 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-in-the-loop model explanation via verbatim boundary identification in generated neighborhoods
Jun 24, 2021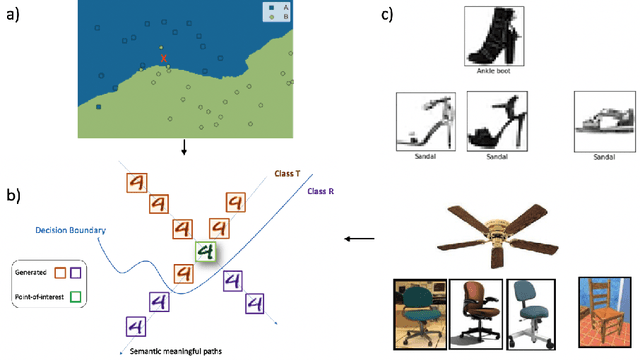
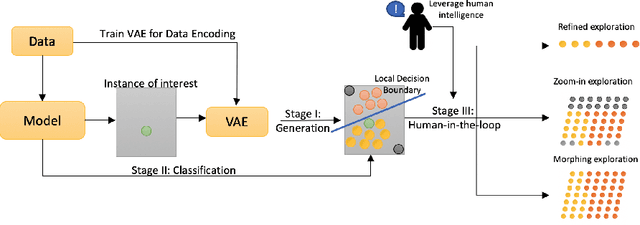

The black-box nature of machine learning models limits their use in case-critical applications, raising faithful and ethical concerns that lead to trust crises. One possible way to mitigate this issue is to understand how a (mispredicted) decision is carved out from the decision boundary. This paper presents a human-in-the-loop approach to explain machine learning models using verbatim neighborhood manifestation. Contrary to most of the current eXplainable Artificial Intelligence (XAI) systems, which provide hit-or-miss approximate explanations, our approach generates the local decision boundary of the given instance and enables human intelligence to conclude the model behavior. Our method can be divided into three stages: 1) a neighborhood generation stage, which generates instances based on the given sample; 2) a classification stage, which yields classifications on the generated instances to carve out the local decision boundary and delineate the model behavior; and 3) a human-in-the-loop stage, which involves human to refine and explore the neighborhood of interest. In the generation stage, a generative model is used to generate the plausible synthetic neighbors around the given instance. After the classification stage, the classified neighbor instances provide a multifaceted understanding of the model behavior. Three intervention points are provided in the human-in-the-loop stage, enabling humans to leverage their own intelligence to interpret the model behavior. Several experiments on two datasets are conducted, and the experimental results demonstrate the potential of our proposed approach for boosting human understanding of the complex machine learning model.
LSTMs and Deep Residual Networks for Carbohydrate and Bolus Recommendations in Type 1 Diabetes Management
Mar 06, 2021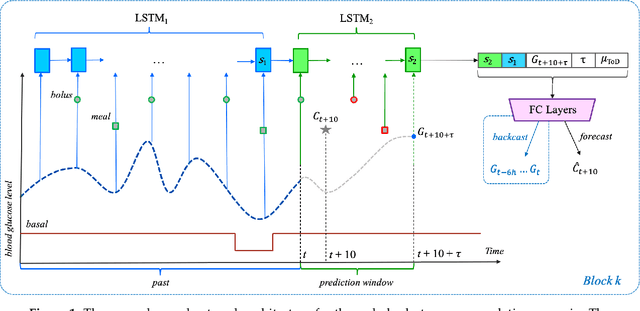
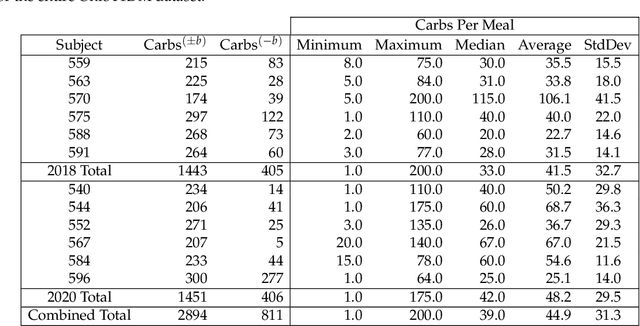
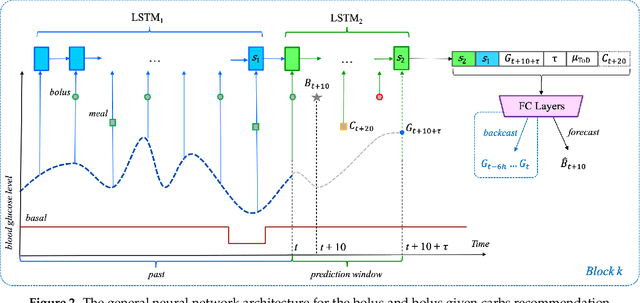
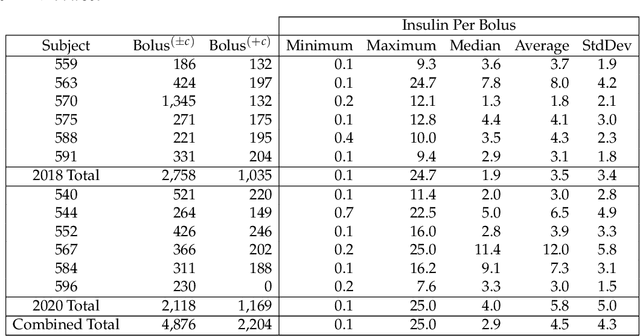
To avoid serious diabetic complications, people with type 1 diabetes must keep their blood glucose levels (BGLs) as close to normal as possible. Insulin dosages and carbohydrate consumption are important considerations in managing BGLs. Since the 1960s, models have been developed to forecast blood glucose levels based on the history of BGLs, insulin dosages, carbohydrate intake, and other physiological and lifestyle factors. Such predictions can be used to alert people of impending unsafe BGLs or to control insulin flow in an artificial pancreas. In past work, we have introduced an LSTM-based approach to blood glucose level prediction aimed at "what if" scenarios, in which people could enter foods they might eat or insulin amounts they might take and then see the effect on future BGLs. In this work, we invert the "what-if" scenario and introduce a similar architecture based on chaining two LSTMs that can be trained to make either insulin or carbohydrate recommendations aimed at reaching a desired BG level in the future. Leveraging a recent state-of-the-art model for time series forecasting, we then derive a novel architecture for the same recommendation task, in which the two LSTM chain is used as a repeating block inside a deep residual architecture. Experimental evaluations using real patient data from the OhioT1DM dataset show that the new integrated architecture compares favorably with the previous LSTM-based approach, substantially outperforming the baselines. The promising results suggest that this novel approach could potentially be of practical use to people with type 1 diabetes for self-management of BGLs.