with Code Debugging
Oct 04, 2023When employing the Socratic method of teaching, instructors guide students toward solving a problem on their own rather than providing the solution directly. While this strategy can substantially improve learning outcomes, it is usually time-consuming and cognitively demanding. Automated Socratic conversational agents can augment human instruction and provide the necessary scale, however their development is hampered by the lack of suitable data for training and evaluation. In this paper, we introduce a manually created dataset of multi-turn Socratic advice that is aimed at helping a novice programmer fix buggy solutions to simple computational problems. The dataset is then used for benchmarking the Socratic debugging abilities of a number of language models, ranging from fine-tuning the instruction-based text-to-text transformer Flan-T5 to zero-shot and chain of thought prompting of the much larger GPT-4. The code and datasets are made freely available for research at the link below. https://github.com/taisazero/socratic-debugging-benchmark
Topic-Level Bayesian Surprise and Serendipity for Recommender Systems
Aug 11, 2023A recommender system that optimizes its recommendations solely to fit a user's history of ratings for consumed items can create a filter bubble, wherein the user does not get to experience items from novel, unseen categories. One approach to mitigate this undesired behavior is to recommend items with high potential for serendipity, namely surprising items that are likely to be highly rated. In this paper, we propose a content-based formulation of serendipity that is rooted in Bayesian surprise and use it to measure the serendipity of items after they are consumed and rated by the user. When coupled with a collaborative-filtering component that identifies similar users, this enables recommending items with high potential for serendipity. To facilitate the evaluation of topic-level models for surprise and serendipity, we introduce a dataset of book reading histories extracted from Goodreads, containing over 26 thousand users and close to 1.3 million books, where we manually annotate 449 books read by 4 users in terms of their time-dependent, topic-level surprise. Experimental evaluations show that models that use Bayesian surprise correlate much better with the manual annotations of topic-level surprise than distance-based heuristics, and also obtain better serendipitous item recommendation performance.
Reclaimer: A Reinforcement Learning Approach to Dynamic Resource Allocation for Cloud Microservices
Apr 17, 2023Many cloud applications are migrated from the monolithic model to a microservices framework in which hundreds of loosely-coupled microservices run concurrently, with significant benefits in terms of scalability, rapid development, modularity, and isolation. However, dependencies among microservices with uneven execution time may result in longer queues, idle resources, or Quality-of-Service (QoS) violations. In this paper we introduce Reclaimer, a deep reinforcement learning model that adapts to runtime changes in the number and behavior of microservices in order to minimize CPU core allocation while meeting QoS requirements. When evaluated with two benchmark microservice-based applications, Reclaimer reduces the mean CPU core allocation by 38.4% to 74.4% relative to the industry-standard scaling solution, and by 27.5% to 58.1% relative to a current state-of-the art method.
LSTMs and Deep Residual Networks for Carbohydrate and Bolus Recommendations in Type 1 Diabetes Management
Mar 06, 2021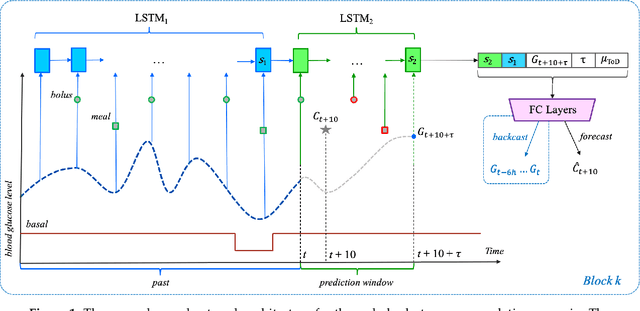
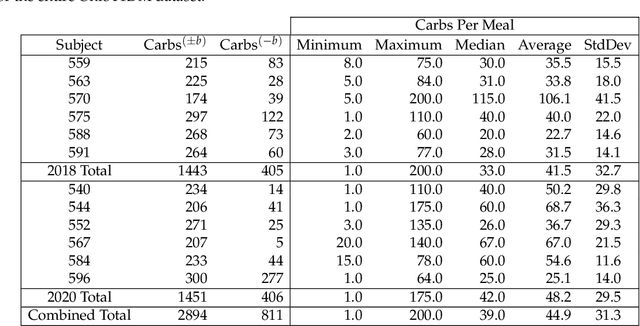
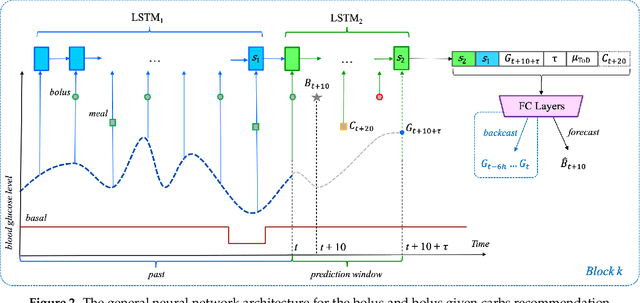
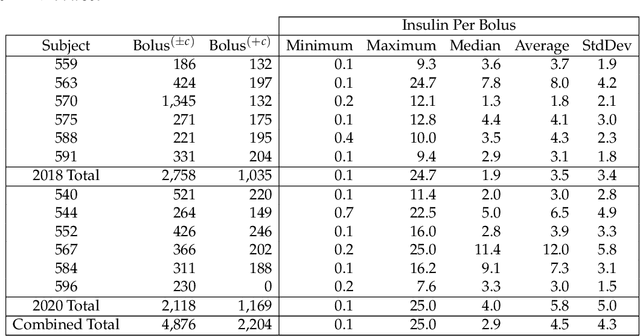
To avoid serious diabetic complications, people with type 1 diabetes must keep their blood glucose levels (BGLs) as close to normal as possible. Insulin dosages and carbohydrate consumption are important considerations in managing BGLs. Since the 1960s, models have been developed to forecast blood glucose levels based on the history of BGLs, insulin dosages, carbohydrate intake, and other physiological and lifestyle factors. Such predictions can be used to alert people of impending unsafe BGLs or to control insulin flow in an artificial pancreas. In past work, we have introduced an LSTM-based approach to blood glucose level prediction aimed at "what if" scenarios, in which people could enter foods they might eat or insulin amounts they might take and then see the effect on future BGLs. In this work, we invert the "what-if" scenario and introduce a similar architecture based on chaining two LSTMs that can be trained to make either insulin or carbohydrate recommendations aimed at reaching a desired BG level in the future. Leveraging a recent state-of-the-art model for time series forecasting, we then derive a novel architecture for the same recommendation task, in which the two LSTM chain is used as a repeating block inside a deep residual architecture. Experimental evaluations using real patient data from the OhioT1DM dataset show that the new integrated architecture compares favorably with the previous LSTM-based approach, substantially outperforming the baselines. The promising results suggest that this novel approach could potentially be of practical use to people with type 1 diabetes for self-management of BGLs.
Changing the Narrative Perspective: From Deictic to Anaphoric Point of View
Mar 06, 2021
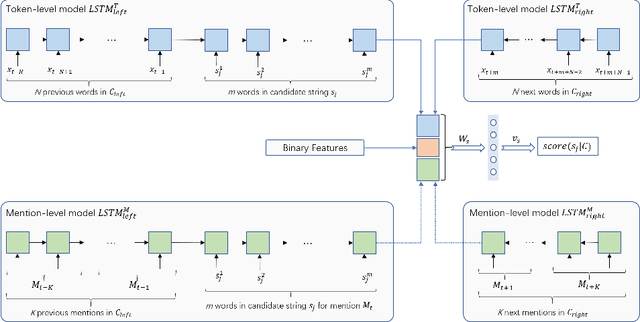
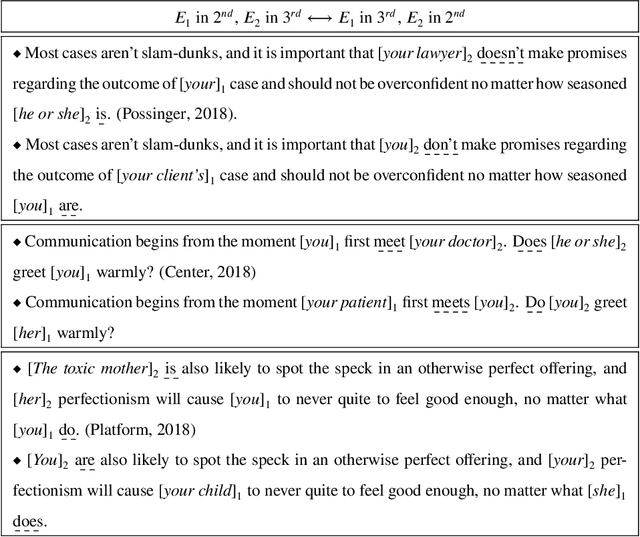
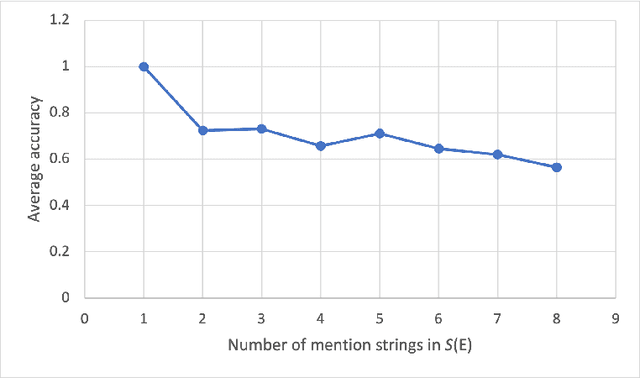
We introduce the task of changing the narrative point of view, where characters are assigned a narrative perspective that is different from the one originally used by the writer. The resulting shift in the narrative point of view alters the reading experience and can be used as a tool in fiction writing or to generate types of text ranging from educational to self-help and self-diagnosis. We introduce a benchmark dataset containing a wide range of types of narratives annotated with changes in point of view from deictic (first or second person) to anaphoric (third person) and describe a pipeline for processing raw text that relies on a neural architecture for mention selection. Evaluations on the new benchmark dataset show that the proposed architecture substantially outperforms the baselines by generating mentions that are less ambiguous and more natural.