 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimilar Data Points Identification with LLM: A Human-in-the-loop Strategy Using Summarization and Hidden State Insights
Apr 03, 2024This study introduces a simple yet effective method for identifying similar data points across non-free text domains, such as tabular and image data, using Large Language Models (LLMs). Our two-step approach involves data point summarization and hidden state extraction. Initially, data is condensed via summarization using an LLM, reducing complexity and highlighting essential information in sentences. Subsequently, the summarization sentences are fed through another LLM to extract hidden states, serving as compact, feature-rich representations. This approach leverages the advanced comprehension and generative capabilities of LLMs, offering a scalable and efficient strategy for similarity identification across diverse datasets. We demonstrate the effectiveness of our method in identifying similar data points on multiple datasets. Additionally, our approach enables non-technical domain experts, such as fraud investigators or marketing operators, to quickly identify similar data points tailored to specific scenarios, demonstrating its utility in practical applications. In general, our results open new avenues for leveraging LLMs in data analysis across various domains.
Human-in-the-loop model explanation via verbatim boundary identification in generated neighborhoods
Jun 24, 2021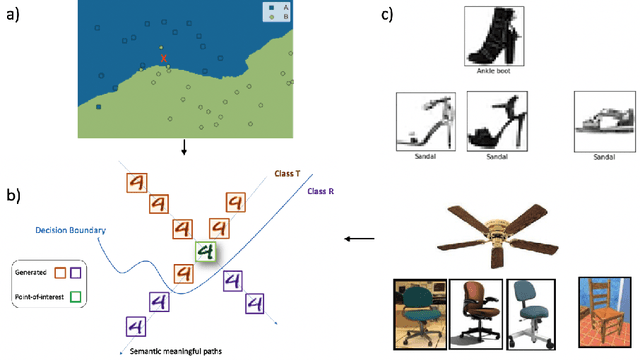
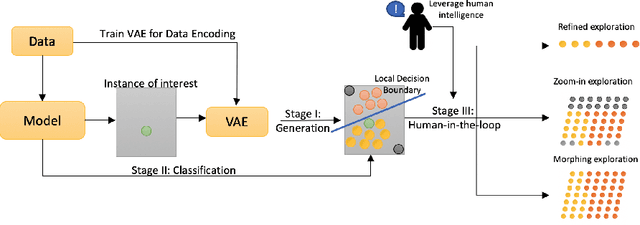

The black-box nature of machine learning models limits their use in case-critical applications, raising faithful and ethical concerns that lead to trust crises. One possible way to mitigate this issue is to understand how a (mispredicted) decision is carved out from the decision boundary. This paper presents a human-in-the-loop approach to explain machine learning models using verbatim neighborhood manifestation. Contrary to most of the current eXplainable Artificial Intelligence (XAI) systems, which provide hit-or-miss approximate explanations, our approach generates the local decision boundary of the given instance and enables human intelligence to conclude the model behavior. Our method can be divided into three stages: 1) a neighborhood generation stage, which generates instances based on the given sample; 2) a classification stage, which yields classifications on the generated instances to carve out the local decision boundary and delineate the model behavior; and 3) a human-in-the-loop stage, which involves human to refine and explore the neighborhood of interest. In the generation stage, a generative model is used to generate the plausible synthetic neighbors around the given instance. After the classification stage, the classified neighbor instances provide a multifaceted understanding of the model behavior. Three intervention points are provided in the human-in-the-loop stage, enabling humans to leverage their own intelligence to interpret the model behavior. Several experiments on two datasets are conducted, and the experimental results demonstrate the potential of our proposed approach for boosting human understanding of the complex machine learning model.